embedding技術
- 2019 年 10 月 3 日
- 筆記
word2vec
Word2Vec是一個可以將語言中的字詞轉換為低維、稠密、連續的向量表達(Vector Respresentations)的模型,其主要依賴的假設是Distributional Hypothesis(1954年由Harris提出分布假說,即上下文相似的詞,其語義也相似;我的理解就是詞的語義可以根據其上下文計算得出)
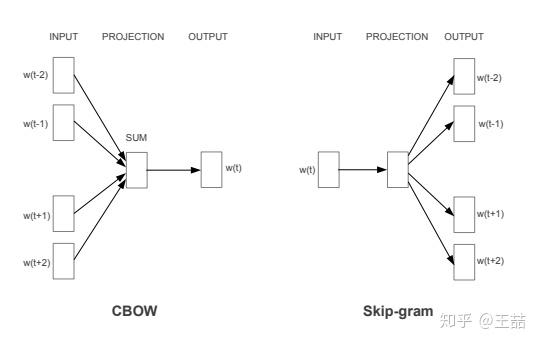
Word2vec主要分為CBOW(Continuous Bag of Words)和Skip Gram兩種模式,其中CBOW是從原始數據推測目標字詞;而Skip-Gram是從目標字詞推測原始語句,其中CBOW對小型數據比較合適,而Skip-Gram在大型預料中表現得更好。
負取樣
負取樣的基本思想是用取樣一些負例的方式近似代替遍歷整個辭彙。
目標函數
[ J^h( theta ) = log sigma( Delta S_{theta}(w,h)) + k log(1 – sigma(Delta S_{theta}(w,h))) ]
(其中h=w_1,…,w_n為上下文詞序列)
(P_n(w)代表負樣本分布為,w是抽樣詞)
(P_d(w)代表正樣本(真實數據)分布)
$ sigma(x)=frac{1}{1+e^{-x}}是sigmoid函數 $
$ theta 代表模型參數$
(k 代表負樣本與正樣本的比例)
(P^h( D=1|w,theta ) = frac{P^h_{theta}(w)}{P^h_{theta}(w)+kP_n(w)}=sigma(Delta S_{theta}(w,h)) 代表在給定上下文h,參數theta情況下w是正樣本的概率)
(其中S_{theta}(w,h)=hat{q}(h)^T q_w + b_w = (sum^n_{i=1}c_i bigodot r_{w_i})^T q_w + b_w)
(hat{q}(h) = sum^n_{i=1}c_i bigodot r_{w_i}是上下文詞向量的線性加權,代表對目標詞的估計值)
(c_i代表上下文詞在位置i的權重向量)
(r_{w_i}代表上下文詞i的詞向量表示)
(q_w代表目標詞的詞向量表示)
(b_w代表上下文無關的偏置項)
反向梯度
$ frac{partial }{partial theta} J^{h,w}(theta) = (1-sigma(Delta S_{theta}(w,h))) frac{partial }{partial theta}logP^h_theta(w) – sum^k_{i=1}[sigma(Delta S_{theta}(w,h))frac{partial }{partial theta}logP^h_theta(x_i)]$
公式中使用k個噪音樣本的詞向量加和來代替詞典全部辭彙的加和,所以NCE的訓練時間只線性相關於負樣本個數,與詞典大小無關。
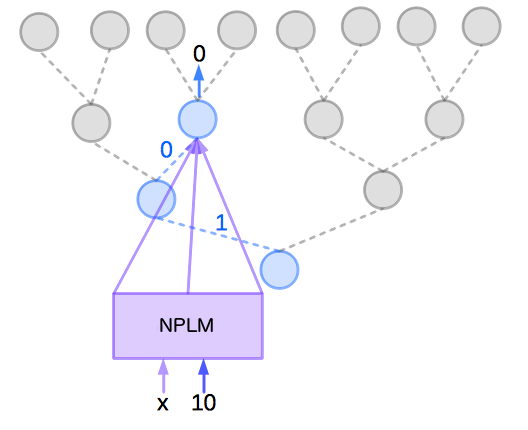
層次softmax
Hierarchical Softmax中不更新每個詞的輸出詞向量,更新的是二叉樹(哈夫曼樹)上節點對應的向量。代價由?(|?|)變為?((???_2|?|))
NPLM的目標函數和反向梯度
目標函數
$P( Y = y | X = x) = prod_{j=1}^{m}P(b_{j}(y) | b_{j-1}(y),b_{j-2}(y),…,b_{1}(y), X=x)
$
其中((b_{j−1}(y),b_{j−2}(y),…,b_1(y)))為長度小於m的二進位表示,即是在二元分類樹中的分支結點。
反向梯度
GNN(圖神經網路)
deepwalk
一種可以學習到結點間局部結構相似性的圖表徵演算法;

node2vec
加入了Alias sample(別名取樣),可以對加權圖做word2vec


附錄
- 【word2vec的提出】Efficient Estimation of Word Representations in Vector Space
- 【句向量段向量表示】Distributed Representations of Sentences and Documents
- 【層次softmax提出】Hierarchical Probabilistic Neural Network Language Model
- 【負取樣提出】Learning word embeddings efficiently with noise-contrastive estimation
- 詞表徵 2:word2vec、CBoW、Skip-Gram、Negative Sampling、Hierarchical Softmax
- Hierarchical Probabilistic Neural Network Language Model (Hierarchical Softmax)
- A Neural Probabilistic Language Model
- DeepWalk: Online Learning of Social Representations
- Alias sample(別名取樣)
- node2vec: Scalable Feature Learning for Networks
