【Redis的那些事 · 續集】Redis的點陣圖、HyperLogLog數據結構演示以及布隆過濾器
一、Redis點陣圖
1、點陣圖的最小單位是bit,每個bit的值只能是0和1,點陣圖的應用場景一般用於一些簽到記錄,例如打卡等。
場景舉例: 例如某APP要存儲用戶的打卡記錄,如果按照正常的思路來做,可能是用戶每天是否打卡的記錄都單獨設置一個key-value鍵值對來存儲,這樣的話,每個用戶每天都需要耗費一個鍵值對空間。而如果是點陣圖,就可以很方便地通過點陣圖來進行記錄,例如如下圖:

點陣圖不算基礎數據結構或者特殊數據結構,其本質上還是字元串。由於每個bit代表一個數據,所以還可以當作是bit數組來看待。
2、可以通過命令:
setbit key 偏移量(索引位) value(0/1,默認是0)
進行設置對應位置的點陣圖數據。
通過命令:
getbit key 偏移量
可以獲取到對應的點陣圖索引數據。
也可以通過:
get key
來獲取點陣圖對應的字元串資訊。
3、例如hello字元串的ascii碼對應的二進位,分別是:
h: 01101000
e: 01100101
l: 01101100
l: 01101100
o: 01101111
以下設置字元串hello的點陣圖操作,如圖所示,字元串對應二進位數拼接起來的二進位,值為1所在的bit索引位(offset),使用:
setbit key offset 1
進行設置1即可。
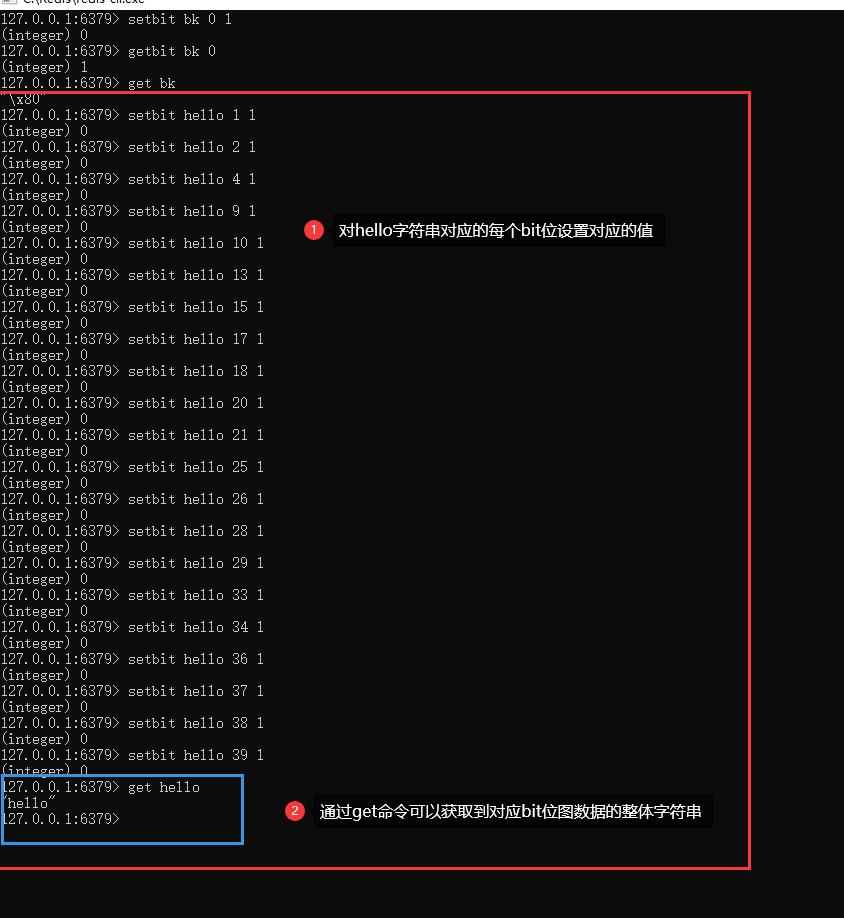
setbit/gitbit 和 set/get 實際上是可以互相轉換的,只是一種是操作bit位,一種是操作直接的值。同時可以互相交叉操作使用,例如setbit存儲,get讀取;set 存儲,getbit讀取等等。
4、可以通過命令: bitcount key 起始字元索引 結束字元索引
對指定key裡面的數據,指定的字元索引區間內,獲取到對應的點陣圖數據是1的個數。如果不指定,則會獲取到全部字元串對應點陣圖的1的個數。如下圖所示,結合以上二進位數據可知,h字元有3個1,o字元有6個1。
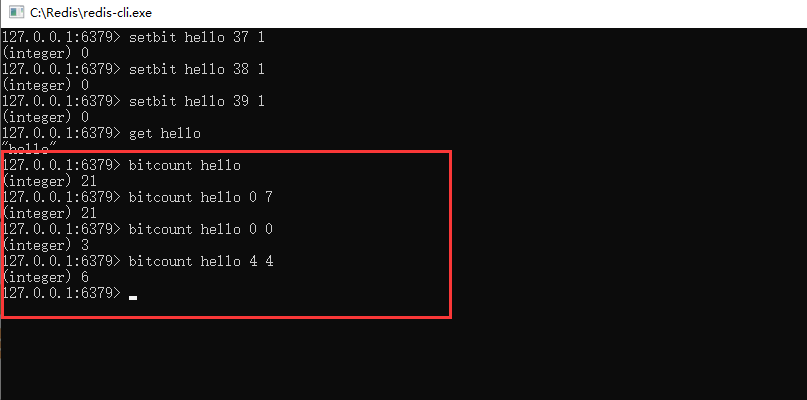
以上指令操作可以適用於在類似打卡天數統計上使用,可以快速統計出區間內為1的數據個數。
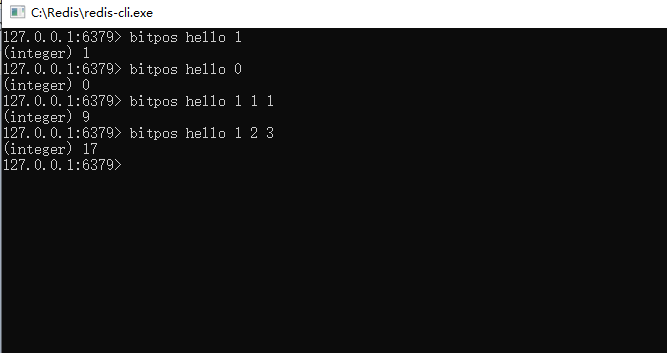
5、通過命令:bitops key bit值(0/1) 起始字元索引 結束字元索引
可以獲取到指定的區間內,第一次出現指定的bit值(0或1)所在的點陣圖索引。如果不指定區間,默認代表字元串全部區間。如下圖所示,hello裡面,第一次出現1是在點陣圖的第一個索引位置;第一次出現0是在第0個點陣圖索引位;字元索引位為1代表第二個字元,第一次出現的值為1的點陣圖索引位置為9。
注意: 字元串的索引,0到N,0代表第一個字元,例如』h』。點陣圖的索引,也是0到N,0代表點陣圖上面第一個bit位,值為0或者1,例如h的點陣圖索引位置是0的值是0 (01101000)
6、可以通過命令:
bitfield key get 類型 點陣圖索引
來獲取指定類型數據的ascii碼。
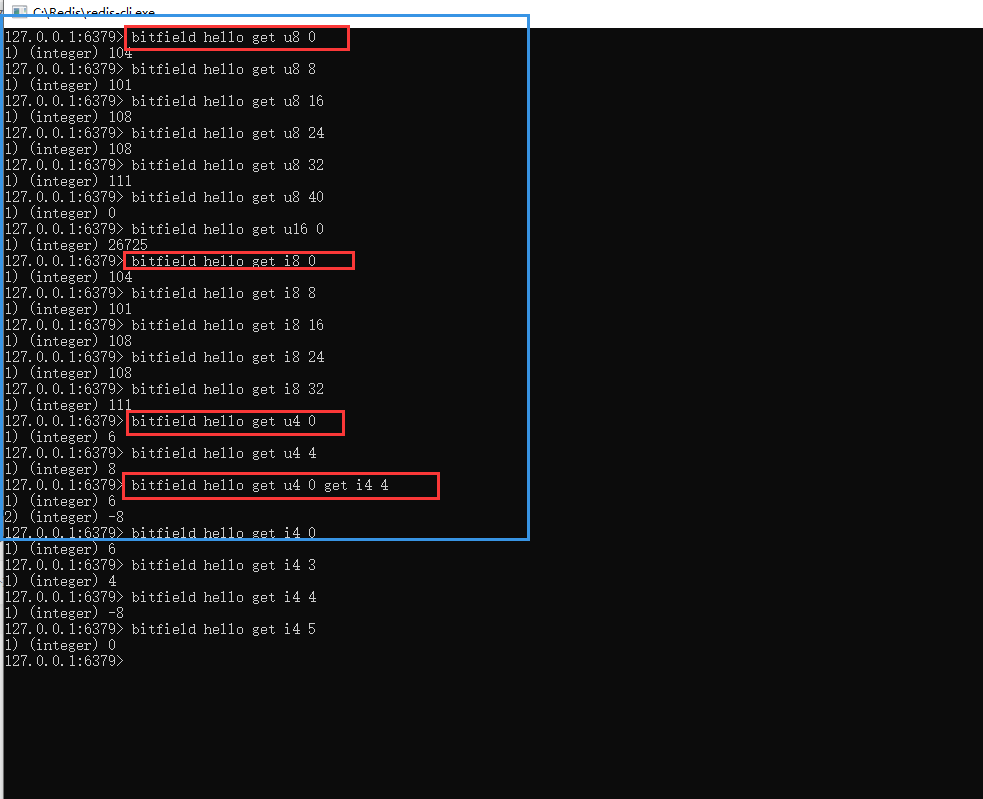
例如,以下截圖中,命令:
bitfield hello get u8 0
其中,u8代表類型,u開頭代表無符號數據,8代表獲取8個bit位。如果是有符號的數據,是以i開頭的。最後面的0,代表要獲取的起始點陣圖下標索引,此處是第0個索引。
hello五個字元,對應的ascii碼分別為:104,101,108,108,111
如果以上命令的類型 u8 換成 u4 ,則獲取到的值是0110,對應的值是6;以此類推。
也可以並列get獲取,例如:
bitfield key get type1 offset1 type2 offset2 ……
其他玩法,大佬們可以自己嘗試。我這邊有關操作可以參考如下截圖所示內容。
7、通過命令:
bitfield key set type 點陣圖索引 ascii碼
可以把對應的ascii碼根據類型寫入到指定的索引中,並且會返回原來索引被替換的ascii碼值。
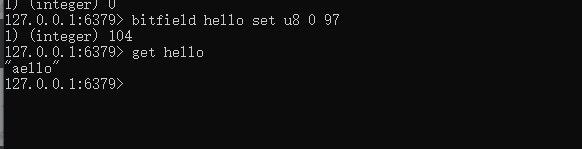
例如下圖所示操作,點陣圖索引從0開始,代表第一個字元h所在位置。97代表a的ascii碼,執行以後,返回104(h的ascii碼),並且通過get命令可以查看到字元串已經被替換了。
8、可以使用命令:
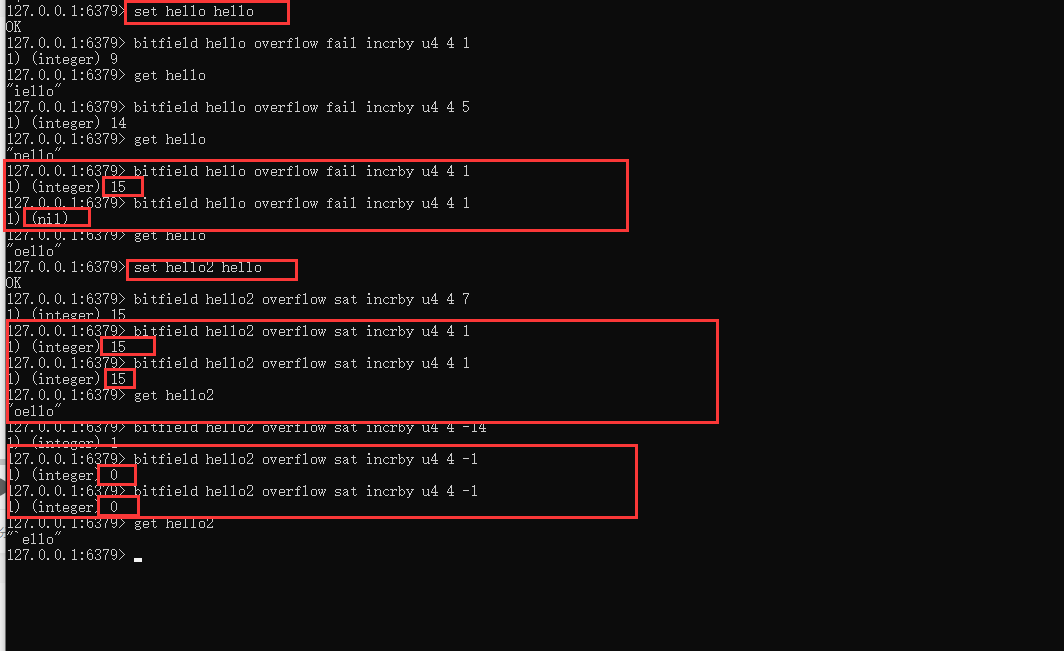
bitfield key incrby type 索引 自增值
對指定類型和索引區間的值進行累加 ,如下圖所示。h通過 u8 類型自增1,即h+1=i
注意:對於累加的數據不能超出指定類型的最大值,例如 u4 最大值是15,累加到15以後會自動折返為0。

9、針對以上會出現折返的情況,可以使用溢出報錯或者保持最大或最小值的方式來避免折返的情況。
使用命令:
Bitfield key overflow fail incrby type offset value
可以實現溢出的時候,會返回nil;
使用命令:
Bitfield key overflow sat incrby type offset value
可以實現當要溢出的時候,還是會返回當前的最大值或最小值。如下圖所示。
二、HyperLogLog
10、HyperLogLog是一種可以快速去重的數據結構。但是有一定的誤差率,大概在0.81%左右。應用場景一般是在需要針對一些大數據量的情況下進行去重計算大概的統計值使用,例如網站的PV量等等。
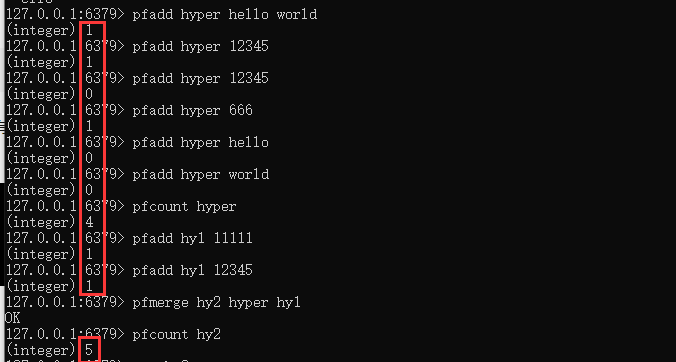
使用命令:
pfadd key value1 value2 ……
可以添加對應的多個數據集到指定的key裡面去。
如果添加已經存在的數據,會被自動去重。
使用命令:pfcount key
可以統計數據集的個數。
使用命令:pfmerge 目標key 源key1 源key2 ……
可以對多個不同的key進行數據合併,並且數據集重複的會自動排重。
使用HyperLogLog的用途,是在針對大數據量的情況下,在允許一定的容錯率的情況下,用它可以節約資源並且快速地進行排重。例如使用set來設置數據,資源損耗肯定是巨大的;但是使用hyperloglog來處理,資源損耗是固定的12kb,可以處理的數據量大約是2^64個數據。
冷門科普:命令是pf開頭,是為了紀念HyperLogLog的作者——Philippe Flajolet
三、布隆過濾器
11、布隆過濾器,最常見的場景是商品推薦業務。例如購物時候瀏覽的資訊被記錄以後,可以進行推薦其他同類型的其他商品。推薦的其他商品不會和瀏覽過的商品重複(去重),但是也存在一定的誤差。
布隆過濾器源地址鏈接:
//github.com/RedisBloom/RedisBloom
先進行下載,下載方式可以按照自己喜歡的方式下載。例如此處我下載到d目錄下的wesky/bloom文件夾下。

然後進入到文件夾內,使用make命令進行編譯。編譯成功的話,會產生一個 redisbloom.so的文件。如下,我也很尷尬,沒成功,就暫且到這裡吧。
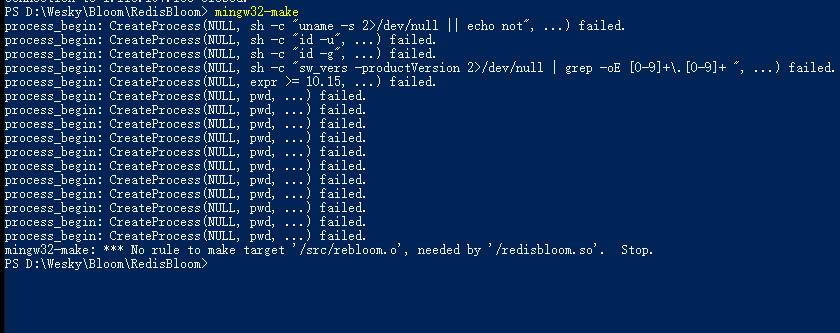
假如上面配置成功的話,啟動redis服務的時候,可以把.so文件配置到redis.conf配置文件下,例如我上面所在的位置,新增的樣式如下:
loadmodule D:/Wesky/Bloom/RedisBloom/redisbloom.so
或者使用命令啟動的時候,使用命令進行指定:
redis-server –loadmodule D:/Wesky/Bloom/RedisBloom/redisbloom.so
由於當前我本機無法編譯布隆過濾器源碼,所以就暫且到這吧,請見諒。
布隆過濾器下,會有一些命令,供參考,大家可以根據自己情況,進行自己嘗試,當作是留個懸念了。
命令:
bf.add key xxx
bf.madd key 數據1 數據2 ……
bf.exists key 數據
bf.mexists key 數據1 數據2 ……
……
今天是2022年的第一天,祝大家元旦快樂~~


