系統設計實踐(03)- Instagram社交服務
- 2021 年 9 月 27 日
- 筆記
前言
系統設計實踐篇的文章將會根據《系統設計面試的萬金油》為前置模板,講解數十個常見系統的設計思路。
前置閱讀:
設計目標
讓我們設計一個像Instagram這樣的照片分享的社交網站,用戶可以上傳照片分享給其他用戶。
一. 什麼是Instagram?
Instagram是一種社交網路服務,用戶可以上傳和分享自己的照片、影片給其他用戶。Instagram用戶可以選擇公開或私下分享資訊。公開共享的內容都可以被任何其他用戶看到,而私有共享的內容只能被指定的一組人訪問。Instagram還允許用戶通過Facebook、Twitter、Flickr和Tumblr等其他社交網路平台進行分享。
在此,我們計劃設計一個更簡單的Instagram,用戶可以分享照片,也可以關注其他用戶。每個用戶的動態消息將包含該用戶關注的所有人的照片動態。
二. 系統的需求與目標
在設計Instagram時,我們將重點關注以下需求
功能性需求
- 用戶可以上傳下載查看照片
- 用戶可以根據影片或者照片標題搜索
- 用戶之間可以互相關注
- 該系統應該能夠生成並顯示用戶關注的所有人的熱門照片組成的「新聞動態(News Feed)」。
非功能性需求
- 我們的服務需要高可用性。
- 對於好友動態的生成,系統可接受的延遲是200ms。
- 一致性可能會受到影響(出於可用性的考慮),如果用戶一段時間沒有看到照片,應該沒問題
- 系統應高度可靠;任何上傳的照片或影片都不能丟失。
不用考慮
給照片添加標籤,在標籤上搜索照片,在照片上評論,給照片用戶加標籤,跟蹤誰,等等
三. 系統分析
該系統將具有大量的讀操作,因此我們將重點構建一個能夠快速檢索照片的系統。
- 實際上,用戶可以上傳任意多的照片。在設計該系統時,有效的存儲管理應該是一個關鍵因素。
- 在查看照片時,預計延遲較低。
- 數據應該是100%可靠的。如果用戶上傳了一張照片,系統將保證它永遠不會丟失。
四. 容量估計與約束
- 假設我們有5億用戶,每天有100萬活躍用戶
- 每天200萬張新照片,每秒23張。
- 平均照片文件大小=> 200KB
- 一天照片需要的存儲量
2M * 200KB => 400 GB
- 十年需要的存儲空間
400GB * 365(day a year) * 10 (years) ~= 1425TB
五. 高級設計
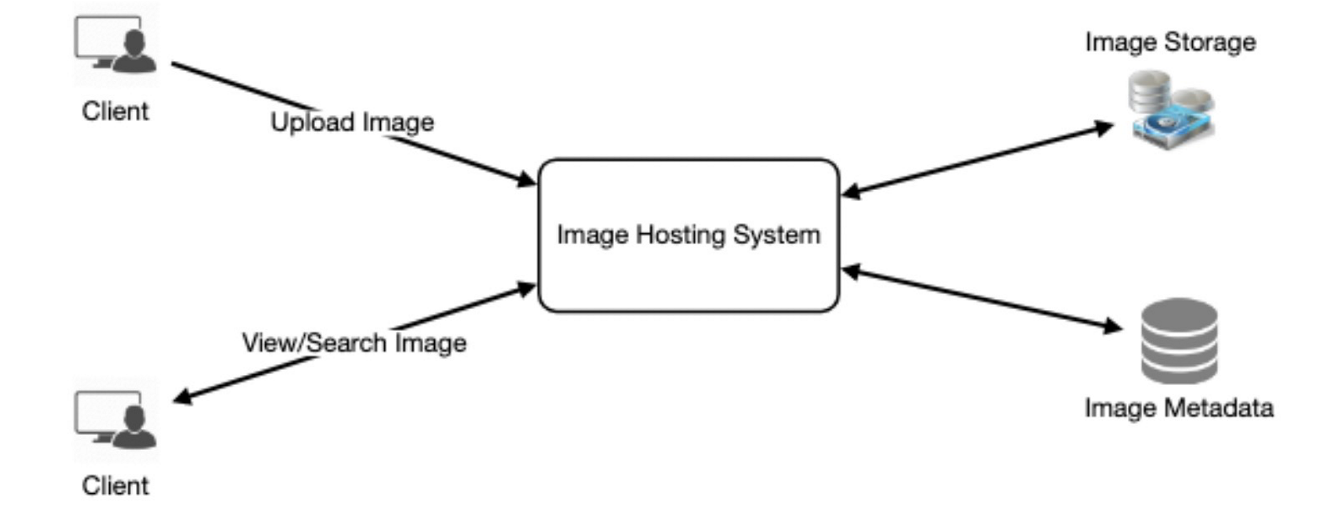
在高級設計中,我們需要支援兩種方案,一種是上傳圖片,另一種是查看和搜索圖片。
我們需要對象存儲伺服器來存儲照片,還需要一些資料庫伺服器來存儲關於照片的元數據資訊。
六. 資料庫設計
早期階段定義DB模型將有助於理解不同組件之間的數據流,並在之後進行數據分區
我們需要存儲用戶、用戶上傳的照片以及用戶關注的人的數據。照片表將存儲一張照片相關的所有數據,我們需要在(PhotoID, CreationDate)上有一個索引,因為我們需要獲取最近的照片。
| Photo | User | UserFollow |
|---|---|---|
| [PK] Photo ID: int | [PK] UserID: int | [PK] UserID1: int |
| UserID: int | Name: varchar(20) | [PK] UserID2: int |
| PhotoPath: varchar(256) | Email: varchar(20) | |
| PhotoLatitude: int | DateOfBirth: datetime | |
| PhotoLongitude: int | CreationDate: datetime | |
| UserLatitude: int | LastLoginDate: datetime | |
| UserLongitude: int | ||
| CreationDate: datetime |
存儲上述表結構的一種簡單方法是使用像MySQL這樣的RDBMS,因為我們有連表查詢的場景。但是關係資料庫也存在其他挑戰。關於細節請參閱SQL vs NoSQL。
我們可以將照片存儲在像HDFS或S3這樣的分散式文件存儲中,將上述表結構存儲在分散式鍵值存儲中,以享受NoSQL提供的好處。所有與照片相關的元數據都可以進入一個表,其中的鍵是PhotoID,值是一個包含PhotoLocation、UserLocation、CreationTimestamp等的對象。
我們需要存儲用戶和照片之間的關係,知道誰擁有哪張照片。我們還需要存儲用戶關注的人的列表。對於這兩個表,我們可以使用像Cassandra這樣的寬列數據存儲。對於UserPhoto表,鍵是UserID,值是用戶擁有的PhotoID列表,存儲在不同的列中。對於UserFollow表,我們將有一個類似的方案。
一般來說,Cassandra或鍵值存儲總是維護一定數量的副本,以提供可靠性。此外,在這樣的數據存儲中,刪除操作不會立即生效,數據在從系統中永久刪除之前會保留幾天(以支援反刪除)。
七. 數據估算
讓我們估算一下每個表中會有多少數據,以及10年里我們總共需要多少存儲空間。
用戶表
假設每個int和dateTime都是四個位元組,那麼用戶表中的每一行都是 68 個位元組
UserID (4 bytes) + Name (20 bytes) + Email (32 bytes) + DateOfBirth (4 bytes) + CreationDate (4 bytes) + LastLogin (4 bytes) = 68 bytes
如果我們有5億用戶,我們將需要32GB的總存儲空間。
500 million * 68 ~= 32GB
照片表
Photo表中的每一行都是284位元組
PhotoID (4 bytes) + UserID (4 bytes) + PhotoPath (256 bytes) + PhotoLatitude (4 bytes) + PhotLongitude(4 bytes) + UserLatitude (4 bytes) + UserLongitude (4 bytes) + CreationDate (4 bytes) = 284 bytes
如果每天有2M的新照片上傳,我們一天需要0.5GB的存儲空間
2M * 284 bytes ~= 0.5GB per day
未來10年,我們需要1.88TB的存儲空間。
用戶關注表
UserFollow表中的每一行都由8個位元組組成。如果我們有5億用戶,平均每個用戶關注500個用戶。我們需要1.82TB的存儲空間來存儲UserFollow表。
500 million users * 500 followers * 8 bytes ~= 1.82TB
所有表10年所需的總空間為3.7TB
32GB + 1.88TB + 1.82TB ~= 3.7TB
八. 組件設計
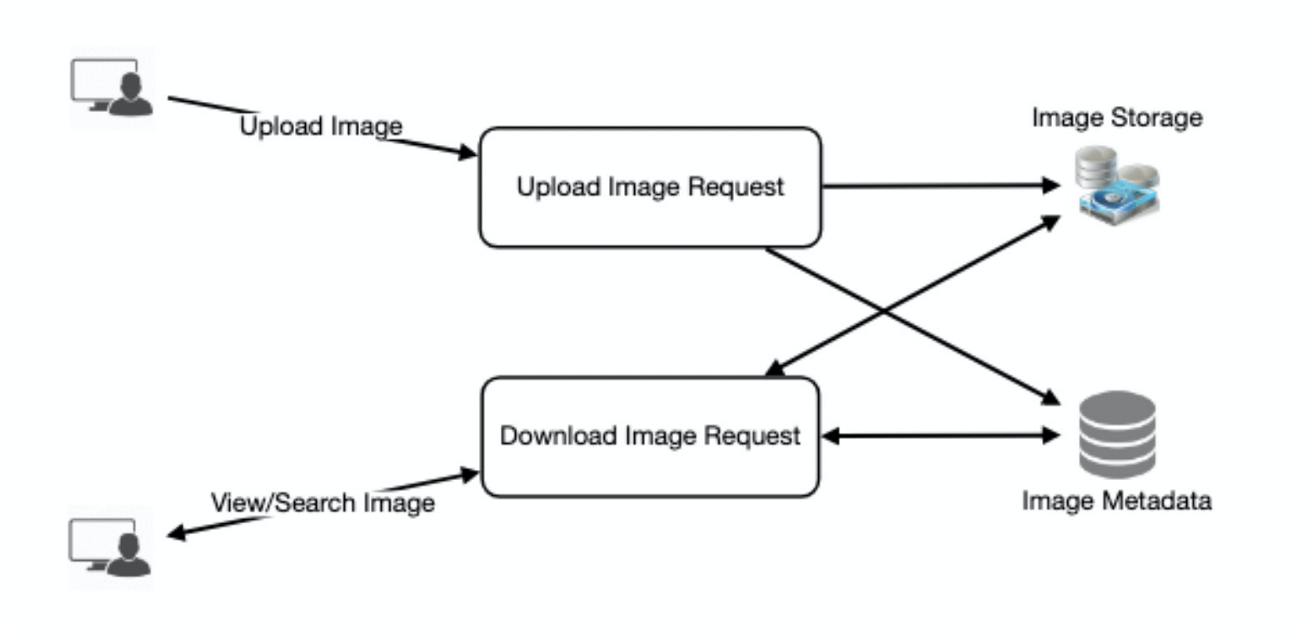
照片上傳(寫操作)可能會很慢,因為它們必須進入磁碟,而讀取將會更快,特別是當它們是從快取讀取來提供服務時。
用戶上傳操作有可以消耗所有可用的連接,因為上傳是一個緩慢的過程。 這意味著如果系統忙於處理所有寫入請求,則無法提供讀取服務。 在設計我們的系統之前,我們應該記住 Web 伺服器有一個連接限制。 如果我們假設一個 Web 伺服器同時最多可以有 500 個連接,那麼它的並發上傳或讀取不能超過 500。 為了解決這個瓶頸,我們可以將讀取和寫入拆分為單獨的服務。 我們將用於讀取的伺服器和用於寫入的伺服器進行分離,以確保上傳不會影響到讀取。
九. 可靠性與冗餘性
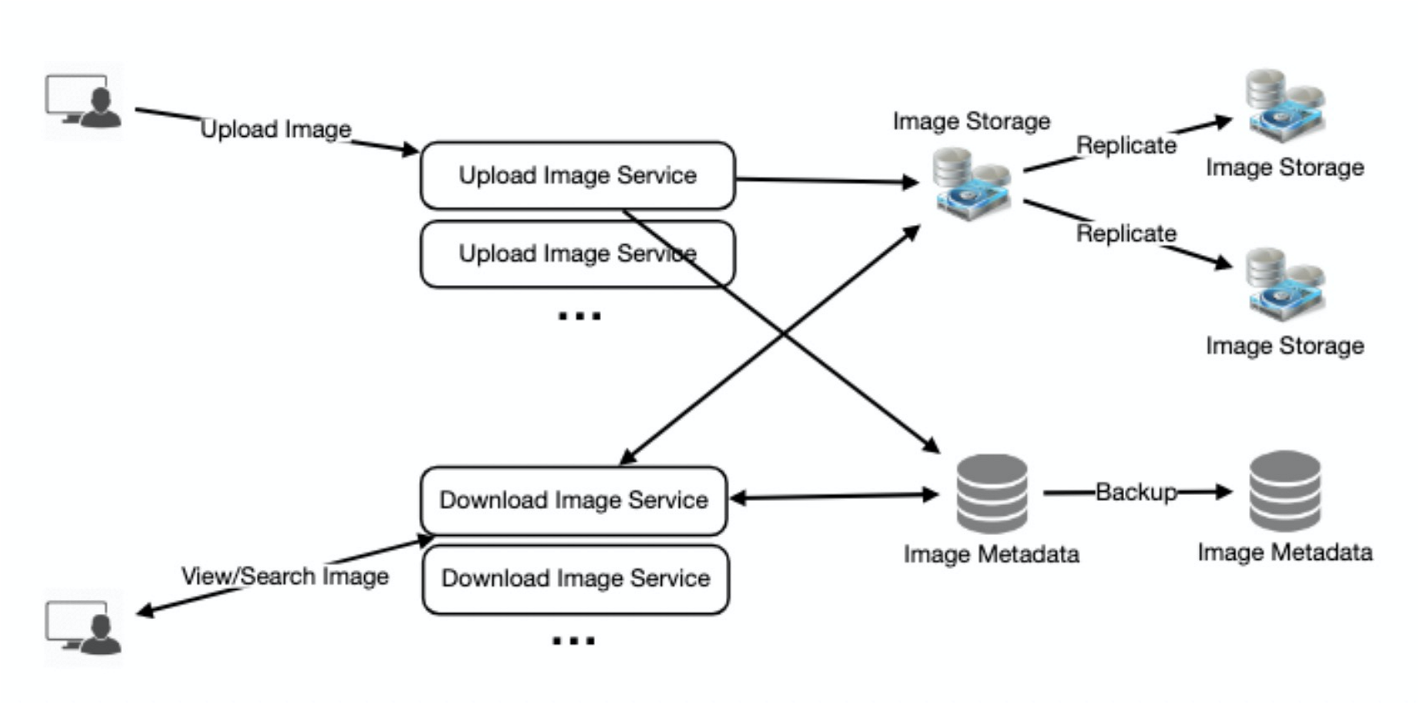
我們需要保證用戶上傳的圖片不會丟失,並且可查看。因此,我們將為每個文件存儲多個副本,這樣,如果一個存儲伺服器掛掉,我們可以從另一個存儲伺服器上的副本檢索照片。
同樣的原則也適用於系統的其他組件。如果我們希望系統具有高可用性,我們需要在系統中運行多個服務副本,這樣,如果一些服務宕機,系統仍然可用並在運行。冗餘消除了系統中的單點故障。
如果在任何時刻只需要一個服務實例運行,我們可以運行不服務任何流量的服務的冗餘輔助副本,但當主伺服器出現問題時,它可以在故障轉移後接管控制權。
在系統中創建冗餘可以消除單點故障,並在主節點出現問題時提供備份或備用功能。例如,如果同一服務的兩個實例運行在生產環境中,其中一個實例發生故障或降級,則系統可以故障轉移到正常的副本。故障轉移可以自動發生,也可以人工干預。
十. 數據分片
讓我們討論元數據分片的不同方案。
方案一. 基於UserID分片
假設我們基於UserID進行分片,這樣我們就可以將一個用戶的所有照片保存在同一個分片上。如果一個DB Shard是1TB,那麼我們需要4個shard來存儲3.7TB的數據。讓我們假設為了更好的性能和可伸縮性,我們保留10個分片
因此,我們將根據UserID % 10找到分片數,然後將數據存儲在那裡。為了在我們的系統中唯一地識別任何照片,我們可以在每個PhotoID後面添加分片號。
如何生成PhotoID? 每個DB分片都可以有自己的PhotoID自動遞增序列,因為我們將用每個PhotoID添加ShardID,它將使它在整個系統中獨一無二。
這個分區方案有什麼問題
- 我們將如何處理熱門用戶? 一些人關注這些熱門用戶,很多人看到他們上傳的任何照片。
- 有些用戶會比其他人擁有更多的照片,從而造成存儲的不均勻分布。
- 如果我們不能將一個用戶的所有圖片存儲在一個分片上,該怎麼辦? 如果我們將一個用戶的照片分發到多個分片上會導致更高的延遲
- 將一個用戶的所有照片存儲在一個分片上可能會導致一些問題,比如如果分片宕機,所有用戶的數據都不可用,或者如果分片負載高,延遲會更高,等等。
方案二. 基於PhotoID分片
如果我們能先生成唯一的PhotoID,然後通過PhotoID % 10找到一個分片號,那麼上述問題就解決了。在這種情況下,我們不需要在ShardID後面加上PhotoID,因為PhotoID本身在整個系統中是唯一的。
我們怎樣才能生成PhotoIds?
在這裡,我們不能在每個Shard中使用自動遞增序列來定義PhotoID,因為我們需要知道PhotoID才能找到存儲它的Shard。一種解決方案是我們專門使用一個單獨的資料庫實例來生成自動遞增的 ID(參考美團Leaf實現)。 如果我們的 PhotoID 可以容納 64 位,我們可以定義一個只包含 64 位 ID 欄位的表。 所以每當我們想在我們的系統中添加一張照片時,我們可以在這個表中插入一個新行,並將該 ID 作為我們新照片的 PhotoID。
生成DB的密鑰不是單點故障嗎?
是的。解決方法是定義兩個這樣的資料庫,一個生成偶數id,另一個生成奇數id。對於MySQL,下面的腳本可以定義這樣的序列。
KeyGeneratingServer1:
auto-increment-increment = 2
auto-increment-offset = 1
KeyGeneratingServer2:
auto-increment-increment = 2
auto-increment-offset = 2
我們可以在這兩個資料庫前面放置一個負載均衡器,以便在它們之間進行輪詢並處理。這兩個伺服器可能不同步,其中一個生成的密鑰比另一個多,但這不會在我們的系統中造成任何問題。我們可以通過為Users、Photo-Comments或系統中存在的其他對象定義單獨的ID表來擴展這種設計。
另外,我們可以實現一個密鑰生成方案,類似於我們在設計一個URL短鏈服務(如TinyURL)中討論過的方案KGS。
如何規劃我們系統的未來發展?
我們可以有大量的邏輯分區來適應未來的數據增長,這樣以來,多個邏輯分區駐留在單個物理資料庫伺服器上。 由於每個資料庫伺服器上可以有多個資料庫實例,我們可以為任何伺服器上的每個邏輯分區擁有單獨的資料庫。 所以每當我們覺得某個特定的資料庫伺服器有很多數據時,我們可以將一些邏輯分區從它遷移到另一台伺服器。 我們可以維護一個配置文件(或一個單獨的資料庫),將我們的邏輯分區映射到資料庫伺服器; 這將使我們能夠輕鬆地移動分區。 每當我們想要移動一個分區時,我們只需要更新配置文件來更改。
十一. 好友動態生成
要為給定用戶創建好友動態(類似於朋友圈),我們需要獲取該用戶關注的人的最新、最受歡迎的照片。
為簡單起見,假設我們需要為用戶的朋友圈獲取前 100 張照片。 我們的應用伺服器將首先獲取用戶關注的人列表,然後從每個用戶獲取最新 100 張照片的元數據資訊。 在最後一步,伺服器將所有這些照片提交給我們的排名演算法,該演算法將確定前 100 張照片(基於時間維度、相似度等)並將它們返回給用戶。 這種方法的問題是延遲很高,因為我們必須查詢多個表並對結果執行排序/合併/排名。 為了提高效率,我們可以預先生成好友動態數據並將其存儲在單獨的表中。
預生成好友動態: 我們可以使用專門伺服器,不斷生成用戶好友動態數據並將它們存儲在UserNewsFeed表中。因此,當任何用戶需要查看他的好友動態照片時,我們只需查詢這個表並將結果返回給用戶。
每當伺服器需要生成用戶的NewsFeed時,它們將首先查詢UserNewsFeed表,以查找最後一次為該用戶生成好友動態的時間。然後,新的好友動態數據將從那時起生成(按照上面提到的步驟)。
向用戶發送動態消息內容有哪些不同的方法?
- 拉模式: 客戶可以定期或在需要的時候手動從伺服器拉出好友動態內容。這種方法可能存在的問題是:
- 直到客戶端發出拉取請求時,新數據可能不會顯示給用戶;
- 如果沒有新數據,大多數情況下拉取請求會導致空響應
- 推模式 : 伺服器可以在新數據可用時將其推送給用戶。為了有效地管理這一點,用戶必須在伺服器上維護一個Long Poll請求以接收更新。這種方法可能存在的一個問題是,一個關注了很多人的用戶,或者一個擁有數百萬粉絲的名人用戶;在這種情況下,伺服器必須非常頻繁地推送更新。
- 混合模式 : 我們可以採用混合方法。 我們可以將所有擁有大量關注的用戶轉移到基於拉取的模型,並且只將數據推送給那些擁有數百(或數千)關注的用戶。 另一種方法可能是伺服器以不超過一定頻率向所有用戶推送更新,讓有大量關注/更新的用戶定期拉取數據.
十二. 使用分片數據創建好友動態
為任何給定用戶創建好友動態最重要的要求之一就是從該用戶關注的所有人那裡獲取最新的照片。為此,我們需要一種機制來對照片在創建時進行排序。為了有效地做到這一點,我們可以將照片創建時間作為PhotoID的一部分。因為我們在PhotoID上有一個主索引,所以很快就能找到最新的PhotoID。
我們可以使用時間來記錄。假設PhotoID有兩部分,第一部分將表示epoch時間,而第二部分將是一個自動遞增的序列。因此,要創建一個新的PhotoID時,我們可以取當前的epoch time,並從生成密鑰的DB中添加一個自動遞增的ID。我們可以從這個PhotoID (PhotoID % 10)中計算出分片數,並將照片存儲在那裡。
PhotoID的大小是多少? 假設我們的時間從今天開始,我們需要多少位來存儲未來 50 年的秒數?
86400 sec/day * 365 (days a year) * 50 (years) => 1.6 billion seconds
我們需要31位來存儲這個數字。平均而言,我們預計每秒會有23張新照片,我們可以分配9位來存儲自動遞增序列。所以每一秒我們都能存儲(2^9 => 512)新照片。我們可以每秒重置自動遞增序列。
十三. 快取與負載均衡
我們的服務將需要一個大規模的照片傳送系統來服務全球分布的用戶。我們的服務應該使用大量地理分布的照片快取伺服器,並使用cdn(詳細資訊請參見快取),將內容推向用戶。
為元數據伺服器引入一個快取來快取部分熱點數據。我們可以使用Memcache來快取數據,應用伺服器在訪問資料庫之前可以快速檢查快取中是否有所需的行。對於我們的系統來說,最近最少使用(LRU)是一種合理的快取回收策略。在這個策略下,我們首先丟棄最近查看次數最少的行。
如何構建更智慧的快取? 如果我們採用80-20法則,即每天20%的照片閱讀量產生80%的流量,這些照片非常受歡迎,大多數人都會查看訪問它們。這意味著我們可以嘗試快取每日照片和元數據讀取量的20%。


