1.深入TiDB:初見TiDB
轉載請聲明出處哦~,本篇文章發佈於luozhiyun的部落格://www.luozhiyun.com/archives/584
本篇文章應該是我研究的 TiDB 的第一篇文章,主要是介紹整個 TiDB 架構以及它能支援哪些功能為主。至於其中的細節,我也是很好奇,所以不妨關注一下,由我慢慢講述。
為什麼要研究 TiDB ?
其實 TiDB 我想要了解已經很久了,但是一直都有點不想去面對這麼大一灘程式碼。由於在項目組當中一直用的是 Mysql,但是數據量越來越大,有些表的數據量已達上億,數據量在這個數量級其實對 Mysql 來說已經是非常吃力了,所以想找個分散式的資料庫。
於是找到了騰訊主推的一款金融級別資料庫 TDSQL。TDSQL 是基於 MariaDB 內核 ,結合 mysql-proxy、ZooKeeper 等開源組件實現的資料庫集群系統,並且基於 MySQL 半同步的機制,在內核層面做了大量優化,在性能和數據一致性方面都有大幅的提升,同時完全兼容 MySQL 語法,支援 Shard 模式(中間件分庫分表)和 NoShard 模式(單機實例)。
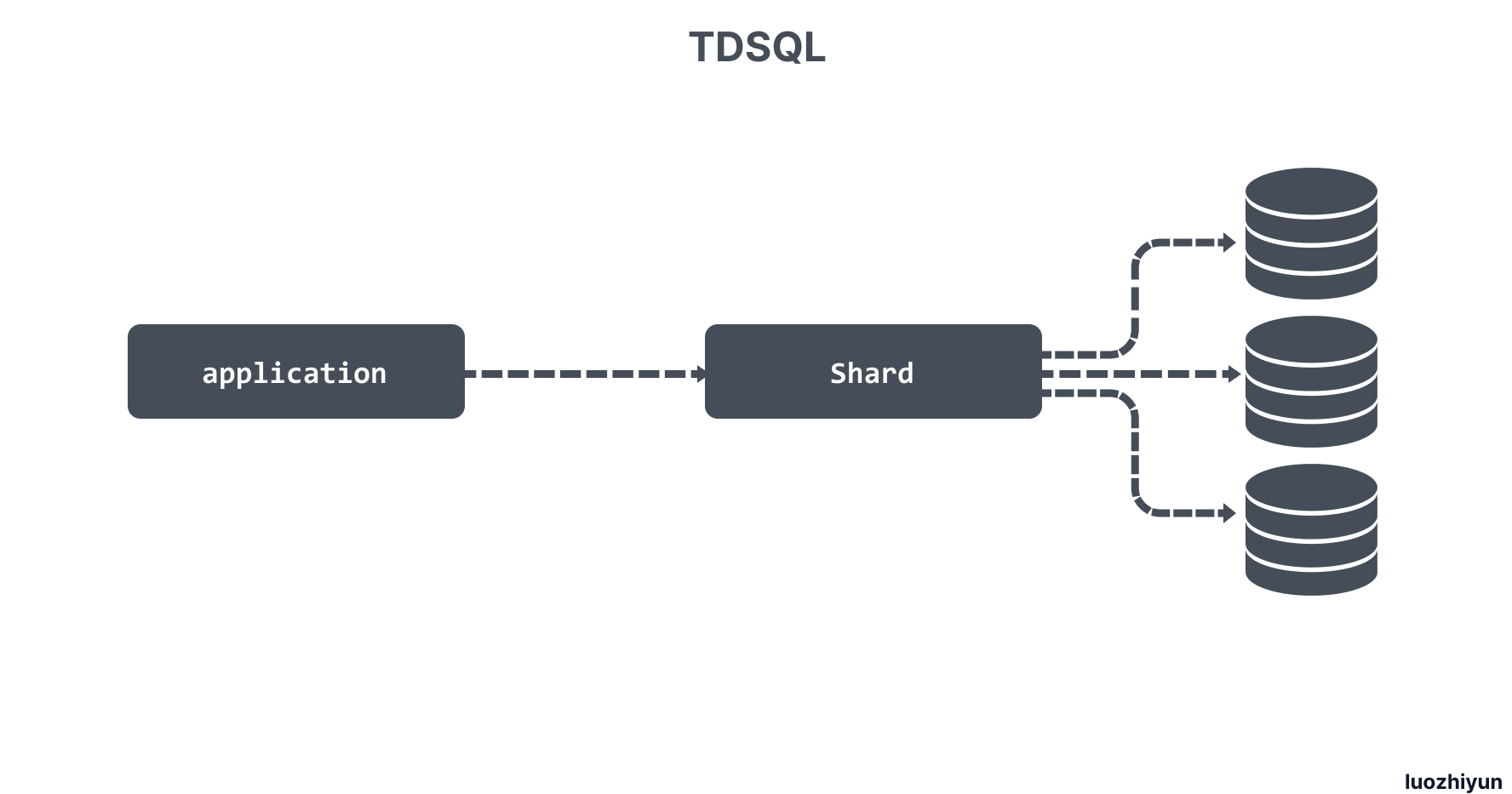
通過 TDSQL 的 Shard 模式把一個表 Shard 之後再處理其實需要在功能上做一些犧牲,並且對應用的侵入性比較大,比如所有的表必須定義 shard-key ,對有些分散式事務的場景可能會有瓶頸。
所以在這個背景下我開始研究 NewSQL 資料庫,而 TiDB 是 NewSQL 行業中的代表性產品 。
對於 NewSQL 資料庫可能很多人都沒聽過,這裡說一下 。NewSQL 比較通用的定義是:一個能兼容類似 MySQL 的傳統單機資料庫、可水平擴展、數據強一致性同步、支援分散式事務、存儲與計算分離的關係型資料庫。
TiDB 介紹
根據官方的介紹 TiDB 具有以下優勢:
- 支援彈性的擴縮容;
- 支援 SQL,兼容大多數 MySQL 的語法,在大多數場景下可以直接替換 MySQL;
- 默認支援高可用,自動進行數據修復和故障轉移;
- 支援 ACID 事務;
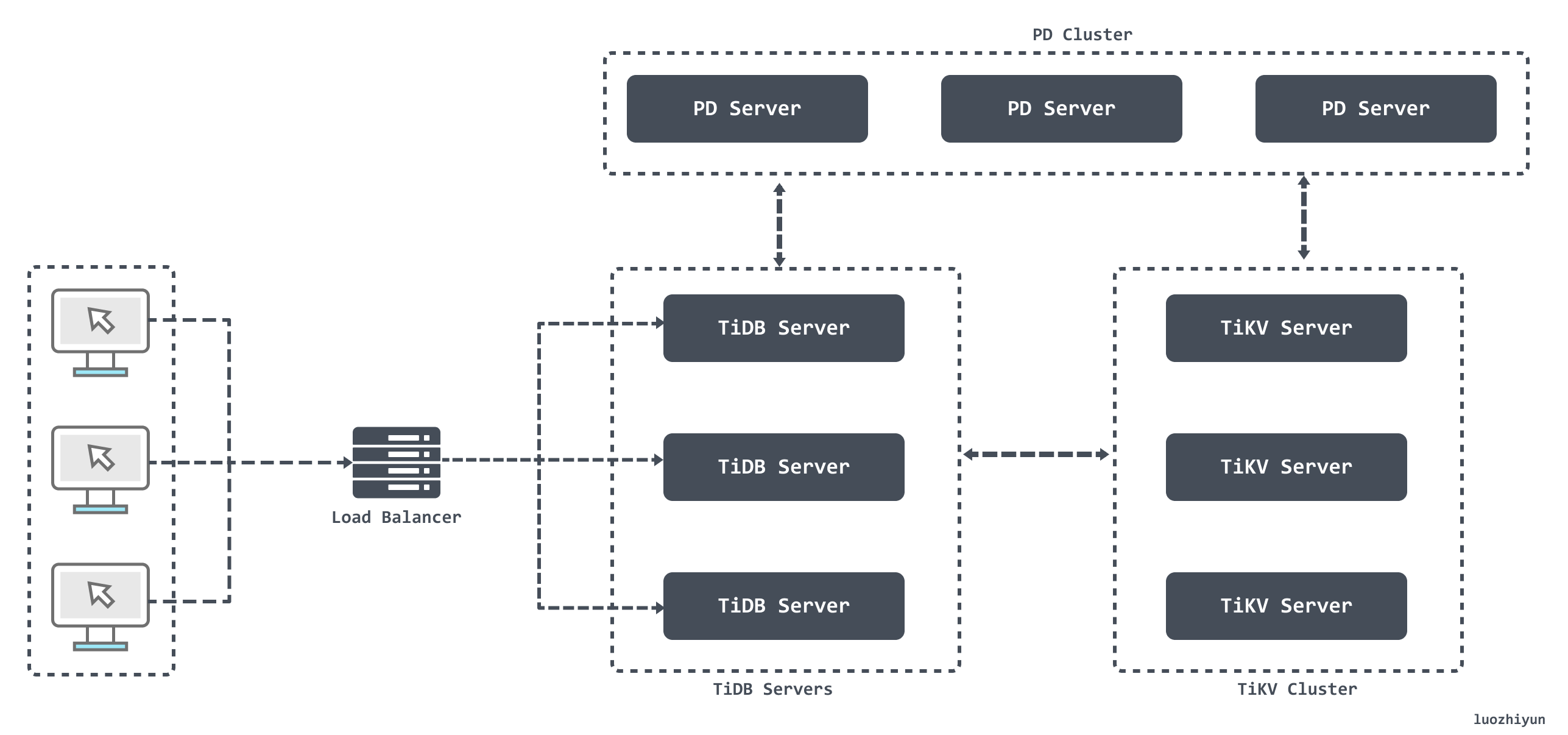
從圖上我們可以看出主要分為:TiDB Server 、PD (Placement Driver) Server、存儲節點。
- TiDB Server:TiDB Server 本身並不存儲數據,負責接受客戶端的連接,解析 SQL,將實際的數據讀取請求轉發給底層的存儲節點;
- PD (Placement Driver) Server:負責存儲每個 TiKV 節點實時的數據分布情況和集群的整體拓撲結構,並為分散式事務分配事務 ID。同時它還負責下發數據調度命令給具體的 TiKV 節點;
- 存儲節點:存儲節點主要有兩部分構成 TiKV Server 和 TiFlash
- TiKV :一個分散式的提供事務的 Key-Value 存儲引擎;
- TiFlash:專門解決OLAP場景。藉助ClickHouse實現高效的列式計算
TiDB 存儲
這裡主要介紹 TiKV 。TiKV 其實可以把它想像成一個巨大的 Map,用來專門存儲 Key-Value 數據。但是數據都會通過 RocksDB 保存在磁碟上。
TiKV 存放的數據也是分散式的,它會通過 Raft 協議(關於 Raft 可以看這篇://www.luozhiyun.com/archives/287)把數據複製到多台機器上。
TiKV 每個數據變更都會落地為一條 Raft 日誌,通過 Raft 的日誌複製功能,將數據安全可靠地同步到複製組的每一個節點中。少數幾台機器宕機也能通過原生的 Raft 協議自動把副本補全,可以做到對業務無感知。
TiKV 將整個 Key-Value 空間分成很多段,每一段是一系列連續的 Key,將每一段叫做一個 Region。每個 Region 中保存的數據默認是 144MB,我這裡還是引用官方的一張圖:
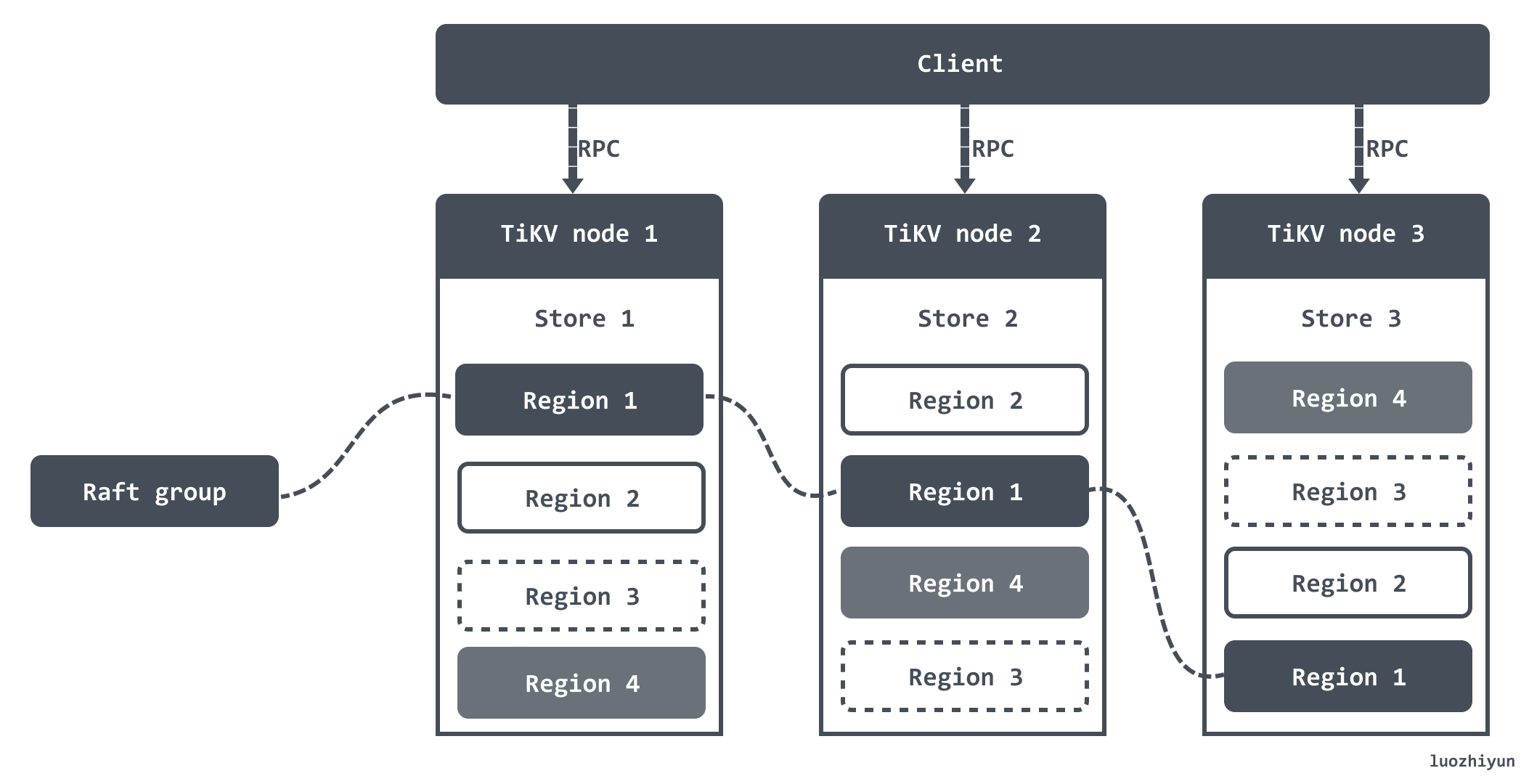
當某個 Region 的大小超過一定限制(默認是 144MB),TiKV 會將它分裂為兩個或者更多個 Region,以保證各個 Region 的大小是大致接近的,同樣,當某個 Region 因為大量的刪除請求導致 Region 的大小變得更小時,TiKV 會將比較小的兩個相鄰 Region 合併為一個。
將數據劃分成 Region 後,TiKV 會盡量保證每個節點上服務的 Region 數量差不多,並以 Region 為單位做 Raft 的複製和成員管理。
Key-Value 映射數據
由於 TiDB 是通過 TiKV 來存儲的,但是關係型資料庫中,一個表可能有很多列,這就需要將一行中各列數據映射成一個 (Key, Value) 鍵值對。
比如有這樣一張表:
CREATE TABLE User (
ID int,
Name varchar(20),
Role varchar(20),
Age int,
PRIMARY KEY (ID),
KEY idxAge (Age)
);
表中有三行數據:
1, "TiDB", "SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30
那麼這些數據在 TiKV 上存儲的時候會構建 key。對於主鍵和唯一索引會在每條數據帶上表的唯一 ID,以及表中數據的 RowID。如上面的三行數據會構建成:
t10_r1 --> ["TiDB", "SQL Layer", 10]
t10_r2 --> ["TiKV", "KV Engine", 20]
t10_r3 --> ["PD", "Manager", 30]
其中 key 中 t 是表示 TableID 前綴,t10 表示表的唯一ID 是 10;key 中 r 表示 RowID 前綴,r1 表示這條數據 RowID 值是1,r2 表示 RowID 值是2 等等。
對於不需要滿足唯一性約束的普通二級索引,一個鍵值可能對應多行,需要根據鍵值範圍查詢對應的 RowID。上面的數據中 idxAge 這個索引會映射成:
t10_i1_10_1 --> null
t10_i1_20_2 --> null
t10_i1_30_3 --> null
上面的 key 對應的意思就是:t表ID_i索引ID_索引值_RowID 。
可以看到無論是唯一索引還是二級索引,都是構建 key 的映射規則來查找數據,比如這樣的一個 SQL:
select count(*) from user where name = "TiDB"
where 條件沒有走索引,那麼需要讀取表中所有的數據,然後檢查 name 欄位是否是 TiDB,執行流程就是:
- 構造出 Key Range ,也就是需要被掃描的數據範圍,這個例子中是全表,所以 Key Range 就是
[0, MaxInt64); - 掃描 Key Range 讀取數據;
- 對讀取到的數據進行過濾,計算
name = "TiDB"這個表達式,如果為真,則向上返回這一行,否則丟棄這一行數據; - 計算
Count(*):對符合要求的每一行,累計到Count(*)的結果上面。
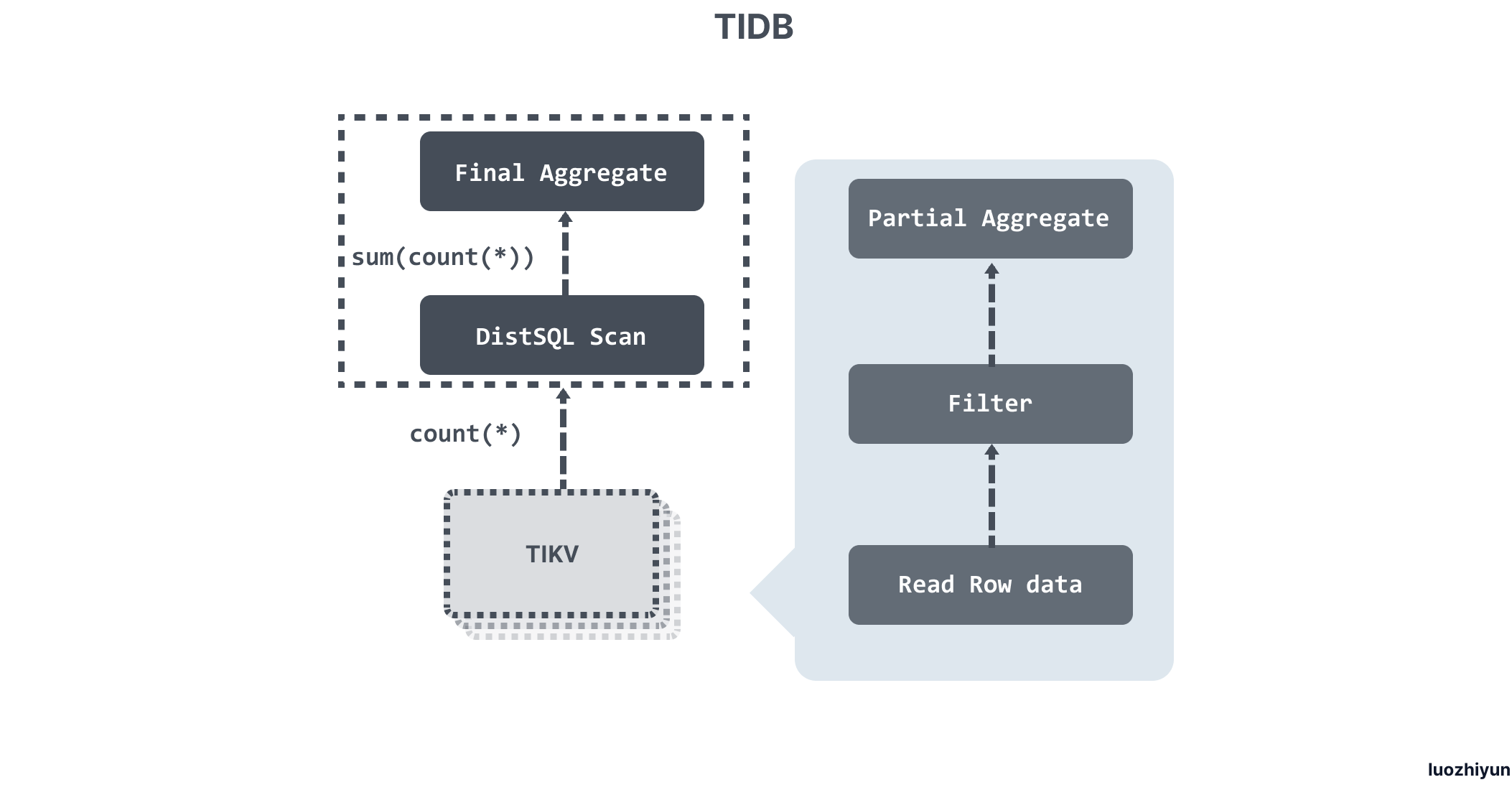
SQL 執行過程

- Parser & validator:將文本解析成結構化數據,也就是抽象語法樹 (AST),然後對 AST 進行合法性驗證;
- Logical Optimize 邏輯優化:對輸入的邏輯執行計劃按順序應用一些優化規則,從而使整個邏輯執行計劃變得更好。例如:關聯子查詢去關聯、Max/Min 消除、謂詞下推、Join 重排序等;
- Physical Optimize 物理優化:用來為上一階段產生的邏輯執行計劃制定物理執行計劃。優化器會為邏輯執行計劃中的每個運算元選擇具體的物理實現。對於同一個邏輯運算元,可能有多個物理運算元實現,比如
LogicalAggregate,它的實現可以是採用哈希演算法的HashAggregate,也可以是流式的StreamAggregate; - Coprocessor :在 TiDB 中,計算是以 Region 為單位進行,SQL 層會分析出要處理的數據的 Key Range,再將這些 Key Range 根據 PD 中拿到的 Region 資訊劃分成若干個 Key Range,最後將這些請求發往對應的 Region,各自 Region 對應的 TiKV 數據並計算的模組稱為 Coprocessor ;
- TiDB Executor:TiDB 會將 Region 返回的數據進行合併匯總結算;
事務
作為分散式資料庫,分散式事務是既是重要特性之一。TiDB 實現了快照隔離級別的分散式事務,支援悲觀事務和樂觀事務。
- 樂觀事務:事務間沒有衝突或允許事務因數據衝突而失敗;追求極致的性能。
- 悲觀事務:事務間有衝突且對事務提交成功率有要求;因為加鎖操作的存在,性能會比樂觀事務差。
樂觀事務
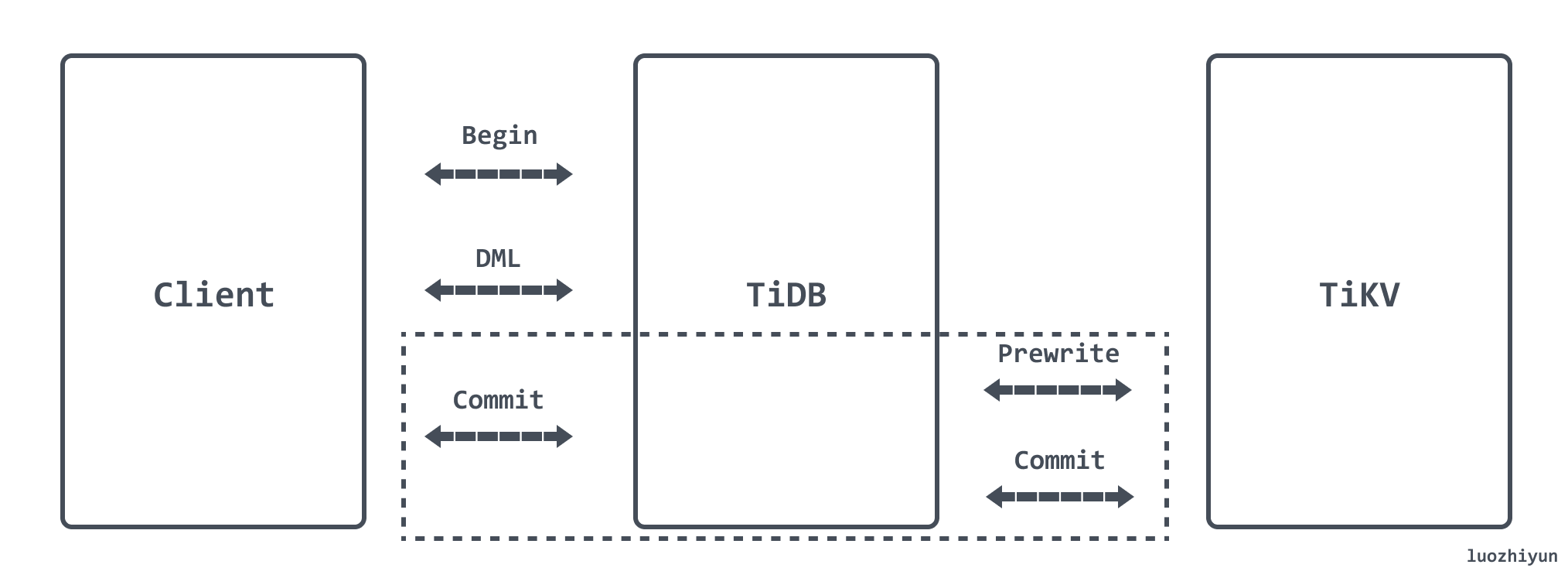
TiDB 使用兩階段提交(Two-Phase Commit)來保證分散式事務的原子性,分為 Prewrite 和 Commit 兩個階段:
- Prewrite
- TiDB 從當前要寫入的數據中選擇一個 Key 作為當前事務的 Primary Key;
- TiDB 並發地向所有涉及的 TiKV 發起 Prewrite 請求;
- TiKV 檢查數據版本資訊是否存在衝突,符合條件的數據會被加鎖;
- TiDB 收到所有 Prewrite 響應且所有 Prewrite 都成功;
- Commit
- TiDB 向 TiKV 發起第二階段提交;
- TiKV 收到 Commit 操作後,檢查鎖是否存在並清理 Prewrite 階段留下的鎖;
使用樂觀事務模型時,在高衝突率的場景中,事務很容易提交失敗。
悲觀事務
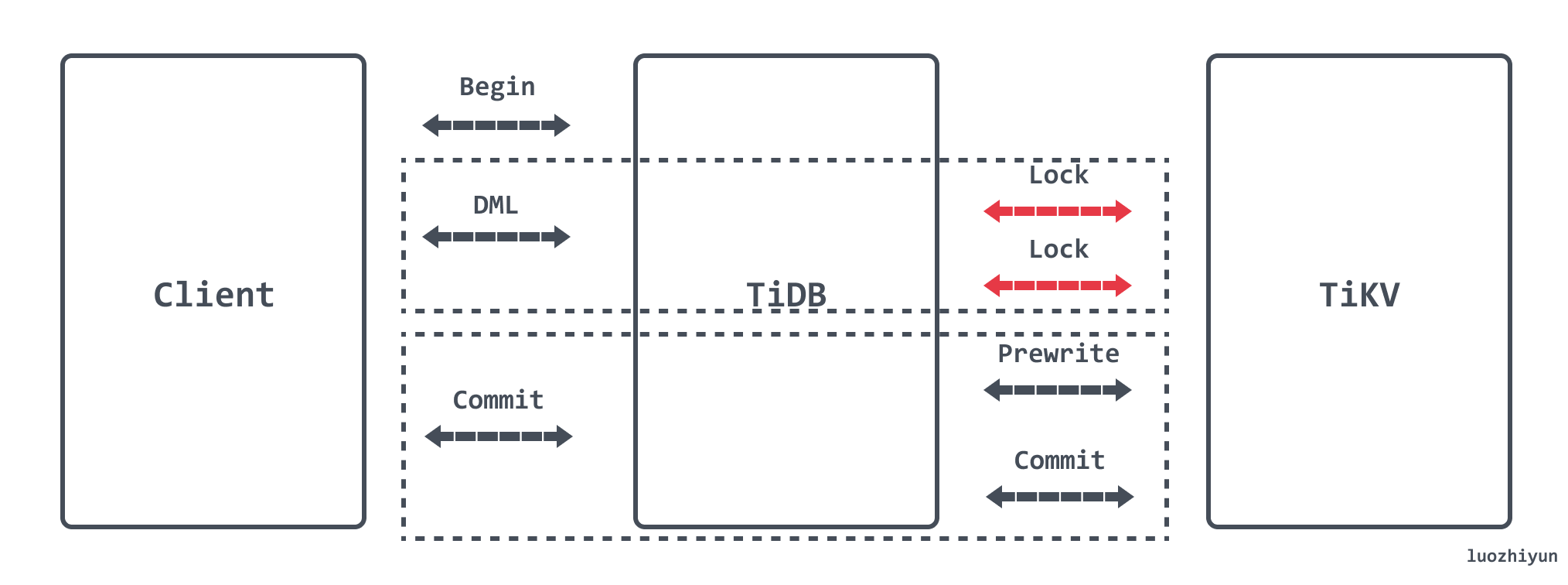
悲觀事務在 Prewrite 之前增加了 Acquire Pessimistic Lock 階段用於避免 Prewrite 時發生衝突:
- 每個 DML 都會加悲觀鎖,鎖寫到 TiKV 里;
- 悲觀事務在加悲觀鎖時檢查各種約束;
- 悲觀鎖不包含數據,只有鎖,只用於防止其他事務修改相同的 Key,不會阻塞讀;
- 提交時悲觀鎖的存在保證了 Prewrite 不會發生 Write Conflict,保證了提交一定成功;
總結
這篇文章當中我們大致了解到了,作為一個分散式的關係型資料庫 TiDB 它的整體架構是怎樣的。如何通過 Key-Value 的形式存儲數據,它的 SQL 是如何執行的,以及作為關係型資料庫的事務支援度怎麼樣。
Reference
//www.infoq.cn/article/mfttecc4y3qc1egnnfym
//pingcap.com/cases-cn/user-case-webank/
//docs.pingcap.com/zh/tidb/stable/tidb-architecture
//pingcap.com/blog-cn/tidb-internal-1/
//pingcap.com/blog-cn/tidb-internal-2/
//pingcap.com/blog-cn/tidb-internal-3/
//docs.pingcap.com/zh/tidb/stable/tidb-best-practices