MATLAB導入txt和excel文件技巧匯總:批量導入、單個導入
- 2021 年 7 月 4 日
- 筆記
在使用MATLAB的時候,想必各位一定會遇到導入數據的問題。如果需要導入的數據其數據量巨大的話,那麼在MATLAB編輯器中將這些數據複製粘貼進來,顯然會在編輯器中佔據巨大的篇幅,這是不明智的。
一般來說儲存這些數據的文件有兩種形式:
- txt文件
- excel表格
針對這兩種類型的文件,需要使用兩個不同的函數。
就導入txt文件來說,個人習慣使用importdata這個函數。
@
導入txt文件
01 | 導入全是數字類型的txt文件(一)
如果導入的txt文件中,儲存的數據全是數字類型的,且同一行的兩個數字之間使用空格或者製表符進行分隔。這種形式的txt文件如下所示。

儲存這種形式數據的txt文件直接使用如下程式碼即可。
present01=importdata('present01.txt');
在MATLAB運行之後的結果如下:

02 | 導入全是數字類型的txt文件(二)
如果數據不像剛才給出的數據那麼規整,那麼就不能繼續使用上面的程式碼了
如果txt文件儲存如下的數據:
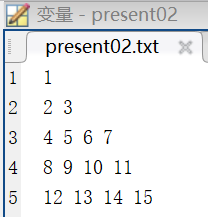
很明顯這個txt文件,第一行只有1,第二行有2和3,第三行有4、5、6和7,第四行有8、9、10和11,第五行有12、13、14和15。
如果我們繼續使用上面的程式碼,看看能否成功導入數據。
present02=importdata('present02.txt');
在MATLAB運行之後結果如下,是一個15行1列的矩陣,這個很明顯和我們想要的形式不太一樣。
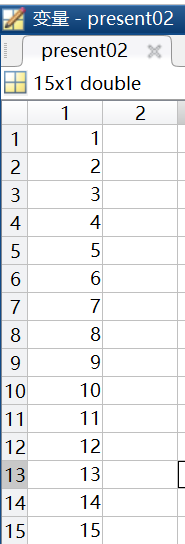
可以發現前兩行的數據個數與後三行的數據個數不同,所以在實際導入的時候需要分開導入,這時可以使用如下程式碼導入present02.txt文件。
filename='present02.txt'; %文件名
delimiterIn = ' '; %列分隔符
headerlinesIn = 2; %讀取從第 headerlinesIn+1 行開始的數值數據
present02=importdata(filename,delimiterIn,headerlinesIn);
dataset=present02.data; %導出的3行以後的數據,即3行4列的矩陣
parameters=present02.textdata; %導出的2行以前的數據,即2行1列的元胞數組
- filename是文件名
- delimiterIn是列分隔符,也就是同一行的兩個數據之間是如何分隔的,可以是空格,也可以是製表符,也可以是逗號
- headerlinesIn表示讀取從第 headerlinesIn+1 行開始的數值數據,因為前兩行的數據個數與後三行的數據個數不同,所以這裡headerlinesIn = 2,即從讀取從第 3行開始的數值數據。
在MATLAB運行之後的結果如下,是一個結構體,其中包括一個3行4列的矩陣data,和一個2行1列的元胞數組textdata。使用變數dataset儲存這個3行4列的矩陣,使用parameters儲存這個2行1列的元胞數組。

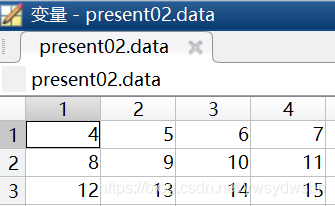
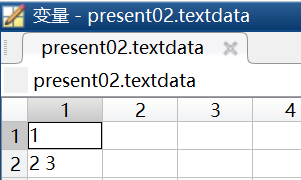
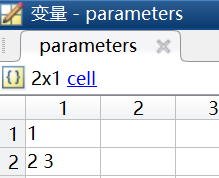
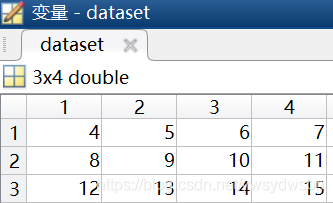
其中這個3行4列的矩陣data就是後三行的數據,這個2行1列的元胞數組textdata就是前兩行的數據。
其實在MATLAB中建議不到萬不得已的時候盡量不用元胞數組cell,因為元胞數組在處理數據時不方便。但這個txt文件由於每行的數據個數不同,所以我們沒有辦法將其導入為一個5行4列的矩陣,我們才萬不得已將前兩行數據導入為元胞數組,後三行數據導入為3行4列的矩陣。
03 | 導入全是數字類型的txt文件(二)拓展
在上述程式碼中將headerlinesIn設為5,導入的結果
filename='present02.txt'; %文件名
delimiterIn = ' '; %列分隔符
headerlinesIn = 5; %讀取從第 headerlinesIn+1 行開始的數值數據
present02=importdata(filename,delimiterIn,headerlinesIn);
在MATLAB運行之後的結果如下,是一個5行1列的元胞數組。
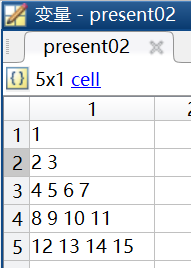
因為一共只有5行數據,而又將headerlinesIn設為5,所以此時讀取從第6行開始的數值數據,這句話包含兩層意思:1)讀取從第6行開始的數值數據,在present02.txt文件中第6行沒有數據,所以沒有將數據以矩陣的形式導入進來。2)讀取第5行之前的非數值數據,然後用元胞數組cell的形式進行儲存。
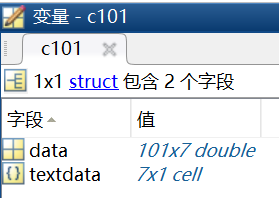
04 | 導入數字和字母混合類型的txt文件
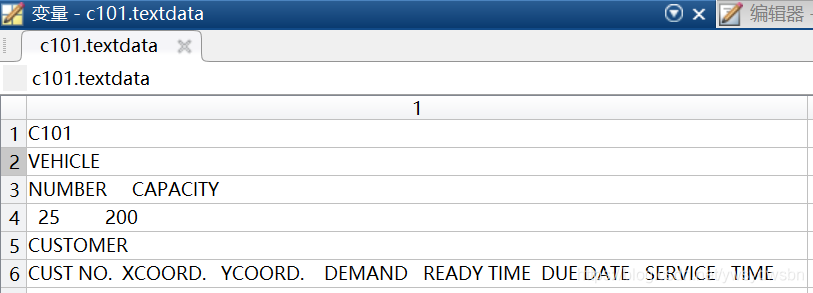
比如說現在導入標準的solomon測試算例,前8行中既有數字又有字母,且每行數據個數不同。
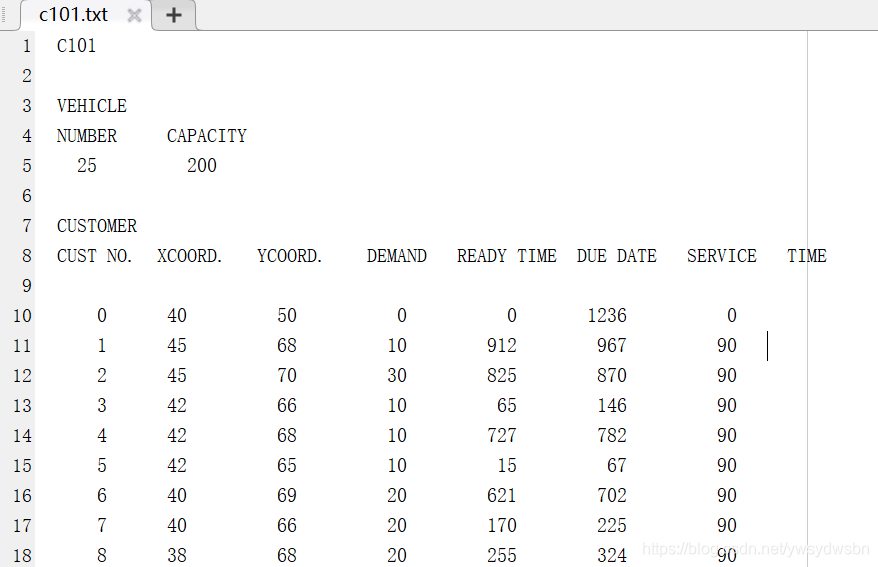
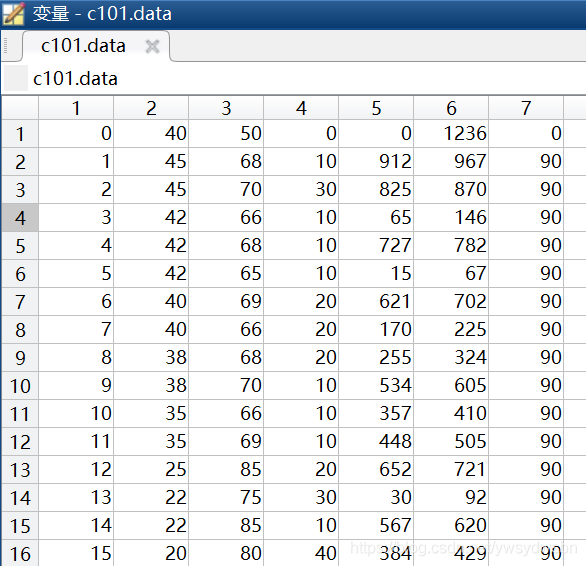
觀察發現,第10行以後的數據是一個101行7列的規整的數據。因此,可以將headerlinesIn設為9,具體的程式碼如下:
filename = 'c101.txt'; %文件名
delimiterIn = ' '; %列分隔符
headerlinesIn =9; %讀取從第 headerlinesIn+1 行開始的數值數據
c101=importdata(filename,delimiterIn,headerlinesIn);
row4=c101.textdata{4,1};
len=length(row4);
dataset=c101.data; %導出的10行以後的數據,即101行7列的矩陣
parameters=c101.textdata; %導出的9行以前的數據,即7行1列的元胞數組
在MATLAB運行之後的結果如下:
05 | 導入同一個文件中的多個txt 文件
matlab中給我們提供了dir這個函數,十分方便。這裡是讀取所有txt文件,所以是dir('父目錄路徑\*.txt')
%讀取該目錄下的所有txt文件
% namelist = dir('C:\Users\Administrator\Desktop\xxx\*.txt');
% 讀取後namelist 的屬性有
% name -- filename
% date -- modification date
% bytes -- number of bytes allocated to the file
% isdir -- 1 if name is a directory and 0 if not
%通過字元串拼接,獲取絕對路徑可以直接用[],也可以用strcat()函數
path = 'C:\Users\Administrator\Desktop\xxx\';
namelist = dir([path,'*.txt']);
l = length(namelist);
P = cell(1,l);%定義一個細胞數組,用於存放所有txt文件
for i = 1:l
namelist(i).name;%這裡獲得的只是該路徑下的文件名,如1.txt是相對路徑
filename{i} = [path,namelist(i).name];%通過字元串拼接獲得的就是絕對路徑了
P{1,i} = load(filename{i});
end
面對多個 .txt 文件的依次讀入,且文件名按一定的規律命名,如:filename1.txt,filename2.txt,… 。是純數字數據類型的文本(不摻雜字元類型)依次讀入,我們可以將其存儲為cell數據類型,以便於後面關於數據的操作。在這裡我們舉一個例子:假如有10個 .txt 文件,我們把這些數據讀入並存儲為cell數據類型。我們可以使用循環依次讀入文件,Matlab 程式如下:
data = cell(1,10); %建立細胞存儲空間
for i = 1:10
g = ['filename' num2str(i) '.txt'];
data(1,i) = {textread(g)};%讀入 .txt 文件置於 data 細胞中
end
對於讀入的cell數據的顯示,我們可以採用 : data{m,n}(p,q); %對存入的cell數據進行顯示
在 .txt 文件中摻雜著字母+數字 類型的,我們同樣也可以存儲為struct 結構體數據的類型。這裡我們再舉一個列子。比如:兩幅帶有英文+數字的 .txt文件。我們將其讀入並存儲為結構體類型。
for i=1:2
str=strcat('filename',num2str(i),'.txt');
hh{1}{i}=importdata(str);
end
對於讀入的struct數據的顯示,我們可以採用:pp.textdata(2)%數據顯示
導入Excel文件
01 | 用xlsread函數讀取一個Excel文件
-
num=xlsread(filename)
filename是單引號括起來的帶路徑的文件名,函數直接讀取filename所指文件的sheet1中的數據區域存儲到雙精度矩陣num中;其中,數據區域的選取規則是:對表格前幾個含有非數值的行(列)直接忽略,不算入數據區域。 -
num = xlsread(filename, -1)
輸入後matlab將會打開相應的exel文件,用滑鼠選擇需要導入的數據區域,可以切換到想要的sheet。 -
num = xlsread(filename, sheet)
其中sheet用來指定讀入excel文件的第幾個sheet,此時的sheet取值大於1的整數。 -
num = xlsread(filename,sheet, ‘range’)
其中range指定一個矩形的區域,用單引號括起來;例如:’D2:H4‘代表以D2和H4為對角定點的矩形域;
注意當excel中有合併單元格時,任何一個合併前的單元格的名字(比如D1)都會指代整個合併後的單元格,而將整個單元格讀入,所以為了避免麻煩,盡量避免在需要讀入的表格中合併單元格。
例如:將讀取D盤下的一個文件路徑為:D:/test/daxia.xls
num = xlsread('d:/test/daxia.xls',2,'D2:H4')讀取sheet2的D2:H4區域數據
如果要進行互動式的選擇用:num= xlsread('d:/test/daxia.xls',-1)
02 | 批量的文件要讀取
首先將多個文件進行批量重命名例如daxia1.xls,daxia2.xls,daxia3.xls,…
然後用循環的方式實現:
for i=1:100
filename=['d:/test/daxia',num2str(i),'.xls'];
num=xlsread(filename)
end
資源傳送門
- 關注【做一個柔情的程式猿】公眾號
- 在【做一個柔情的程式猿】公眾號後台回復 【python資料】【2020秋招】 即可獲取相應的驚喜哦!
「❤️ 感謝大家」
- 點贊支援下吧,讓更多的人也能看到這篇內容(收藏不點贊,都是耍流氓 -_-)
- 歡迎在留言區與我分享你的想法,也歡迎你在留言區記錄你的思考過程

