Dubbo 編解碼那些事
一、背景
筆者在一次維護基礎公共組件的過程中,不小心修改了類的包路徑。糟糕的是,這個類被各業務在facade中進行了引用、傳遞。幸運的是,同一個類,在提供者和消費者的包路徑不一致,沒有引起各業務報錯。
懷揣著好奇,對於Dubbo的編解碼做了幾次的Debug學習,在此分享一些學習經驗。
1.1 RPC的愛與恨
Dubbo作為Java語言的RPC框架,優勢之一在於屏蔽了調用細節,能夠像調用本地方法一樣調用遠程服務,不必為數據格式抓耳饒腮。正是這一特性,也引入來了一些問題。
比如引入facade包後出現jar包衝突、服務無法啟動,更新facade包後某個類找不到等等問題。引入jar包,導致消費方和提供方在某種程度上有了一定耦合。
正是這種耦合,在提供者修改了Facade包類的路徑後,習慣性認為會引發報錯,而實際上並沒有。最初認為很奇怪,仔細思考後才認為理應這樣,調用方在按照約定的格式和協議基礎上,即可與提供方完成通訊。並不應該關注提供方本身上下文資訊。(認為類的路徑屬於上下文資訊)接下來揭秘Dubbo的編碼解碼過程。
二、Dubbo編解碼
Dubbo默認用的netty作為通訊框架,所有分析都是以netty作為前提。涉及的源碼均為Dubbo – 2.7.x版本。在實際過程中,一個服務很有可能既是消費者,也是提供者。為了簡化梳理流程,假定都是純粹的消費者、提供者。
2.1 In Dubbo
借用Dubbo官方文檔的一張圖,文檔內,定義了通訊和序列化層,並沒有定義”編解碼”含義,在此對”編解碼”做簡單解釋。
編解碼 = dubbo內部編解碼鏈路 + 序列化層
本文旨在梳理從Java對象到二進位流,以及二進位流到Java對象兩種數據格式之間的相互轉換。在此目的上,為了便於理解,附加通訊層內容,以encode,decode為入口,梳理dubbo處理鏈路。又因Dubbo內部定義為Encoder,Decoder,故在此定義為”編解碼”。
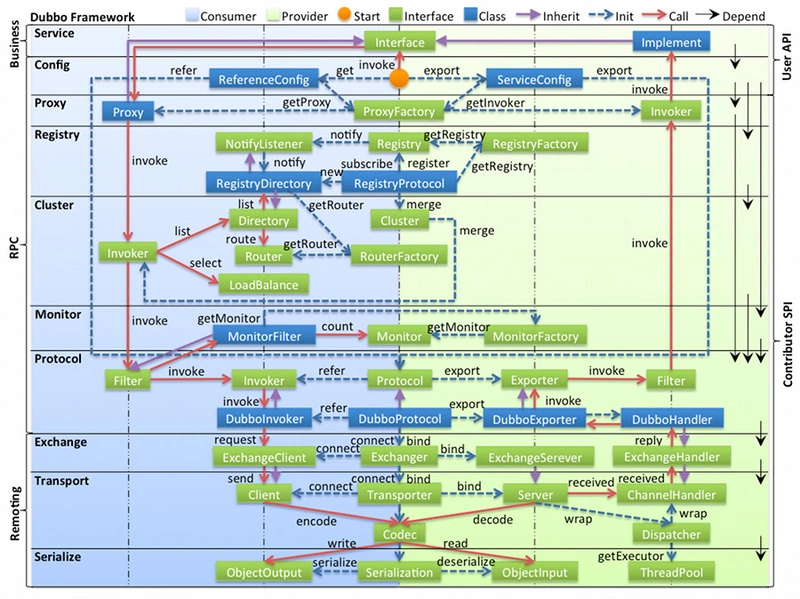
無論是序列化層,還是通訊層,都是Dubbo高效、穩定運行的基石,了解底層實現邏輯,能夠幫助我們更好的學習和使用Dubbo框架。
2.2 入口
消費者口在NettyClient#doOpen方法發起連接,初始化BootStrap時,會在Netty的pipeline里添加不同類型的ChannelHandler,其中就有編解碼器。
同理,提供者在NettyServer#doOpen方法提供服務,初始化ServerBootstrap時,會添加編解碼器。(adapter.getDecoder()- 解碼器,adapater.getEncoder() – 編碼器)。
NettyClient
/**
* Init bootstrap
*
* @throws Throwable
*/
@Override
protected void doOpen() throws Throwable {
bootstrap = new Bootstrap();
// ...
bootstrap.handler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
// ...
ch.pipeline()
.addLast("decoder", adapter.getDecoder())
.addLast("encoder", adapter.getEncoder())
.addLast("client-idle-handler", new IdleStateHandler(heartbeatInterval, 0, 0, MILLISECONDS))
.addLast("handler", nettyClientHandler);
// ...
}
});
}
NettyServer
/**
* Init and start netty server
*
* @throws Throwable
*/
@Override
protected void doOpen() throws Throwable {
bootstrap = new ServerBootstrap();
// ...
bootstrap.group(bossGroup, workerGroup)
.channel(NettyEventLoopFactory.serverSocketChannelClass())
.option(ChannelOption.SO_REUSEADDR, Boolean.TRUE)
.childOption(ChannelOption.TCP_NODELAY, Boolean.TRUE)
.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
// ...
ch.pipeline()
.addLast("decoder", adapter.getDecoder())
.addLast("encoder", adapter.getEncoder())
.addLast("server-idle-handler", new IdleStateHandler(0, 0, idleTimeout, MILLISECONDS))
.addLast("handler", nettyServerHandler);
}
});
// ...
}
2.3 消費端鏈路
消費者在發送消息時編碼,接收響應時解碼。
發送消息
ChannelInboundHandler
...
NettyCodecAdapter#getEncoder()
->NettyCodecAdapter$InternalEncoder#encode
->DubboCountCodec#encode
->DubboCodec#encode
->ExchangeCodec#encode
->ExchangeCodec#encodeRequest
DubboCountCodec類實際引用的是DubboCodec,因DubboCodec繼承於ExchangeCodec,並未重寫encode方法,所以實際程式碼跳轉會直接進入ExchangeCodec#encode方法
接收響應
NettyCodecAdapter#getDecoder()
->NettyCodecAdapter$InternalDecoder#decode
->DubboCountCodec#decode
->DubboCodec#decode
->ExchangeCodec#decode
->DubboCodec#decodeBody
...
MultiMessageHandler#received
->HeartbeatHadnler#received
->AllChannelHandler#received
...
ChannelEventRunnable#run
->DecodeHandler#received
->DecodeHandler#decode
->DecodeableRpcResult#decode
解碼鏈路相對複雜,過程中做了兩次解碼,在一次DubboCodec#decodeBody內,並未實際解碼channel的數據,而是構建成DecodeableRpcResult對象,然後在業務處理的Handler里通過非同步執行緒進行實際解碼。
2.4 提供端鏈路
提供者在接收消息時解碼,回復響應時編碼。
接收消息
NettyCodecAdapter#getDecoder()
->NettyCodecAdapter$InternalDecoder#decode
->DubboCountCodec#decode
->DubboCodec#decode
->ExchangeCodec#decode
->DubboCodec#decodeBody
...
MultiMessageHandler#received
->HeartbeatHadnler#received
->AllChannelHandler#received
...
ChannelEventRunnable#run
->DecodeHandler#received
->DecodeHandler#decode
->DecodeableRpcInvocation#decode
提供端解碼鏈路與消費端的類似,區別在於實際解碼對象不一樣,DecodeableRpcResult 替換成 DecodeableRpcInvocation。
體現了Dubbo程式碼里的良好設計,抽象處理鏈路,屏蔽處理細節,流程清晰可復用。
回復響應
NettyCodecAdapter#getEncoder()
->NettyCodecAdapter$InternalEncoder#encode
->DubboCountCodec#encode
->DubboCodec#encode
->ExchangeCodec#encode
->ExchangeCodec#encodeResponse
與消費方發送消息鏈路一致,區別在於最後一步區分Request和Response,進行不同內容編碼
2.5 Dubbo協議頭
Dubbo支援多種通訊協議,如dubbo協議,http,rmi,webservice等等。默認為Dubbo協議。作為通訊協議,有一定的協議格式和約定,而這些資訊是業務不關注的。是Dubbo框架在編碼過程中,進行添加和解析。
dubbo採用定長消息頭 + 不定長消息體進行數據傳輸。以下是消息頭的格式定義
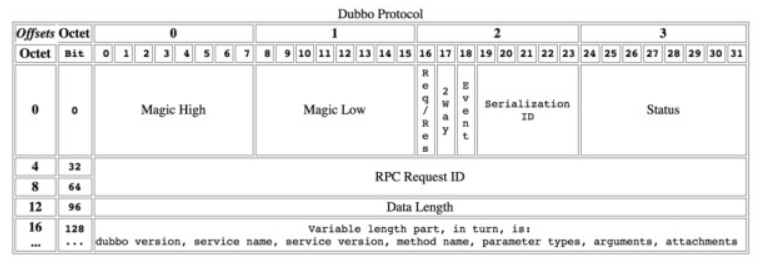
2byte:magic,類似java位元組碼文件里的魔數,用來標識是否是dubbo協議的數據包。
1byte:消息標誌位,5位序列化id,1位心跳還是正常請求,1位雙向還是單向,1位請求還是響應;
1byte:響應狀態,具體類型見com.alibaba.dubbo.remoting.exchange.Response;
8byte:消息ID,每一個請求的唯一識別id;
4byte:消息體body長度。
以消費端發送消息為例,設置消息頭內容的程式碼見ExchangeCodec#encodeRequest。
消息編碼
protected void encodeRequest(Channel channel, ChannelBuffer buffer, Request req) throws IOException {
Serialization serialization = getSerialization(channel);
// header.
byte[] header = new byte[HEADER_LENGTH];
// set magic number.
Bytes.short2bytes(MAGIC, header);
// set request and serialization flag.
header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId());
if (req.isTwoWay()) {
header[2] |= FLAG_TWOWAY;
}
if (req.isEvent()) {
header[2] |= FLAG_EVENT;
}
// set request id.
Bytes.long2bytes(req.getId(), header, 4);
// encode request data.
int savedWriteIndex = buffer.writerIndex();
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
if (req.isEvent()) {
encodeEventData(channel, out, req.getData());
} else {
encodeRequestData(channel, out, req.getData(), req.getVersion());
}
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
bos.flush();
bos.close();
int len = bos.writtenBytes();
checkPayload(channel, len);
// body length
Bytes.int2bytes(len, header, 12);
// write
buffer.writerIndex(savedWriteIndex);
buffer.writeBytes(header); // write header.
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);
}
三、Hessian2
前節梳理了編解碼的流程,本節仔細看一看對象序列化的細節內容。
我們知道,Dubbo支援多種序列化格式,hessian2,json,jdk序列化等。hessian2是阿里對於hessian進行了修改,也是dubbo默認的序列化框架。在此以消費端發送消息序列化對象,接收響應反序列化為案例,看看hessian2的處理細節,同時解答前言問題。
3.1 序列化
前文提到,請求編碼方法在ExchangeCodec#encodeRequest,其中對象數據的序列化為DubboCodec#encodeRequestData
DubboCodec
@Override
protected void encodeRequestData(Channel channel, ObjectOutput out, Object data, String version) throws IOException {
RpcInvocation inv = (RpcInvocation) data;
out.writeUTF(version);
// //github.com/apache/dubbo/issues/6138
String serviceName = inv.getAttachment(INTERFACE_KEY);
if (serviceName == null) {
serviceName = inv.getAttachment(PATH_KEY);
}
out.writeUTF(serviceName);
out.writeUTF(inv.getAttachment(VERSION_KEY));
out.writeUTF(inv.getMethodName());
out.writeUTF(inv.getParameterTypesDesc());
Object[] args = inv.getArguments();
if (args != null) {
for (int i = 0; i < args.length; i++) {
out.writeObject(encodeInvocationArgument(channel, inv, i));
}
}
out.writeAttachments(inv.getObjectAttachments());
}
我們知道,在dubbo調用過程中,是以Invocation作為上下文環境存儲。這裡先寫入了版本號,服務名,方法名,方法參數,返回值等資訊。隨後循環參數列表,對每個參數進行序列化。在此,out對象即是具體序列化框架對象,默認為Hessian2ObjectOutput。這個out對象作為參數傳遞進來。
那麼是在哪裡確認實際序列化對象呢?
從頭查看編碼的調用鏈路,ExchangeCodec#encodeRequest內有如下程式碼:
ExchangeCodec
protected void encodeRequest(Channel channel, ChannelBuffer buffer, Request req) throws IOException {
Serialization serialization = getSerialization(channel);
// ...
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
if (req.isEvent()) {
encodeEventData(channel, out, req.getData());
} else {
encodeRequestData(channel, out, req.getData(), req.getVersion());
}
// ...
}
out對象來自於serialization對象,順著往下看。在CodecSupport類有如下程式碼:
CodecSupport
public static Serialization getSerialization(URL url) {
return ExtensionLoader.getExtensionLoader(Serialization.class).getExtension(
url.getParameter(Constants.SERIALIZATION_KEY, Constants.DEFAULT_REMOTING_SERIALIZATION));
}
可以看到,這裡通過URL資訊,基於Dubbo的SPI選擇Serialization對象,默認為hessian2。再看看serialization.serialize(channel.getUrl(),bos)方法:
Hessian2Serialization
@Override
public ObjectOutput serialize(URL url, OutputStream out) throws IOException {
return new Hessian2ObjectOutput(out);
}
至此,找到了實際序列化對象,參數序列化邏輯較為簡單,不做贅述,簡述如下:寫入請求參數類型 → 寫入參數欄位名 → 迭代欄位列表,欄位序列化。
3.2 反序列化
相對於序列化而言,反序列化會多一些約束。序列化對象時,不需要關心接收者的實際數據格式。反序列化則不然,需要保證原始數據和對象匹配。(這裡的原始數據可能是二進位流,也可能是json)。
消費端解碼鏈路中有提到,發生了兩次解碼,第一次未實際解碼業務數據,而是轉換成DecodeableRpcResult。具體程式碼如下:
DubboCodec
@Override
protected Object decodeBody(Channel channel, InputStream is, byte[] header) throws IOException {
byte flag = header[2], proto = (byte) (flag & SERIALIZATION_MASK);
// get request id.
long id = Bytes.bytes2long(header, 4);
if ((flag & FLAG_REQUEST) == 0) {
// decode response...
try {
DecodeableRpcResult result;
if (channel.getUrl().getParameter(DECODE_IN_IO_THREAD_KEY, DEFAULT_DECODE_IN_IO_THREAD)) {
result = new DecodeableRpcResult(channel, res, is,
(Invocation) getRequestData(id), proto);
result.decode();
} else {
result = new DecodeableRpcResult(channel, res,
new UnsafeByteArrayInputStream(readMessageData(is)),
(Invocation) getRequestData(id), proto);
}
data = result;
} catch (Throwable t) {
// ...
}
return res;
} else {
// decode request...
return req;
}
}
關鍵點
1)對於解碼請求還是解碼響應做了區分,對於消費端而言,就是解碼響應。對於提供端而言,即是解碼請求。
2)為什麼會出現兩次解碼?具體見這行:
if (channel.getUrl().getParameter(DECODE_IN_IO_THREAD_KEY, DEFAULT_DECODE_IN_IO_THREAD)) {
inv = new DecodeableRpcInvocation(channel, req, is, proto);
inv.decode();
} else {
inv = new DecodeableRpcInvocation(channel, req,
new UnsafeByteArrayInputStream(readMessageData(is)), proto);
}
decode_in_io_thread_key – 是否在io執行緒內進行解碼,默認是false,避免在io執行緒內處理業務邏輯,這也是符合netty的推薦做法。所以才有了非同步的解碼過程。
那看看解碼業務對象的程式碼,還記得在哪兒嗎?DecodeableRpcResult#decode
DecodeableRpcResult
@Override
public Object decode(Channel channel, InputStream input) throws IOException {
ObjectInput in = CodecSupport.getSerialization(channel.getUrl(), serializationType)
.deserialize(channel.getUrl(), input);
byte flag = in.readByte();
switch (flag) {
case DubboCodec.RESPONSE_NULL_VALUE:
// ...
case DubboCodec.RESPONSE_VALUE_WITH_ATTACHMENTS:
handleValue(in);
handleAttachment(in);
break;
case DubboCodec.RESPONSE_WITH_EXCEPTION_WITH_ATTACHMENTS:
// ...
default:
throw new IOException("Unknown result flag, expect '0' '1' '2' '3' '4' '5', but received: " + flag);
}
// ...
return this;
}
private void handleValue(ObjectInput in) throws IOException {
try {
Type[] returnTypes;
if (invocation instanceof RpcInvocation) {
returnTypes = ((RpcInvocation) invocation).getReturnTypes();
} else {
returnTypes = RpcUtils.getReturnTypes(invocation);
}
Object value = null;
if (ArrayUtils.isEmpty(returnTypes)) {
// This almost never happens?
value = in.readObject();
} else if (returnTypes.length == 1) {
value = in.readObject((Class<?>) returnTypes[0]);
} else {
value = in.readObject((Class<?>) returnTypes[0], returnTypes[1]);
}
setValue(value);
} catch (ClassNotFoundException e) {
rethrow(e);
}
}
這裡出現了ObjectInput,那底層的序列化框架選擇邏輯是怎麼樣的呢?如何保持與消費端的序列化框架一致?
每一個序列化框架有一個id見org.apache.dubbo.common.serialize.Constants;
1、請求時,序列化框架是根據Url資訊進行選擇,默認是hessian2
2、傳輸時,會將序列化框架標識寫入協議頭,具體見ExchangeCodec#encodeRequest#218
3、提供收到消費端的請求時,會根據這個id使用對應的序列化框架。
此次實際持有對象為Hessian2ObjectInput,由於readObject反序列化邏輯處理較為複雜,流程如下:

四、常見問題
問題1:提供端修改了Facade里的類路徑,消費端反序列化為什麼沒報錯?
答:反序列化時,消費端找不到提供端方返回的類路徑時,會catch異常,以本地的返回類型為準做處理
問題2:編碼序列化時,沒有為什麼寫入返回值?
答:因為在Java中,返回值不作為標識方法的資訊之一
問題3:反序列化流程圖中,A與B何時會出現不一致的情況?A的資訊從何處讀取?
答:當提供端修改了類路徑時,A與B會出現不一樣;A的資訊來源於,發起請求時,Request對象里存儲的Invocation上下文,是本地jar包里的返回值類型。
問題4:提供者增刪返回欄位,消費者會報錯嗎?
答:不會,反序列化時,取兩者欄位交集。
問題5:提供端修改對象的父類資訊,消費端會報錯嗎?
答:不會,傳輸中只攜帶了父類的欄位資訊,沒有攜帶父類類資訊。實例化時,以本地類做實例化,不關聯提供方實際程式碼的父類路徑。
問題6:反序列化過程中,如果返回對象子類和父類存在同名欄位,且子類有值,父類無值,會發生什麼?
答:在dubbo – 3.0.x版本,在會出現返回欄位為空的情況。原因在於編碼側迭代傳輸欄位集合時(消費端可能編碼,提供端也可能編碼),父類的欄位資訊在子類後面。解碼側拿到欄位集合迭代解碼時,通過欄位key拿到反序列化器,此時子類和父類同名,那麼第一次反射會設置子類值,第二次反射會設置父類值進行覆蓋。
在dubbo – 2.7.x版本中,該問題已解決。解決方案也比較簡單,在編碼側傳輸時,通過 Collections.reverse(fields)反轉欄位順序。
JavaSerializer
public JavaSerializer(Class cl, ClassLoader loader) {
introspectWriteReplace(cl, loader);
// ...
List fields = new ArrayList();
fields.addAll(primitiveFields);
fields.addAll(compoundFields);
Collections.reverse(fields);
// ...
}
五、寫在最後
編解碼過程複雜晦澀,數據類型多種多樣。筆者遇到和了解的終究有限,以最常見、最簡單的數據類型梳理編解碼的流程。如有錯誤疏漏之處,還請見諒。
作者:vivo 互聯網伺服器團隊-Sun wen


