用101000張食物圖片實現影像識別(數據的獲取與處理)-python-tensorflow框架
- 2019 年 10 月 3 日
- 筆記
前段時間,日劇《輪到你了》大火,作為程式設計師的我,看到了另外一個程式設計師—二階堂,他的生活作息,以及飲食規律,讓我感同身受,最讓我感觸的是他做的AI聊天機器人,AI菜品分析機器人,AI罪犯分析。
這讓作為程式設計師的我突然萌生了一股攀比和一種激情,我也得做一個出來(小聲bb,都得嘗試下):
於是,我想從相對簡單的做起,《AI菜品分析機器人》:
AI菜品分析機器人:
1.建立語料庫,爬取各個網站的對話和問答,這裡我採用的是知乎以及調用api獲取實時對話,至於程式碼的話我這裡就不放了,涉及比較多,我這裡側重點是影像識別,大概獲取了將近4萬條數據,
這裡給出部分結果:
2.關於影像識別:
1.影像訓練需要極大的數據,我這裡找了很久,通過各種手段,找到了kaggle比賽曾用過的101000張圖片,裡面有101種食物圖片,如下(部分)
類似於上述圖片,每一個圖片都是都是對應得食物,我們需要提取每一張圖片的特徵值。
2.我們可以看出上述圖片,大小不一,還具有色彩,我們特徵值提取,是將圖片進行矩陣化,所以我們在這裡需要將圖片變成大小一樣,並且灰度處理。這裡我們解釋下:
將圖片處理成大小一樣:我們訓練數據的時候是將圖片矩陣化,如果圖片大小不一樣,我們得矩陣大小就不一樣,所以在訓練得時候會有問題,為了簡單方便,我們直接將其同一化:
import numpy as np from PIL import Image img =Image.open("F:/images/baby_back_ribs/"+i).convert('L') img=img.resize((512,512)) img.save("F:/baby_back_ribs28/"+i)
這裡,我們通過img =Image.open(“F:/images/baby_back_ribs/“+i).convert(‘L‘)將圖片灰度處理,然後img=img.resize((512,512))處理圖片為512,512,最後保存:

可以看出,我們處理過後得圖片如上,得出這樣的圖片後,我們就可以用來作為數據了
3.我們將我們獲取的灰度圖片矩陣化:
for i in range(512): for j in range(512): pixel=1.0-float(img.getpixel((j,i)))/255.0
所以我們可以將其矩陣化:
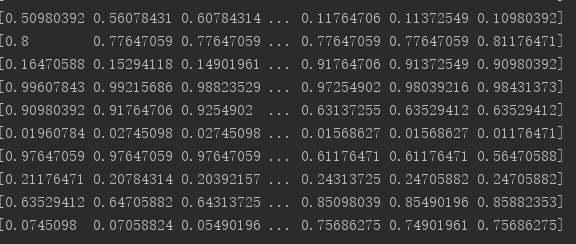
每張圖片有512*512個數據,我們這裡是將一個二維矩陣扁平化為一維矩陣。所以我們可以將這101000張圖片所有數據都矩陣化,然後測試演算法。
具體的程式碼,還在測試中,目前遇到得問題比較多,正在一步一步處理,後面會繼續更新,下面給出我遇到的一些問題和解決:
1.數據的獲取:這101000張圖片我找了很久才找到的數據(約有5個g)。
2.數據量比較大,在處理的時候容易出錯,所以大家在寫的時候一定要仔細,最好把源圖複製一份,保留下來。
3.圖片特徵比較多,普通的演算法難以滿足,容易出現過擬合現象,而且1000張圖也不算特別多,準確率較低,容易識別出錯。
4.在實現矩陣演算法的時候,每次帶入100張圖片進行訓練,注意圖片維度,以及圖片長度。
等數據測試穩定後會放出源碼讓大家學習。
持續更新中,希望大家留意後面的部落格…..
