乾貨!Apache Hudi如何智慧處理小文件問題
- 2021 年 4 月 11 日
- 筆記
1. 引入
Apache Hudi是一個流行的開源的數據湖框架,Hudi提供的一個非常重要的特性是自動管理文件大小,而不用用戶干預。大量的小文件將會導致很差的查詢分析性能,因為查詢引擎執行查詢時需要進行太多次文件的打開/讀取/關閉。在流式場景中不斷攝取數據,如果不進行處理,會產生很多小文件。
2. 寫入時 vs 寫入後
一種常見的處理方法先寫入很多小文件,然後再合併成大文件以解決由小文件引起的系統擴展性問題,但由於暴露太多小文件可能導致不能保證查詢的SLA。實際上對於Hudi表,通過Hudi提供的Clustering功能可以非常輕鬆的做到這一點,更多細節可參考之前一篇文章查詢時間降低60%!Apache Hudi數據布局黑科技了解下。
本篇文章將介紹Hudi的文件大小優化策略,即在寫入時處理。Hudi會自管理文件大小,避免向查詢引擎暴露小文件,其中自動處理文件大小起很大作用。
在進行insert/upsert操作時,Hudi可以將文件大小維護在一個指定文件大小(注意:bulk_insert操作暫無此特性,其主要用於替換spark.write.parquet方式將數據快速寫入Hudi)。
3. 配置
我們使用COPY_ON_WRITE表來演示Hudi如何自動處理文件大小特性。
關鍵配置項如下:
-
hoodie.parquet.max.file.size:數據文件最大大小,Hudi將試著維護文件大小到該指定值;
-
hoodie.parquet.small.file.limit:小於該大小的文件均被視為小文件;
-
hoodie.copyonwrite.insert.split.size:單文件中插入記錄條數,此值應與單個文件中的記錄數匹配(可以根據最大文件大小和每個記錄大小來確定)
例如如果你第一個配置值設置為120MB,第二個配置值設置為100MB,則任何大小小於100MB的文件都將被視為一個小文件,如果要關閉此功能,可將hoodie.parquet.small.file.limit配置值設置為0。
4. 示例
假設一個指定分區下數據文件布局如下
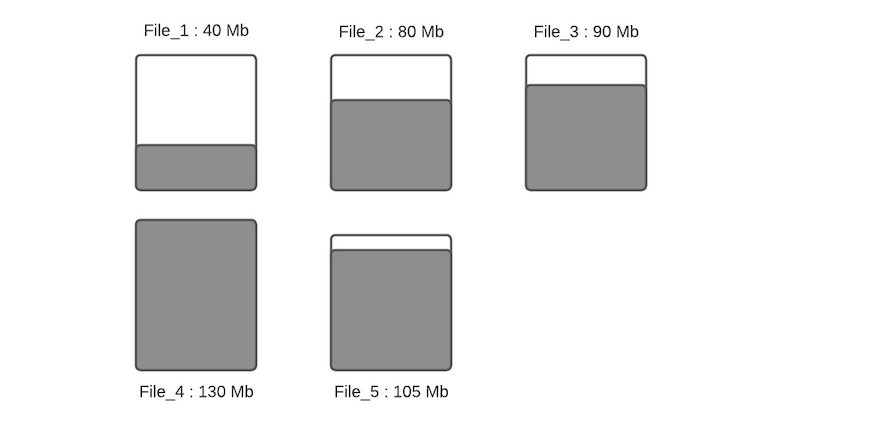
假設配置的hoodie.parquet.max.file.size為120MB,hoodie.parquet.small.file.limit為100MB。File_1大小為40MB,File_2大小為80MB,File_3是90MB,File_4是130MB,File_5是105MB,當有新寫入時其流程如下:
步驟一:將更新分配到指定文件,這一步將查找索引來找到相應的文件,假設更新會增加文件的大小,會導致文件變大。當更新減小文件大小時(例如使許多欄位無效),則隨後的寫入將文件將越來越小。
步驟二:根據hoodie.parquet.small.file.limit決定每個分區下的小文件,我們的示例中該配置為100MB,所以小文件為File_1、File_2和File_3;
步驟三:確定小文件後,新插入的記錄將分配給小文件以便使其達到120MB,File_1將會插入80MB大小的記錄數,File_2將會插入40MB大小的記錄數,File_3將插入30MB大小的記錄數。
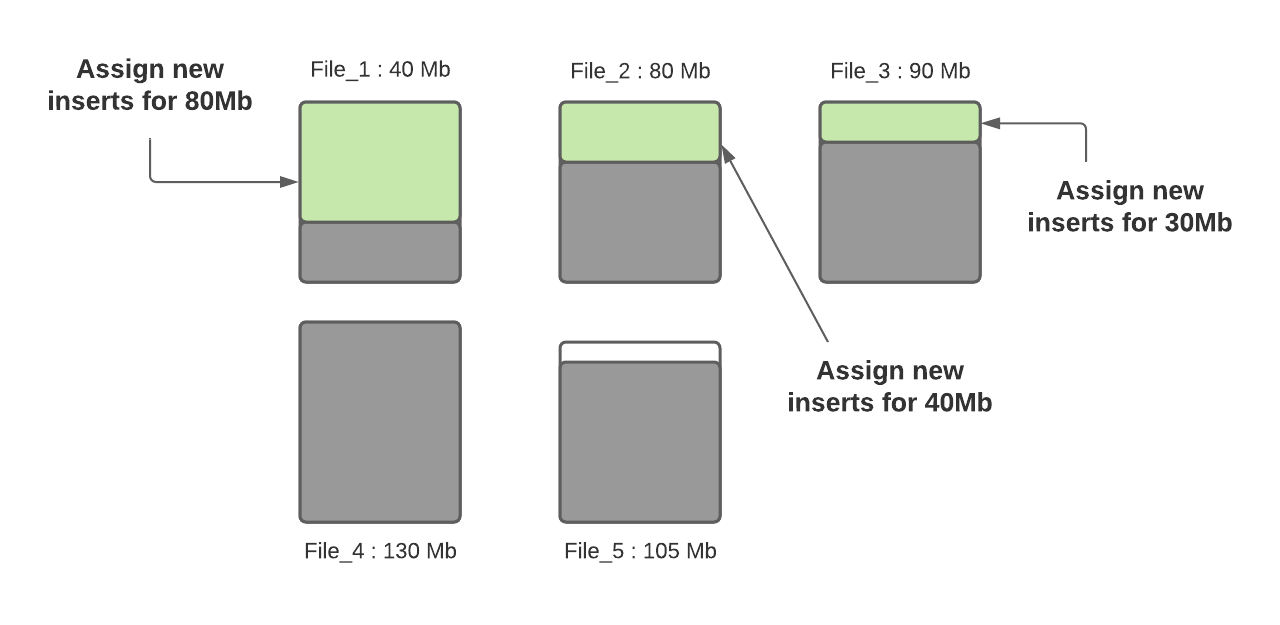
步驟四:當所有小文件都分配完了對應插入記錄數後,如果還有剩餘未分配的插入記錄,這些記錄將分配給新創建的FileGroup/數據文件。數據文件中的記錄數由hoodie.copyonwrite.insert.split.size(或者由之前的寫入自動推算每條記錄大小,然後根據配置的最大文件大小計算出來可以插入的記錄數)決定,假設最後得到的該值為120K(每條記錄大小1K),如果還剩餘300K的記錄數,將會創建3個新文件(File_6,File_7,File_8),File_6和File_7都會分配120K的記錄數,File_8會分配60K的記錄數,共計60MB,後面再寫入時,File_8會被認為小文件,可以插入更多數據。
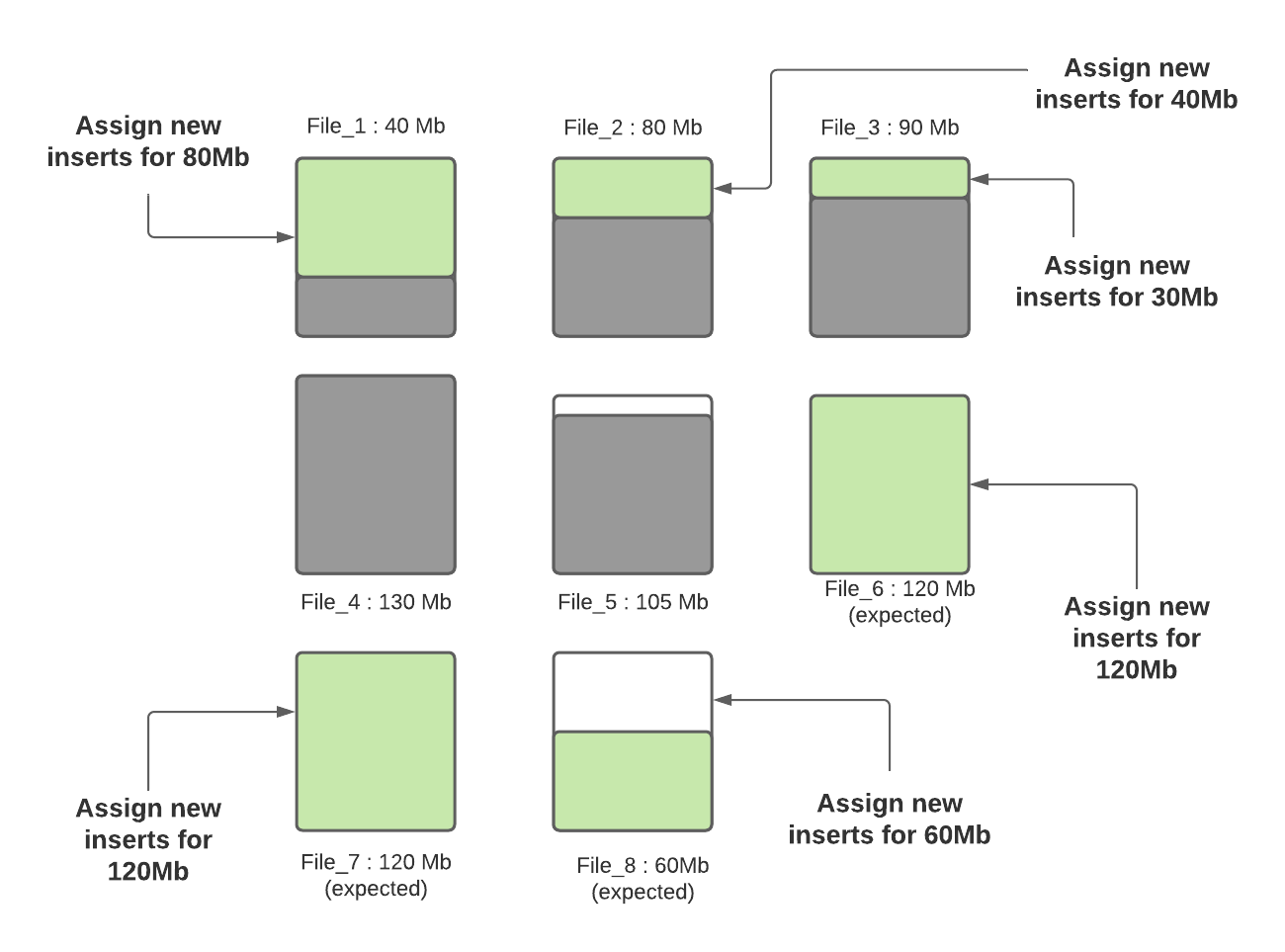
Hudi利用諸如自定義分區之類的機制來優化記錄分配到不同文件的能力,從而執行上述演算法。在這輪寫入完成之後,除File_8以外的所有文件均已調整為最佳大小,每次寫入都會遵循此過程,以確保Hudi表中沒有小文件。
5. 總結
本文介紹了Apache Hudi如何智慧地管理小文件問題,即在寫入時找出小文件並分配指定大小的記錄數來規避小文件問題,基於該設計,用戶再也不用擔心Apache Hudi數據湖中的小文件問題了。


