web scraper 抓取數據並做簡單數據分析
- 2019 年 10 月 3 日
- 筆記
其實 web scraper 說到底就是那點兒東西,所有的網站都是大同小異,但是都還不同。這也是好多同學總是遇到問題的原因。因為沒有統一的模板可用,需要理解了 web scraper 的原理並且對目標網站加以分析才可以。
今天再介紹一篇關於 web scraper 抓取數據的文章,除了 web scraper 的使用方式外,還包括一些簡單的數據處理和分析。都是基礎的不能再基礎了。
選擇這個網站一來是因為作為一個開發者在上面買了不少課,還有個原因就是它的專欄也比較有特點,需要先滾動載入,然後再點擊按鈕載入。
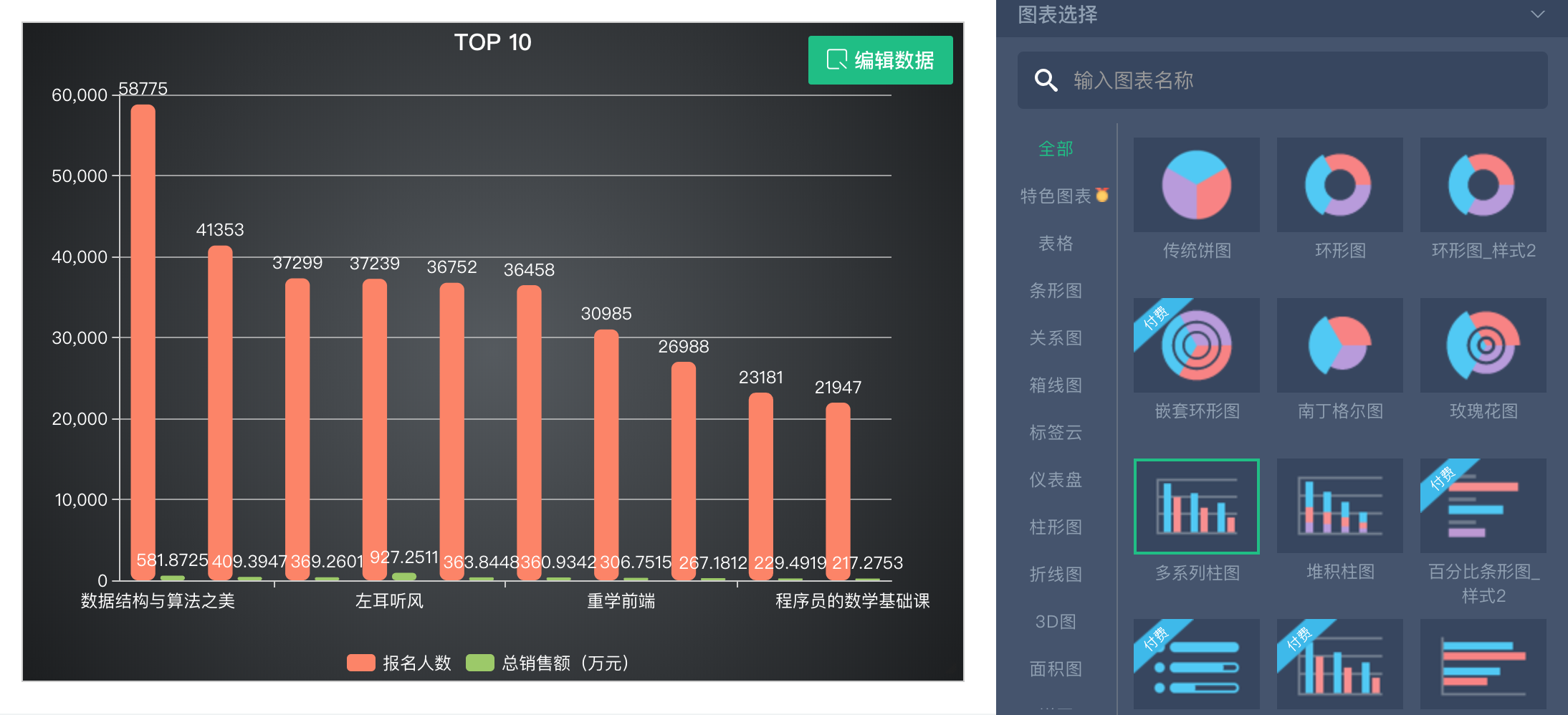
開始正式的數據抓取工作之前,先來看一下我的成果,我把抓取到的90多個專欄的訂閱數和銷售總價做了一個排序,然後把 TOP 10 拿出來做了一個柱狀圖出來。

抓取數據
今天要抓的這個網站是一個 IT 知識付費社區,極客時間,應該互聯網圈的大多數同學都聽說過,我還在上面買了 9 門課,雖然沒怎麼看過。
極客時間的首頁會列出所有網課,和簡書首頁的載入方式一樣,都是先滾動下拉載入,之後變為點擊載入更多按鈕載入更多。這是一種典型網站載入方式,有好多的網站都是兩種方式結合的。這就給我們用 web scraper 抓數據製造了一定的麻煩,不過也很好解決。
1、創建 sitemap,設置 start url 為 https://time.geekbang.org/。
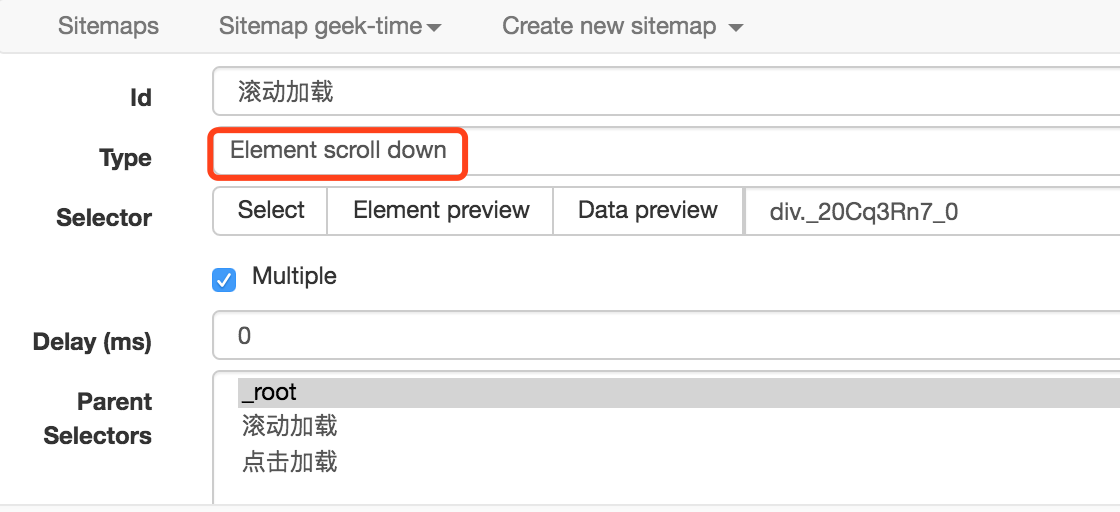
2、創建滾動載入的 Selector,這只是個輔助,幫助我們把頁面載入到出現點擊載入更多按鈕出現,設置如下,注意類型選擇 Element scroll down,選擇整個課程列表區域作為 Element。
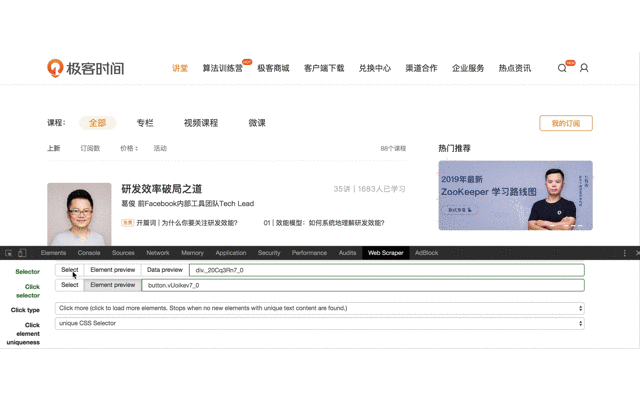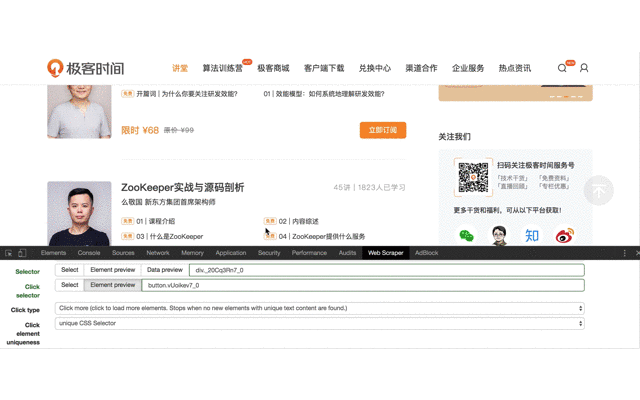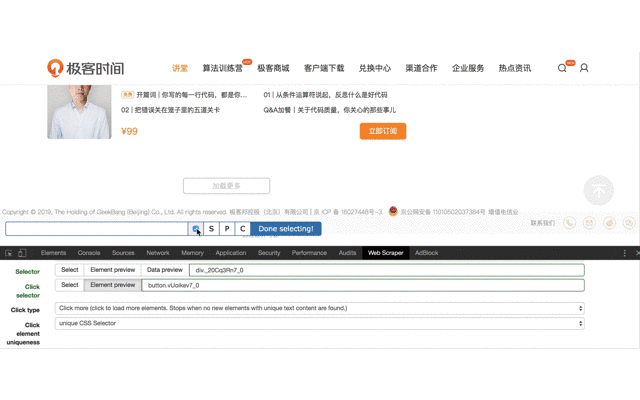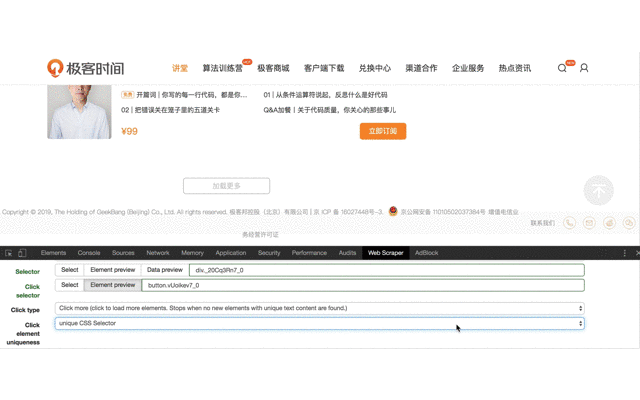
3、創建點擊載入更多按鈕的 Selector,這個才是真正要抓取內容的 Selector。之後會在它下面創建子選擇器。創建之前,需要下拉記載頁面,直到出現載入更多按鈕。

首先選擇元素類型為 Element click 。
Selector 選擇整個課程列表,並設置為 Multiple。
Click 選擇載入更多按鈕,這裡需要注意一點,之前的文章里也提到過,這個按鈕沒辦法直接點擊選中,因為點擊後會觸發頁面載入動作,所以要勾選 Enable key events,然後按 S 鍵,來選中這個按鈕。
Click type 設置為 Click more 類型。
Click element uniqueness 設置 unique CSS Selector。
4、進入上一步創建的 Selector ,創建子選擇器,用來抓取最終需要的內容。

5、最後運行抓取就可以啦。
數據清洗
這裡只是很簡單的演示,真正的大數據量的數據清洗工作要費力耗時的多。而且也遠不止一個 Excel 能完成的,還需要程式程式碼的配合,大多數時候還會用到資料庫,當然對於比較簡單的數據或者沒有開發經驗的同學來說,用 Excel 也就是最簡單省事的選擇了。
打開 csv 文件後,第一列資訊是 web scraper 自動生成的,直接刪掉即可。不知道什麼原因,有幾條重複數據,第一步,先把重複項去掉,進入 Excel 「數據」選項卡,點擊刪除重複項即可。
第二步,由於抓下來的課時和報名人數在同一個元素下,沒辦法在 web scraper 直接放到兩個列,所以只能到 Excel 中處理。我的操作思路是這樣的,先複製一列出來,然後利用內容替換的方式,將其中一列的報名人數替換成空字元,替換的表達式為 講 | *人已學習,這樣此列就變成了課時列。將另外一列的課時替換為空字元串,先替換 x講,替換內容為*講 |,然後再替換人已學習, 那麼這列就變成了報名人數列。價格就只保留當前價格,刪掉無用列,並且處理掉限時、拼團、¥這些無用字元。
數據分析
因為這裡抓取的數據比較簡單,也沒指望能分析出什麼結果。 一共90幾門課,也就是分析分析哪門課最受歡迎、價格最高。直接在 Excel 里排個序就好了。然後計算一下幾門課程的總價格。
當然真正的商業數據分析不僅僅是一個 Excel 畫個圖就搞定的事兒。也不是弄兩個柱狀圖就可以的了,一般都需要多個維度、數據關聯分析、深度挖掘等。
在 Excel 中做了兩個柱狀圖,分別統計訂閱人數前十名和總銷售金額的前十名。下面是最後的呈現效果。

如果不想用 Excel, 有一些在線的圖表製作網站也可以將 Excel 上傳做一些基本的圖表,但是靈活性稍微差一點。我用了「圖表秀(https://www.tubiaoxiu.com/)」,可以將 Excel 上傳,而且還能對 Excel 進行編輯,可以刪除列、刪除行等操作,這也是相對其他在線圖表平台的優勢,比如百度的「圖說」。下面是我做的一個簡單的柱狀圖,除了柱狀圖外還支援好多種圖表。
以上僅僅是一個業餘選手做數據抓取和分析的過程,請酌情參考。
掃描下方二維碼,關注公眾號:
回復「Excel」獲取本例中的 Excel 數據文件。
回復「jike」獲取本例中的 sitemap。
不要吝惜你的「推薦」呦
歡迎關注,不定期更新本系列和其他文章
公眾號:古時的風箏

相關閱讀:
