MySQL是如何實現事物隔離?
前言
眾所周知,MySQL的在RR隔離級別下查詢數據,是可以保證數據不受其它事物影響,而在RC隔離級別下只要其它事物commit後,數據都會讀到commit之後的數據,那麼事物隔離的原理是什麼?是通過什麼實現的呢?那肯定是通過MVCC機制(
Multi-Version Concurrency Control,即多版本並發控制),這是很多人知道的,但是我之前沒有好好分析過其實現原理,所以寫下此篇博文記錄下!註:MySQL的InnoDB引擎之所以能夠支援高性能的並發性能,就是由於MySQL的MVCC機制(歸功於undo log、Read-View、),但是本篇不對MVCC過多的介紹。
參考資料:《MySQL實戰45講》系列,雖然講解的比較清晰,但是仍然需要理解,比如關於視圖數組部分我認為是相比較而言沒有解釋清楚,所以結合資料與自己見解加以記錄!
一、RC與RR隔離級別
我們分別開啟RC與RR隔離級別實驗說明,首先假設有account賬戶表,在事務ABC開啟前,賬戶中的餘額balance為1,即
select balance from account =1; # 結果為1
1.RR事務隔離級別下查詢結果
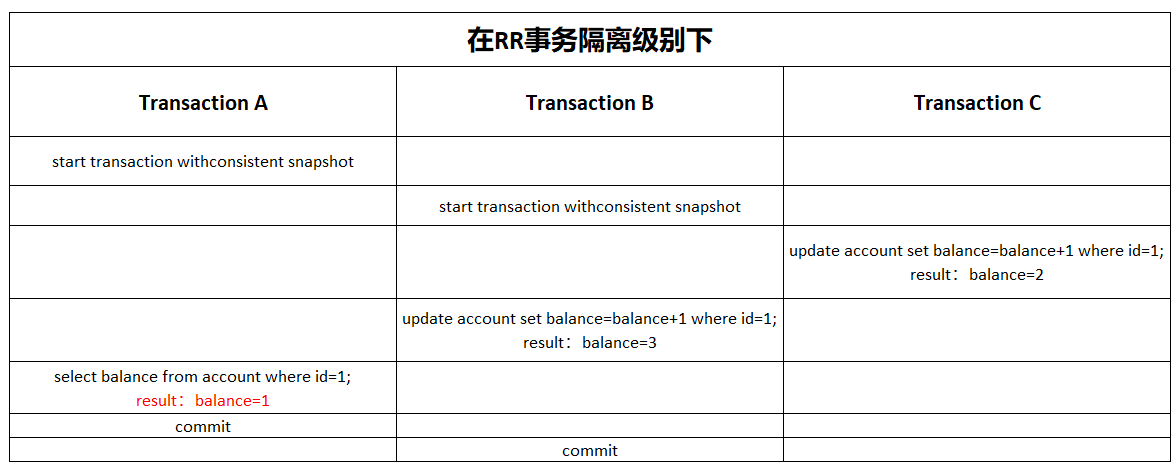
當在RR事務隔離級別分別開啟三個事務,在不同時間段內做如下操作
- 事務A(顯式開啟事務,手動commit提交):查詢餘額
- 事務B(顯式開啟事務,手動commit提交):對id=1的餘額加1
- 事務C(不顯式開啟事務,自動提交):對id=1的餘額加1
我們從時間邏輯上分為三個階段,分析結果
- 第一階段:事務A立馬開始事務,隨後事務B也緊跟著立馬開始事務,然後事務C首先更新balance為2成功,當前balance=2;
- 第二階段:事務B更新balance的值,此時先讀到當前balance最新值為2,隨後set balance=balance+1成功,當前balance=3;
- 第三階段:事務A查詢balance的值,此時的值為1(這裡為什麼等於1呢,是怎麼實現的呢?不應該是當前最新值3嗎?這就是本篇博文討論的重點),最後commit結束事務,緊接著事務B也commit結束事務
最後事務A讀取balance的結果是1,理所當然,RR即為可重複讀,即一個事務在執行過程中看到的數據,總是跟這個事務啟動時看到的數據是一致的,當前事務不管有沒有提交,都不會影響數據,我只需要讀取基於快照的數據即可,這就是快照讀。但是我們要討論的是如何在MVCC機制下實現?
註:begin/start transaction 命令並不是一個事務的起點,在執行到它們之後的第一個操作InnoDB表的語句,事務才真正啟動。如果你想要馬上啟動一個事務,可以使用start transaction with consistent snapshot 這個命令。
1.RC事務隔離級別下查詢結果
同樣地,我們在RC隔離下,開啟事務ABC,觀察事務A最後的balance結果。

最後事務A讀取balance的結果是2,理所當然,RC即為讀可提交,字面意思就是其他事務只要提交後,當前事務我就能立馬讀取到最新當前值,這就是當前讀。但是我們要討論的是如何在MVCC機制下實現?
實際上這是因為實現MVCC時用到的一致性讀視圖,即consistent read view,用於支援RC(Read Committed,讀提交)和RR(Repeatable Read,可重複讀)隔離級別的實現。
三、事務隔離在MVCC的實現
在探討MVCC如何實現事務隔離前,我們需要知道是視圖數組、一致性視圖等概念,才能幫助更好理解MVCC幫助事務實現了隔離。
1.數據行ROW的多版本
InnoDB裡面每個事務有一個唯一的事務ID,叫作transaction id。它是在事務開始的時候向InnoDB的事務系統申請的,是按申請順序嚴格遞增的。
而每行數據也都是有多個版本的。每次事務更新數據的時候,都會生成一個新的數據版本,並且把transaction id賦值給這個數據版本的事務ID,記為row trx_id。同時,舊的數據版本要保留,並且在新的數據版本中,能夠有資訊可以直接拿到它(通過undo_log文件找到)。
也就是說,數據表中的一行記錄,其實可能有多個版本(row),每個版本有自己的row trx_id。
對某一個數據行ROW某個時刻經過三次更新事務的多版本控制流程,畫如下圖加深理解。
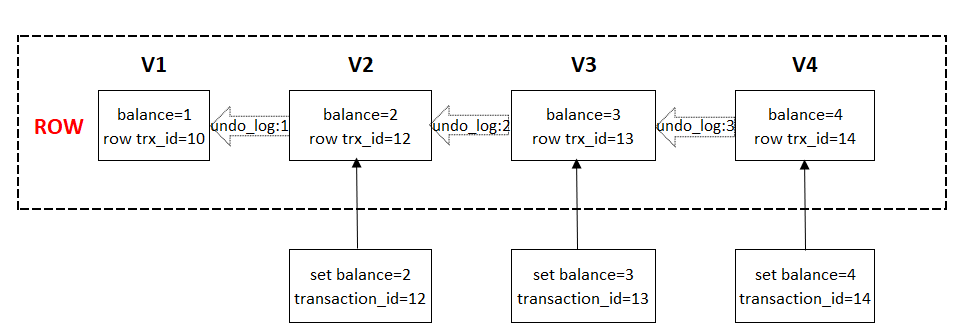
從圖我們可以得到:
- ROW有四個版本V1-V4,即經過三次更新balance後,當前最新版本為V4,當前balance已經更新為4,是最新值
- InnoDB每次更新事務產生的transaction id都會賦值給row trx_id;
- 通過undo_log可以從V4撤回到V1,找到V1版本的balance=1,即undo_log回滾版本。
明白了數據行的ROW的多版本原理與實現後,可以幫助我們理解InnoDB是怎麼定義並創建快照的!
2.視圖數組
下述部分出自資料中的原句,特別是紅色加深部分可能會比較難以理解,所以需要結合自己理解並畫圖
InnoDB是這麼在事務開啟的時候定義快照的,哪些事務的操作我可以忽視,哪么我必須要保存在快照里。可以理解為:一個事務只需要在啟動的時候聲明說,「以我啟動的時刻為準,如果一個數據版本是在我啟動之前生成的,就認;如果是我啟動以後才生成的,我就不認,我必須要找到它的上一個版本」。
在實現上, InnoDB為每個事務構造了一個數組,用來保存這個事務啟動瞬間,當前正在「活躍」的所有事務ID。「活躍」指的就是,啟動了但還沒提交。數組裡面事務ID的最小值記為低水位,當前系統裡面已經創建過的事務ID的最大值加1記為高水位。這個視圖數組和高水位,就組成了當前事務的一致性視圖(read-view)。
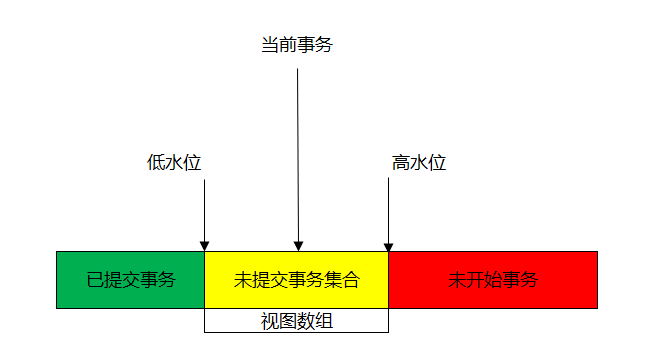
我對低水位與高水位的理解:
低水位=當前所有啟動了但未提交事務集合的ID最小值=當前事務的上一個啟動但未提交的事務ID最小值(所有活躍事務ID最小值)
高水位=當前事務的ID(當前ROW版本號/row trx_id)=已經創建過事務ID的最大值+1
舉例說明:仍然以上述RR隔離級別下三個ABC事務為例
- 事務A開始前,系統裡面只有一個活躍事務ID是99;
- 事務A、B、C的版本號分別是100、101、102,且當前系統里只有這四個事務;
- 三個事務開始前,(id,balance)=(1,1)這一行數據的row trx_id是90。
這樣,事務A的視圖數組就是[99], 事務B的視圖數組是[99,100], 事務C的視圖數組是[99,100,101]。即視圖數組通用公式為:[{當前事務開啟瞬間活躍事務ID集合}]。
而數據版本的可見性規則,就是基於row trx_id和一致性視圖對比結果得到的,所以我們還必須再了解下一致性視圖
3.一致性視圖
通過對視圖數組的理解,一致性視圖就更加容易了,即:這個視圖數組和高水位,就組成了當前事務的一致性視圖(read-view)。
仍然以上述RR隔離級別下三個ABC事務為例
- 事務A開始前,系統裡面只有一個活躍事務ID是99, 所以事物A開啟瞬間活躍事物集合為[99];
- 事務A、B、C的版本號分別是100、101、102,且當前系統里只有這四個事務,所以事物A、B、C高水位分別為100、101、102;
- 三個事務開始前,(id,balance)=(1,1)這一行數據的row trx_id是90。
這樣,事務A的一致性視圖就是[99,100], 事務B的一致性視圖是[99,100,101], 事務C的一致性視圖是[99,100,101,102]。即一致性視圖通用公式為:[{當前事務開啟瞬間活躍事務ID集合},當前row trx_id]。
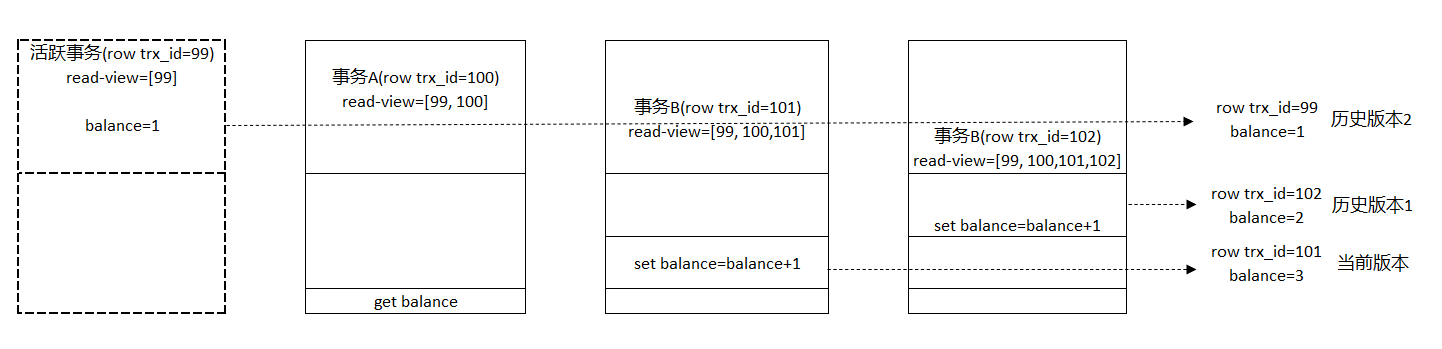
分析上述流程圖結果:
第一個有效更新版本是事物C,更新balance=2,這個時候的最新版本row trx_id=102,而之前的在事物ABC之前的活躍事物最新版本row trx_id為99,所以此時99已經成為歷史版本1;
第二個有效更新版本是事物B,更新balance=3,這個時候最新版本row trx_id=101,而此時row trx_id=102成為歷史版本1,而row trx_id=99成為歷史版本2;
事物A查詢的時候,事物B是沒有提交,但生成的(id, balance)=(1, 3)已經成為當前最新版本,事物A讀取數據時,一致性視圖為[99, 100],而讀數據都是從當前版本切的然後對比row trx_id,所以會有以下流程:
- 找到(1,3)的時候,判斷出row trx_id=101,比高水位大,處於紅色區域,不可見;
- 接著,找到上一個歷史版本,一看row trx_id=102,比高水位大,處於紅色區域,不可見;
- 再往前找,終於找到了(1,1),它的row trx_id=90,比低水位小,處於綠色區域,可見。
最後事物A無論在什麼時候查詢,看到的數據都是一致性視圖[99, 100]生成的快照數據(1, 1),即row trx_id=90時的數據。這就稱之為一致性讀。
總結:
- 版本未提交,不可見;
- 版本已提交,但是是在視圖創建後提交的,不可見;
- 版本已提交,而且是在視圖創建前提交的,可見。
- (1,3)還沒提交,屬於情況1,不可見;
- (1,2)雖然提交了,但是是在視圖數組創建之後提交的,屬於情況2,不可見;
- (1,1)是在視圖數組創建之前提交的,可見。
4.當前讀與快照讀
(1)當前讀與快照讀規則
當然按照這個一致性讀的邏輯,事物B在事物C有效更新balance=2之後,但是事物B的視圖數組是在事物C生成的,所以理論上來說不應該是事物B看到的是(id, balance)=(1, 1)這個數據(快照/歷史版本)嗎?而看不到當前版本(1, 2)數據。為什麼事物B在更新balance之後直接數據就成為(1, 3)了呢?
如果事物B在update之前select一次數據,看到的值確實是balance=1,但是update是不能在歷史版本上操作的,否則事物C的更新就會丟失,所以update操作都是在先讀取當前版本,然後再更新。
也就說有這麼一條規則:更新數據都是先讀後更新,而這個讀是讀當前最新值,稱之為「當前讀(current read),而只查詢不讀的話就會讀取當前快照,稱之為「快照讀」。所以在事物B更新balance之前,先查詢到最新的版本(1, 2)然後再更新為(1, 3)。而事物A查詢的快照數據為(1, 1),而不是最新版本(1, 3)。
(2)當前讀與快照讀解釋
當前讀:像select lock in share mode(共享鎖), select for update ; update, insert ,delete(排他鎖)這些操作都是一種當前讀。就是它讀取的是記錄的最新版本,讀取時還要保證其他並發事務不能修改當前記錄,會對讀取的記錄進行加鎖。
快照讀:像不加鎖的select操作就是快照讀,即不加鎖的非阻塞讀;快照讀的前提是隔離級別不是串列級別,串列級別下的快照讀會退化成當前讀。是基於多版本控制的,那麼快照讀可能讀到的並不一定是數據的最新版本,而有可能是之前的歷史版本(快照數據)。
(3)RC讀可提交下的視圖規則
讀提交的邏輯和可重複讀的邏輯類似,它們最主要的區別是:
- 在可重複讀隔離級別下,只需要在事務開始的時候創建一致性視圖,之後事務里的其他查詢,都共用這個一致性視圖;
- 在讀提交隔離級別下,每一個語句執行前都會重新算出一個新的視圖,此時start transaction with consistent snapshot就等同於普通的start transaction/begin

- 事物C立馬更新balance=2,然後自動提交,生成最新版本(1, 2),此時重新計算出視圖數據(1, 2);
- 事物B查到此時的最新版本為(1, 2),之後再更新為版本(1, 3)為當前最新版本,查詢此時的事物B select到的balance=3(事物B更新balance=3之後立馬算出一個新的視圖,select就是根據此視圖得到的數據),而不是1。
- 而此時事物B還未提交,對於事物A來說是看不見的,所以事物A此時讀取到的事物C提交的最新版本(1, 2)。



