語音訊號的梅爾頻率倒譜係數(MFCC)的原理講解及python實現
- 2019 年 10 月 3 日
- 筆記
梅爾倒譜係數(MFCC)
梅爾倒譜係數(Mel-scale FrequencyCepstral Coefficients,簡稱MFCC)。依據人的聽覺實驗結果來分析語音的頻譜,
MFCC分析依據的聽覺機理有兩個
第一Mel scale:人耳感知的聲音頻率和聲音的實際頻率並不是線性的,有下面公式
$$f_{mel}=2595*log _{10}(1+frac{f}{700})$$
$$f = 700 (10^{f_{mel}/2595} – 1)$$
式中$f_{mel}$是以梅爾(Mel)為單位的感知頻域(簡稱梅爾頻域),$f$是以$Hz$為單位的實際語音頻率。$f_{mel}$與$f$的關係曲線如下圖所示,若能將語音訊號的頻域變換為感知頻域中,能更好的模擬聽覺過程的處理。

第二臨界帶(Critical Band):把進入人耳的聲音頻率用臨界帶進行劃分,將語音在頻域上就被劃分成一系列的頻率群,組成了濾波器組,即Mel濾波器組。
研究表明,人耳對不同頻率的聲波有不同的聽覺敏感度。從200Hz到5000Hz的語音訊號對語音的清晰度影響較大。兩個響度不等的聲音作用於人耳時,則響度較高的頻率成分的存在會影響到對響度較低的頻率成分的感受,使其變得不易察覺,這種現象稱為掩蔽效應。
由於頻率較低的聲音(低音)在內耳蝸基底膜上行波傳遞距離大於頻率較高的聲音(高音),因此低音容易掩蔽高音。低音掩蔽的臨界頻寬較高頻要小。所以,人們從低頻到高頻這一段頻帶內按臨界頻寬的大小由密到疏安排一組帶通濾波器,對輸入訊號進行濾波。將每個帶通濾波器輸出的訊號能量作為訊號的基本特徵,對此特徵經過進一步處理後就可以作為語音的輸入特徵。由於這種特徵不依賴於訊號的性質,對輸入訊號不做任何的假設和限制,又利用了聽覺模型的研究成果。因此,這種參數比基於聲道模型的LPCC相比具有更好的魯棒性,更符合人耳的聽覺特性,而且當信噪比降低時仍然具有較好的識別性能。
求MFCC的步驟
- 將訊號幀化為短幀
- 對於每個幀,計算每幀語音的功率譜(周期圖估計)
- 將mel濾波器組應用於功率譜,求濾波器組的能量,將每個濾波器中的能量相加
- 取所有濾波器組能量的對數
- DCT變換

MFCC的提取過程
預處理
預處理包括預加重、分幀、加窗函數。假設我們的語音訊號取樣頻率為8000Hz,語音數據在這裡獲取
import numpy import scipy.io.wavfile from scipy.fftpack import dct sample_rate, signal = scipy.io.wavfile.read('OSR_us_000_0010_8k.wav') signal = signal[0:int(3.5 * sample_rate)] # 我們只取前3.5s

時域中的語音訊號
預加重
預加重濾波器在以下幾個方面很有用:
- 平衡頻譜,因為高頻通常與較低頻率相比具有較小的幅度,
- 避免在傅里葉變換操作期間的數值問題和
- 改善訊號 – 雜訊比(SNR)
- 消除發聲過程中聲帶和嘴唇的效應,來補償語音訊號受到發音系統所抑制的高頻部分,也為了突出高頻的共振峰。
預加重處理其實是將語音訊號通過一個高通濾波器:
$$y(t) = x(t) – alpha x(t-1)$$
其中濾波器係數(α)的通常為0.95或0.97,這裡取pre_emphasis =0.97:
emphasized_signal = numpy.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])

預加重後的時域訊號
分幀
在預加重之後,我們需要將訊號分成短時幀。因此在大多數情況下,語音訊號是非平穩的,對整個訊號進行傅里葉變換是沒有意義的,因為我們會隨著時間的推移丟失訊號的頻率輪廓。語音訊號是短時平穩訊號。因此我們在短時幀上進行傅里葉變換,通過連接相鄰幀來獲得訊號頻率輪廓的良好近似。
將訊號幀化為20-40 ms幀。25毫秒是標準的frame_size = 0.025。這意味著8kHz訊號的幀長度為0.025 * 8000 = 200個取樣點。幀移通常為10m sframe_stride = 0.01(80個取樣點),為了避免相鄰兩幀的變化過大,因此會讓兩相鄰幀之間有一段重疊區域,此重疊區域包含了120個取樣點,通常約為每幀語音的1/2或1/3。第一個語音幀0開始,下一個語音幀從160開始,直到到達語音文件的末尾。如果語音文件沒有劃分為偶數個幀,則用零填充它以使其完成。
frame_length, frame_step = frame_size * sample_rate, frame_stride * sample_rate # 從秒轉換為取樣點 signal_length = len(emphasized_signal) frame_length = int(round(frame_length)) frame_step = int(round(frame_step)) # 確保我們至少有1幀 num_frames = int(numpy.ceil(float(numpy.abs(signal_length - frame_length)) / frame_step)) pad_signal_length = num_frames * frame_step + frame_length z = numpy.zeros((pad_signal_length - signal_length)) # 填充訊號,確保所有幀的取樣數相等,而不從原始訊號中截斷任何取樣 pad_signal = numpy.append(emphasized_signal, z) indices = numpy.tile(numpy.arange(0, frame_length), (num_frames, 1)) + numpy.tile(numpy.arange(0, num_frames * frame_step, frame_step), (frame_length, 1)).T frames = pad_signal[indices.astype(numpy.int32, copy=False)]
加窗
將每一幀乘以漢明窗,以增加幀左端和右端的連續性。抵消fft假設的數據是無限的,並減少頻譜泄漏。
假設分幀後的訊號為S(n), n=0,1…,N-1, N為窗口長度,那麼乘上漢明窗
$${S}'(n)=S(n)times W(n)$$
後 ,漢明窗W(n)形式如下:
$$Wleft( n,a right)=left( 1-a right)-atimes cos left( frac{2pi n}{N-1} right),0le nle N-1$$

frames *= numpy.hamming(frame_length) # frames *= 0.54 - 0.46 * numpy.cos((2 * numpy.pi * n) / (frame_length - 1)) # 內部實現
FFT
由於訊號在時域上的變換通常很難看出訊號的特性,所以通常將它轉換為頻域上的能量分布來觀察,不同的能量分布,就能代表不同語音的特性。對分幀加窗後的各幀訊號進行做一個N點FFT來計算頻譜,也稱為短時傅立葉變換(STFT),其中N通常為256或512,NFFT=512;
$$S_i(k)=sum_{n=1}^{N}s_i(n)e^{-j2pi kn/N} 1le k le K$$
mag_frames = numpy.absolute(numpy.fft.rfft(frames, NFFT)) # fft的幅度
能量譜
計算功率譜(周期圖),對語音訊號的頻譜取模平方(取對數或者去平方,因為頻率不可能為負,負值要捨去)得到語音訊號的譜線能量。
$$P = frac{|FFT(x_i)|^2}{N}$$
其中,$X_i$是訊號X的第$i$幀,這可以用以下幾行來實現:
pow_frames = ((1.0 / NFFT) * ((mag_frames) ** 2)) # 功率譜
使用Mel刻度濾波器組過濾
計算通過Mel濾波器,將功率譜通過一組Mel刻度(這裡取40個)的三角濾波器組提取頻寬。
這個Mel濾波器組就像人類的聽覺感知系統(耳朵),人耳只關注某些特定的頻率分量(人的聽覺對頻率是有選擇性的)。它對不同頻率訊號的靈敏度是不同的,換言之,它只讓某些頻率的訊號通過,而壓根就直接無視它不想感知的某些頻率訊號。但是這些濾波器在頻率坐標軸上卻不是統一分布的,在低頻區域有很多的濾波器,他們分布比較密集,但在高頻區域,濾波器的數目就變得比較少,分布很稀疏。
我們可以用下面的公式,在語音頻率和Mel頻率間轉換
$$f_{mel}=2595*log _{10}(1+frac{f}{700})$$
$$f = 700 (10^{f_{mel}/2595} – 1)$$
定義一個有M個三角濾波器的濾波器組(濾波器的個數和臨界帶的個數相近),中心頻率為f(m) ,中心頻率響應為1,並且朝向0線性減小,直到它達到響應為0的兩個相鄰濾波器的中心頻率,如下圖所示。M通常取22-40,26是標準,本文取nfilt = 40。各f(m)之間的間隔隨著m值的增大而增寬,如圖所示:
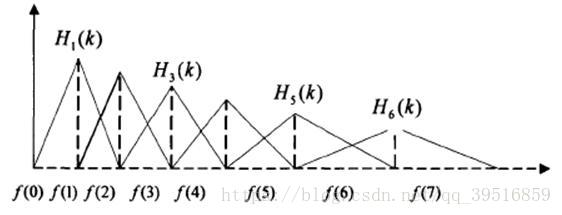
在Mel-Scale上的濾波器組
這可以通過以下等式建模,三角濾波器的頻率響應定義為:
$$H_m(k) =
begin{cases}
hfill 0 hfill & k < f(m – 1) \
\
hfill dfrac{k – f(m – 1)}{f(m) – f(m – 1)} hfill & f(m – 1) leq k < f(m) \
\
hfill 1 hfill & k = f(m) \
\
hfill dfrac{f(m + 1) – k}{f(m + 1) – f(m)} hfill & f(m) < k leq f(m + 1) \
\
hfill 0 hfill & k > f(m + 1) \
end{cases}$$
對於FFT得到的幅度譜,分別跟每一個濾波器進行頻率相乘累加,得到的值即為該幀數據在在該濾波器對應頻段的能量值。如果濾波器的個數為22,那麼此時應該得到22個能量值
low_freq_mel = 0 high_freq_mel = (2595 * numpy.log10(1 + (sample_rate / 2) / 700)) # 將Hz轉換為Mel mel_points = numpy.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # 使得Mel scale間距相等 hz_points = (700 * (10**(mel_points / 2595) - 1)) # 將Mel轉換為Hz bin = numpy.floor((NFFT + 1) * hz_points / sample_rate) fbank = numpy.zeros((nfilt, int(numpy.floor(NFFT / 2 + 1)))) for m in range(1, nfilt + 1): f_m_minus = int(bin[m - 1]) # 左 f_m = int(bin[m]) # 中 f_m_plus = int(bin[m + 1]) # 右 for k in range(f_m_minus, f_m): fbank[m - 1, k] = (k - bin[m - 1]) / (bin[m] - bin[m - 1]) for k in range(f_m, f_m_plus): fbank[m - 1, k] = (bin[m + 1] - k) / (bin[m + 1] - bin[m]) filter_banks = numpy.dot(pow_frames, fbank.T) filter_banks = numpy.where(filter_banks == 0, numpy.finfo(float).eps, filter_banks) # 數值穩定性 filter_banks = 20 * numpy.log10(filter_banks) # dB
訊號的功率譜經過濾波器組後,得到的譜圖為:

訊號的頻譜圖
如果經過Mel scale濾波器組得到的頻譜是所需的特徵,那麼我們可以跳過均值歸一化。
能量值取對數
由於人耳對聲音的感知並不是線性的,用log這種非線性關係更好描述。取完log以後才可以進行倒譜分析。
$$sleft( m right)=ln left( {{sumlimits_{K=0}^{N-1}{left| {{X}_{a}}left( k right) right|}}^{2}}{{H}_{m}}left( k right) right),0le mle M$$
離散餘弦變換(DCT)
前一步驟中計算的濾波器組係數是高度相關的,這在一些機器學習演算法中可能是有問題的。因此,我們可以應用離散餘弦變換(DCT)去相關濾波器組係數併產生濾波器組的壓縮表示。通常,對於自動語音識別(ASR),保留所得到的倒頻譜係數2-13,其餘部分被丟棄; num_ceps = 12。丟棄其他係數的原因是它們代表濾波器組係數的快速變化,並且這些精細的細節對自動語音識別(ASR)沒有貢獻。
$$C(n)=sumlimits_{m=0}^{N-1}{s( m)cos( frac{pi n( m-0.5)}{M} )},n=1,2,…,L$$
L階指MFCC係數階數,通常取2-13。這裡M是三角濾波器個數。
mfcc = dct(filter_banks, type=2, axis=1, norm='ortho')[:, 1 : (num_ceps + 1)] # 保持在2-13
可以將正弦提升器(Liftering在倒譜域中進行過濾。 注意在譜圖和倒譜圖中分別使用filtering和liftering)應用於MFCC以去強調更高的MFCC,其已經聲稱可以改善雜訊訊號中的語音識別。
(nframes, ncoeff) = mfcc.shape n = numpy.arange(ncoeff) lift = 1 + (cep_lifter / 2) * numpy.sin(numpy.pi * n / cep_lifter) mfcc *= lift
由此產生的MFCC:

MFCCs
均值歸一化
如前所述,為了平衡頻譜並改善信噪比(SNR),我們可以簡單地從所有幀中減去每個係數的平均值。
filter_banks -= (numpy.mean(filter_banks, axis=0) + 1e-8)
均值歸一化濾波器組:

歸一化濾波器數組
同樣對於MFCC:
mfcc -= (numpy.mean(mfcc, axis=0) + 1e-8)
均值歸一化MFCC:

標準的MFCC
總結
在這篇文章中,我們探討了計算Mel標度濾波器組和Mel頻率倒譜係數(MFCC)的過程。
到目前為止,計算濾波器組和MFCC的步驟是根據其動機和實現進行討論的。值得注意的是,計算濾波器組所需的所有步驟都是由語音訊號的性質和人類對這些訊號的感知所驅動的。相反,計算MFCC所需的額外步驟是由一些機器學習演算法的限制所驅動的。需要離散餘弦變換(DCT)來去相關濾波器組係數,該過程也稱為白化。特別是,當高斯混合模型 – 隱馬爾可夫模型(GMMs-HMMs)非常受歡迎時,MFCC非常受歡迎,MFCC和GMM-HMM共同演化為自動語音識別(ASR)的標準方式2。隨著深度學習在語音系統中的出現,人們可能會質疑MFCC是否仍然是正確的選擇,因為深度神經網路不太容易受到高度相關輸入的影響,因此離散餘弦變換(DCT)不再是必要的步驟。值得注意的是,離散餘弦變換(DCT)是一種線性變換,因此在語音訊號中丟棄一些高度非線性的資訊是不可取的。
質疑傅里葉變換是否是必要的操作是明智的。鑒於傅立葉變換本身也是線性運算,忽略它並嘗試直接從時域中的訊號中學習可能是有益的。實際上,最近的一些工作已經嘗試過,並且報告了積極的結果。然而,傅立葉變換操作是很難學習的操作,可能會增加實現相同性能所需的數據量和模型複雜性。此外,在進行短時傅里葉變換(stft)時,我們假設訊號在這一短時間內是平穩的,因此傅里葉變換的線性不會構成一個關鍵問題。
用librosa提取MFCC特徵
MFCC特徵是一種在自動語音識別和說話人識別中廣泛使用的特徵。在librosa中,提取MFCC特徵只需要一個函數:
librosa.feature.mfcc(y=None, sr=22050, S=None, n_mfcc=20, dct_type=2, norm='ortho', **kwargs)
參數:
- y:音頻時間序列
- sr:音頻的取樣率
- S:np.ndarray,對數功率梅爾頻譜,這個函數既可以支援時間序列輸入也可以支援頻譜輸入,都是返回MFCC係數。
- n_mfcc:int>0,要返回的MFCC數,scale濾波器組的個數,通常取22~40,本文取40
- dct_type:None, or {1, 2, 3} 離散餘弦變換(DCT)類型。默認情況下,使用DCT類型2。
- norm: None or ‘ortho’ 規範。如果dct_type為2或3,則設置norm =’ortho’使用正交DCT基礎。norm不支援dct_type = 1。
返回:
M:np.ndarray MFCC序列
import librosa y, sr = librosa.load('./train_nb.wav', sr=16000) # 提取 MFCC feature mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=40) print(mfccs.shape) # (40, 65)
繪製頻譜圖
Librosa有顯示頻譜圖波形函數specshow( ):
import matplotlib.pyplot as plt import librosa y, sr = librosa.load('./train_wb.wav', sr=16000) # 提取 mel spectrogram feature melspec = librosa.feature.melspectrogram(y, sr, n_fft=1024, hop_length=512, n_mels=128) logmelspec = librosa.power_to_db(melspec) # 轉換為對數刻度 # 繪製 mel 頻譜圖 plt.figure() librosa.display.specshow(logmelspec, sr=sr, x_axis='time', y_axis='mel') plt.colorbar(format='%+2.0f dB') # 右邊的色度條 plt.title('Beat wavform') plt.show()

參考文獻
MFCC特徵參數提取(一)(基於MATLAB和Python實現)
http://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html
Mel Frequency Cepstral Coefficient (MFCC) tutorial
