分散式機器學習、聯邦學習、多智慧體的區別和聯繫
一、分散式機器學習、聯邦學習、多智慧體介紹
最近這三個方面的論文都讀過,這裡寫一篇部落格歸納一下,以方便搞這幾個領域的其他童鞋入門。我們先來介紹以下這三種機器學習範式的基本概念。
1、分散式機器學習介紹
分散式機器學習(distributed machine learning),是指利用多個計算/任務節點(Worker)協同訓練一個全局的機器學習/深度學習模型。需要注意的是,分散式機器學習和傳統的HPC領域不太一樣。傳統的HPC領域主要是計算密集型,以提高加速比為主要目標。而分散式機器學習還兼具數據密集型特性,會面臨訓練數據大(單機存不下)、模型規模大的問題。此外,在分散式機器學習也需要更多地關注通訊問題。對於計算量大、訓練數據量大、模型規模大這三個問題,分散式機器學習可以採用以下手段進行解決:
1)對於計算量大的問題,分散式多機並行運算可以基本解決(注意區分傳統HPC中的共享記憶體式的多執行緒並行運算,如OpenMP)。
2)對於訓練數據大的問題,需要將數據進行劃分,並分配到多個工作節點上進行訓練,這種技巧一般被稱為數據並行。每個工作節點會根據局部數據訓練出一個子模型,並且會按照一定的規律和其他工作節點進行通訊(通訊的內容主要是子模型參數或者參數更新),以保證最終可以有效整合來自各個工作節點的訓練結果並得到全局的機器學習模型。

3)對於模型規模大的問題,則需要對模型進行劃分,並且分配到不同的工作節點上進行訓練,這種技巧一般被稱為模型並行。與數據並行不同,模型並行的框架下各個子模型之間的依賴關係非常強,因為某個子模型的輸出可能是另外一個子模型的輸入,如果不進行中間計算結果的通訊,則無法完成整個模型訓練。因此,一般而言,模型並行相比數據並行對通訊的要求更高。

2、聯邦學習介紹
聯邦學習是一種特殊的分散式機器學習,除了關注傳統分散式機器學習的演算法、通訊、收斂率等問題之外,還要關注用戶的數據隱私和容錯性問題(因為用戶終端是用戶手機或物聯網設備,很可能隨時掛掉)。 其設計目標是在保障大個人數據隱私、保證合法合規的前提下,在多參與方(可能是現實中的多個機構)或多計算結點之間協同學習到一個更好的全局模型。
經典的server-client式的聯邦學習框架的訓練過程可以簡單概括為以下步驟:
1)server端建立「元模型」,並將模型的基本結構與參數告知各client端;
2)各client端利用本地數據進行模型訓練,並將結果返回給server端;
3)server端匯總各參與方的模型,構建更精準的全局模型,以整體提升模型性能和效果。
當然,以上僅僅指中心化的server-client聯邦學習,至於去中心化的聯邦學習大家可以參考我的《分散式多任務學習論文閱讀》(鏈接://www.cnblogs.com/orion-orion/p/15481054.html)部落格系列和部落格《聯邦學習中的模型聚合》(鏈接://www.cnblogs.com/orion-orion/p/15635803.html)以及相關論文[1][2][3]。

聯邦學習框架包含多方面的技術,比如傳統分散式機器學習中的模型訓練與參數整合技術、Server與Client高效傳輸的通訊技術、隱私加密技術、分散式容錯技術等。
3、群體智慧基本概念
多智慧體系統(multi-agent system) 是一組自主的,相互作用的實體,它們共享一個共同的環境(environment),利用感測器感知,並利用執行器作動。多智慧體系統提供了用分散式來看待問題的方式,可以將控制許可權分布在各個智慧體上。
儘管多智慧體系統可以被賦予預先設計的行為,但是他們通常需要在線學習,使得多智慧體系統的性能逐步提高。而這就天然地與強化學習聯繫起來,智慧體通過與環境進行交互來學習。在每個時間步,智慧體感知環境的狀態並採取行動,使得自身轉變為新的狀態,在這個過程中,智慧體獲得獎勵,智慧體必須在交互過程中最大化期望獎勵。
二、三者的區別和聯繫
| 分散式機器學習 | 聯邦學習 | 多智慧體 | |
|---|---|---|---|
| 解決的問題 | 針對運算量大、數據量大等問題使用電腦集群來訓練大規模機器學習模型 | 針對保護用戶隱私保護,數據安全等問題,通過高效的演算法、加密演算法等進行機器學習建模,打破數據孤島。 | 主要在多機器人、多無人機協同編隊以及多目標跟蹤與監控中發揮作用 |
| 數據處理方案 | 數據並行:先將訓練數據劃分為多個子集(切片),然後將各子集置於多個計算實體中,並行訓練同一個模型 聯邦建模各方,本地數據不出庫,先在本地訓練模型參數(或梯度),然後通過同態加密技術交互其參數,更新模型。 | 聯邦建模各方,本地數據不出庫,先在本地訓練模型參數(或梯度),然後通過同態加密技術交互其參數,更新模型。 | 可以預先收集好環境數據然後採用經驗回放技術進行訓練,也可以直接採用在線學習的形式,即多個智慧體在環境中進行交互學習, |
| 訓練方案 | 工業應用中,大部分還是以數據並行為主:各個節點取不同的數據,然後各自完成前向和後向的計算得到梯度用以更新共有的參數,然後把update後的模型再傳回各個節點。 | 各方在本地初始化模型參數,經過訓練獲得梯度(或參數),交由可信第三方進行模型的更新,然後分發到各方本地進行更新,如此反覆,獲得做種的模型。 | 每個智慧體獨立與環境交互,利用環境回饋的獎勵改進自己的策略,以獲得更高的回報(即累計獎勵)。此外多個智慧體是相互影響的,一個智慧體的策略不能簡單依賴於自身的觀測、動作,還需要考慮到其他智慧體的觀測、動作。常採用中心化訓練+去中心化執行[5][6]這一訓練模式 |
| 通訊方式 | MPI、NCCL、gRPC | gRPC(大部分) | 高速網路 |
| 數據 | IID(獨立同分布)數據,數據均衡 | 非IID數據,數據不均衡甚至異構 | 多智慧體處於統一環境,數據滿足IID |
| 成本 | 有專用的通訊條件,所以通訊代價往往較小 | 通訊的代價遠高於計算的代價 | 智慧體之間常由感測器高速網路連接,通訊代價小 |
| 容錯性 | 很少考慮容錯問題 | 容錯性問題非常重要 | 基本不考慮容錯性 |
三、個人研究體會
傳統的分散式機器學習已經被研究十幾年了,Low-hanging fruits幾乎被人摘完了,目前各大高峰會上的分散式機器學習主要是數學味道很濃的分散式數值優化演算法。而其他方面,像我關注的分散式多任務學習,近年來相關的高峰會論文開始減少。
聯邦學習可以看做一種特殊的分散式學習,它有一些特殊的設定,比普通的分散式學習要困難一些,還是有很多方向可以研(灌)究(水)的,做好了應該可以發高峰會。
-
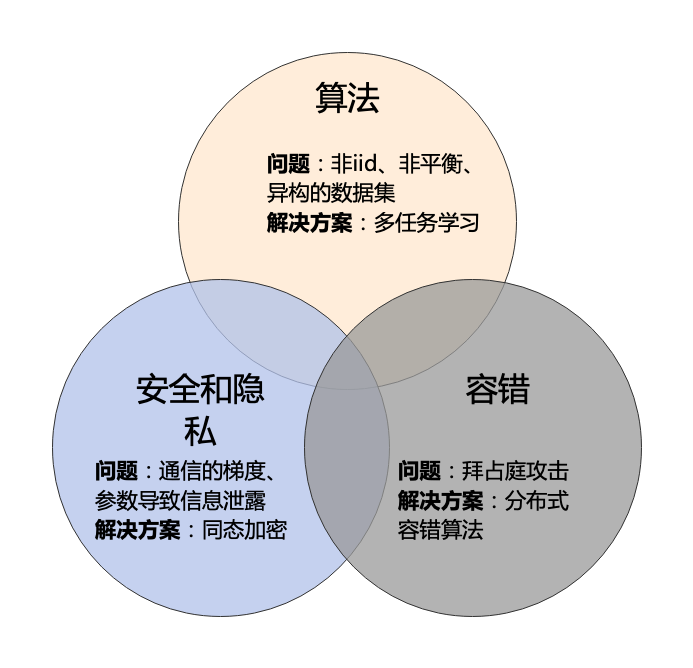
演算法層面 可以在演算法層面降低演算法通訊次數,用少量的通訊達到收斂。基於IID數據集的分散式數值優化演算法已經被研究得比較透徹了, 但因為聯邦學習面臨數據是IID/非平衡甚至是異構的,需要引入很多其他技巧才能解決,比如異構數據聯合學習、多任務學習[3][4](也是我研究的方向)等。這個方向很適合數值優化、機器學習、多任務學習背景的童鞋切入。
-
安全/隱私問題 雖然聯邦學習的基礎設定就是節點之間不共享數據以保護用戶隱私,但熟悉網路安全的同學應該知道,我們很容易從梯度、模型參數中反推出用戶數據。而針對這方面提出攻擊和防禦的方法都可以發表出論文,這方面適合網路安全背景的童鞋切入。
-
容錯性/魯棒性。聯邦學習中常常遇到拜占庭攻擊問題(即惡意參與者問題)。比如在中心化的演算法中,有節點惡意發送錯誤的梯度給伺服器,讓訓練的模型變差;在去中心化演算法中,可能有多個任務節點化為拜占庭攻擊者互相攻擊[2]。對於這種問題設計新的攻擊方法和防禦方法都可以發表論文。這個方向很適合有分散式系統背景的童鞋切入。
至於多智慧體系統,因為我個人對強化學習領域不太熟悉,就不敢妄言了。
參考文獻
- [1] Zhang C, Zhao P, Hao S, et al. Distributed multi-task classification: A decentralized online learning approach[J]. Machine Learning, 2018, 107(4): 727-747.
- [2] Li J, Abbas W, Koutsoukos X. Byzantine Resilient Distributed Multi-Task Learning[J]. arXiv preprint arXiv:2010.13032, 2020.
- [3] Marfoq O, Neglia G, Bellet A, et al. Federated multi-task learning under a mixture of distributions[J]. Advances in Neural Information Processing Systems, 2021, 34.
- [4] Smith V, Chiang C K, Sanjabi M, et al. Federated multi-task learning[J]. Advances in Neural Information Processing Systems, 2017.
- [5] F. A. Oliehoek, M. T. Spaan, and N. Vlassis. Optimal and approximate Q-value functions for decentralized
POMDPs. Journal of Artificial Intelligence Research, 32:289–353, 2008. - [6] D. V. Prokhorov and D. C. Wunsch. Adaptive critic designs. IEEE transactions on Neural Networks, 8(5):997–
1007, 1997.


