incubator-dolphinscheduler 如何在不寫任何新程式碼的情況下,能快速接入到prometheus和grafana中進行監控
- 2021 年 3 月 15 日
- 筆記
- DolphinScheduler, Grafana, Prometheus
一、prometheus和grafana 簡介
prometheus是由Google研發的一款開源的監控軟體,目前已經貢獻給了apache 基金會託管。
監控通常分為白盒監控和黑盒監控之分。
- 白盒監控:通過監控內部的運行狀態及指標判斷可能會發生的問題,從而做出預判或對其進行優化。
- 黑盒監控:監控系統或服務,在發生異常時做出相應措施。
prometheus的優勢:
- 易於管理,通俗易懂
- 能夠輕易獲取服務內部狀態,比如jvm等。
- 高效靈活的查詢語句
- 支援本地和遠程存儲,支援時序資料庫
- 採用http協議,默認pull模式拉取數據,也可以通過中間網關push數據(需要安裝push gateway)
- 支援自動發現(通過服務的方式進行自動發現待監控的目標,可以通過Consul實現服務發現)
- 可擴展
- 易集成
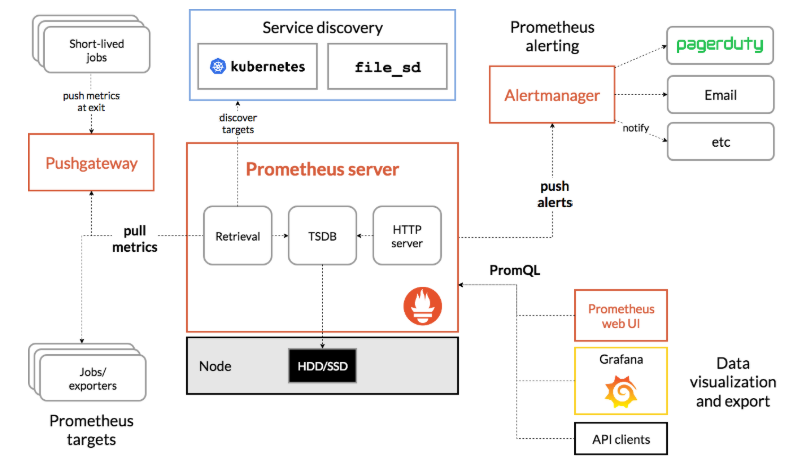
prometheus根據配置定時可以去拉取各個節點的數據,默認使用的拉取方式是pull,也可以使用pushgateway提供的push方式獲取各個監控節點的數據。將獲取到的數據存入TSDB(時序型資料庫),pushgateway 就是 外部的應用可以將監控的數據主動推送給pushgateway,然後prometheus 自動從pushgateway進行拉取。此時prometheus已經獲取到了監控數據,可以使用內置的PromQL進行查詢。它的報警功能使用Alertmanager提供,Alertmanager是prometheus的告警管理和發送報警的一個組件。prometheus原生的圖標功能由於過於簡單,因此建議將prometheus數據接入grafana,由grafana進行統一管理。
Grafana是開源的可視化監控、分析利器,支援多種資料庫類型和豐富的套件,目前已支援超過50多個數據源,50多個面板,17個應用程式和1732個不同的儀錶圖。(本文作者:張永清,轉載請註明來源部落格園://www.cnblogs.com/laoqing/p/14538635.html)
- 擁有快速靈活的客戶端圖表,面板插件有許多不同方式的可視化指標和日誌,官方提供的庫中具有豐富的儀錶盤插件,比如甘特圖、熱圖、折線圖、圖表等多種展示方式。
- 支援許多不同的時間序列數據(數據源)存儲後端。每個數據源都有一個特定查詢編輯器。官方支援數據源:Graphite、infloxdb、opensdb、prometheus、elasticsearch、cloudwatch,mysql 等。每個數據源的查詢語言和功能有較大差異。可以將來自多個數據源的數據組合到一個儀錶板上,但每個面板都要綁定到屬於特定組織的特定數據源中。
- 告警允許將規則附加到儀錶板面板上。保存儀錶板時會將警報規則提取到單獨的警報規則存儲中,並安排它們進行評估。報警消息還能支援釘釘、郵箱等推送至移動端。
二、incubator-dolphinscheduler 簡介
incubator-dolphinscheduler是一個由中國公司發起的大數據領域的開源調度項目,incubator-dolphinscheduler 能夠支撐非常多的應用場景,包括:
- 以DAG圖的方式將Task按照任務的依賴關係關聯起來,可實時可視化監控任務的運行狀態
- 支援豐富的任務類型:Shell、MR、Spark、SQL(mysql、postgresql、hive、sparksql),Python,Sub_Process、Procedure,flink,datax,sqoop,http等
- 支援工作流定時調度、依賴調度、手動調度、手動暫停/停止/恢復,同時支援失敗重試/告警、從指定節點恢復失敗、Kill任務等操作
- 支援工作流優先順序、任務優先順序及任務的故障轉移及任務超時告警/失敗
- 支援工作流全局參數及節點自定義參數設置
- 支援資源文件的在線上傳/下載,管理等,支援在線文件創建、編輯
- 支援任務日誌在線查看及滾動、在線下載日誌等
- 實現集群HA,通過Zookeeper實現Master集群和Worker集群去中心化
- 支援對
Master/Workercpu load,memory,cpu在線查看 - 支援工作流運行歷史樹形/甘特圖展示、支援任務狀態統計、流程狀態統計
- 支援補數
- 支援多租戶
- 支援國際化
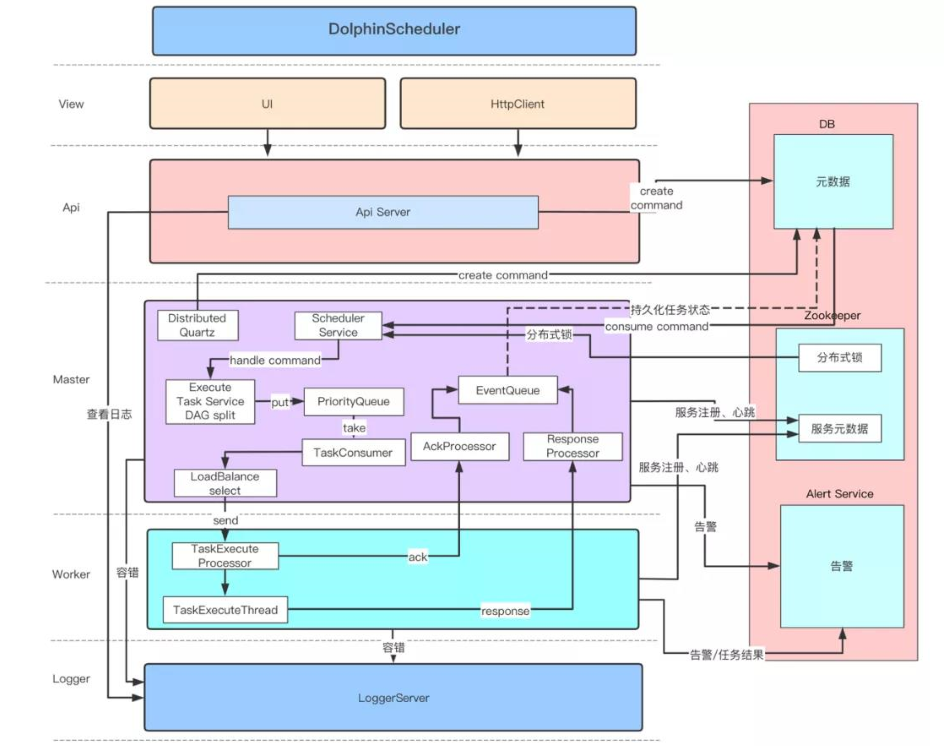
備註:此架構圖摘自社區官方網站
三、incubator-dolphinscheduler 如何快速接入到prometheus和grafana 中進行監控
1、通過prometheus中push gateway的方式採集監控指標數據。
需要藉助push gateway一起,然後將數據發送到push gateway 地址中,比如地址為//10.25x.xx.xx:8085,那麼就可以寫一個shell 腳本,通過crontab調度或者incubator-dolphinscheduler調度,定期運行shell腳本,來發送指標數據到prometheus中。
#!/bin/bash failedTaskCounts=`mysql -h 10.25x.xx.xx -u username -ppassword -e "select 'failed' as failTotal ,count(distinct(process_definition_id)) as failCounts from dolphinscheduler.t_ds_process_instance where state=6 and start_time>='${datetimestr} 00:00:00'" |grep "failed"|awk -F " " '{print $2}'` echo "failedTaskCounts:${failedTaskCounts}" job_name="Scheduling_system" instance_name="dolphinscheduler" cat <<EOF | curl --data-binary @- http://10.25x.xx.xx:8085/metrics/job/$job_name/instance/$instance_name failedSchedulingTaskCounts $failedTaskCounts EOF
這段腳本中failedSchedulingTaskCounts 就是定義的prometheus中的一個指標。腳本通過sql語句查詢出失敗的任務數,然後發送到prometheus中。
然後在grafana 中就可以選擇數據源為prometheus,並且選擇對應的指標。
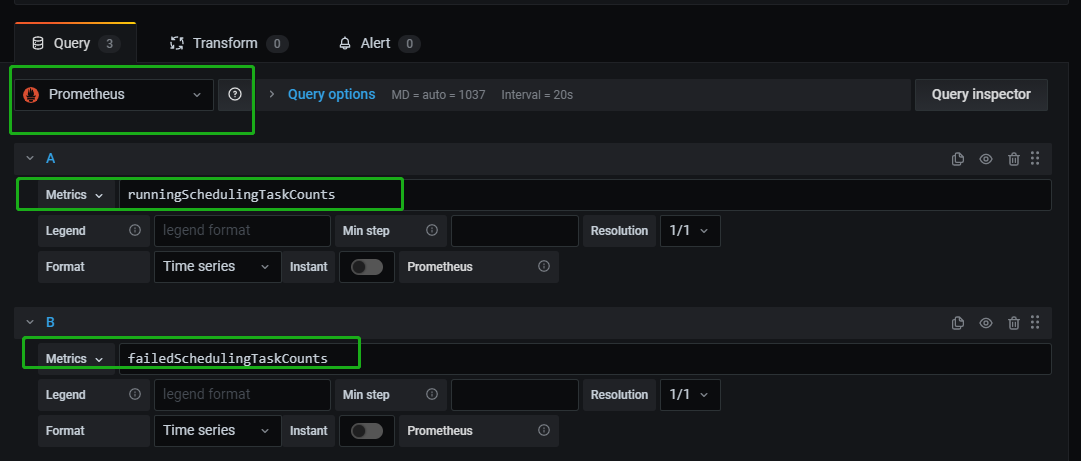
比如可以通過如下shell 腳本採集正在運行的任務數,然後通過push gateway 發送到prometheus中。(本文作者:張永清,轉載請註明來源部落格園://www.cnblogs.com/laoqing/p/14538635.html)
#!/bin/bash runningTaskCounts=`mysql -h 10.25x.xx.xx -u username -ppassword -e "select 'running' as runTotal ,count(distinct(process_definition_id)) as runCounts from dolphinscheduler.t_ds_process_instance where state=1" |grep "failed"|awk -F " " '{print $2}'` echo "runningTaskCounts:${runningTaskCounts}"
job_name="Scheduling_system"
instance_name="dolphinscheduler" if [ "${runningTaskCounts}yy" == "yy" ];then runningTaskCounts=0 fi cat <<EOF | curl --data-binary @- http://10.25x.xx.xx:8085/metrics/job/$job_name/instance/$instance_name runningSchedulingTaskCounts $runningTaskCounts EOF
採集好了後,就可以達到如下的效果了
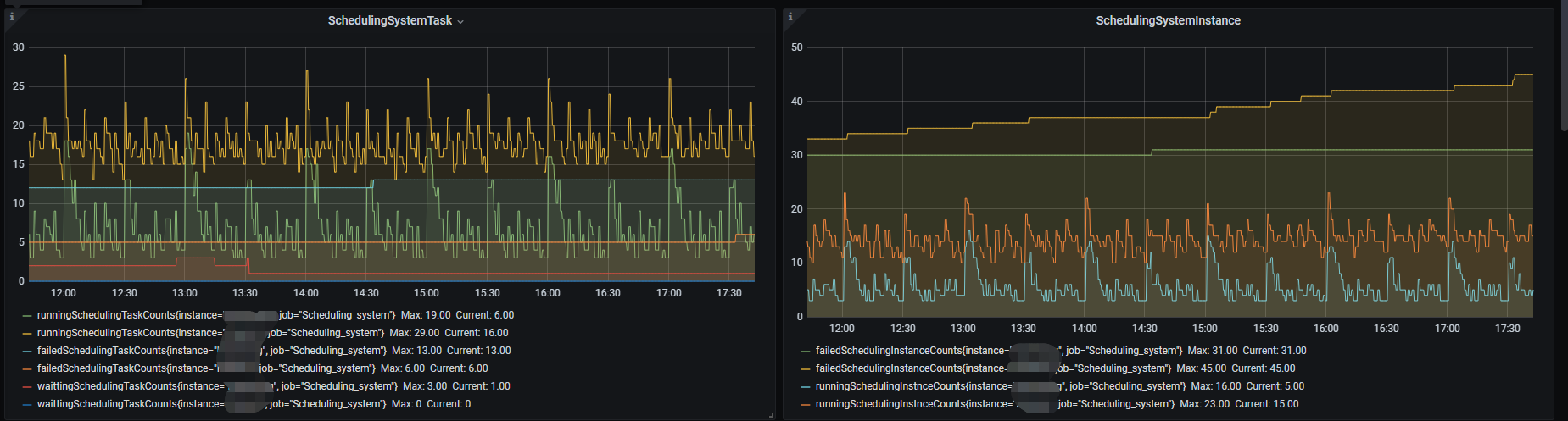
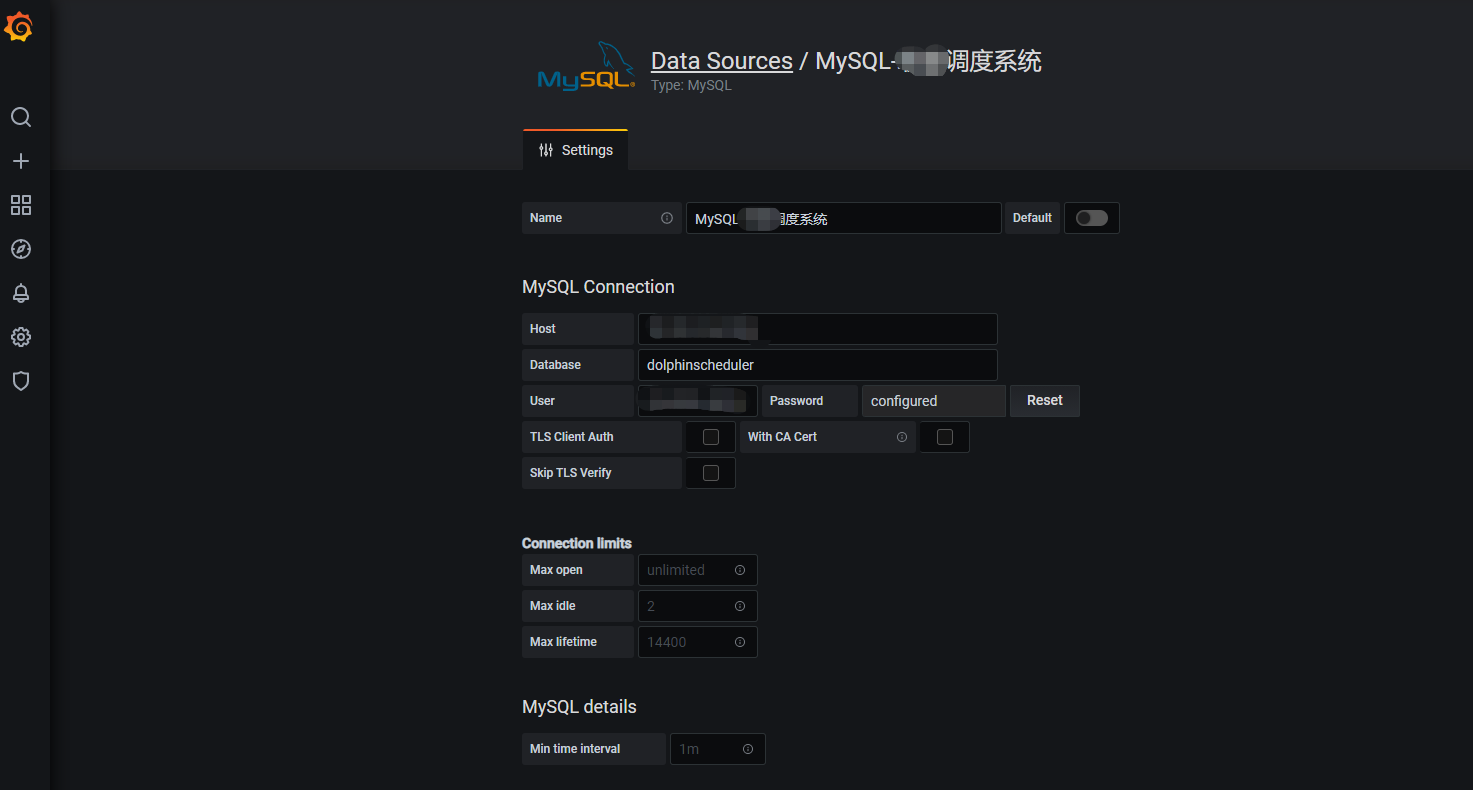
2、通過grafana 直接查詢dolphinscheduler自身 的Mysql資料庫(也可以是別的資料庫)
首先需要在grafana 中定義一個數據源,這個數據源就是dolphinscheduler自身 的Mysql資料庫。
然後在grafana 中選擇這個數據源,Format as 格式選擇table,輸入對應的sql語句。(本文作者:張永清,轉載請註明來源部落格園://www.cnblogs.com/laoqing/p/14538635.html)
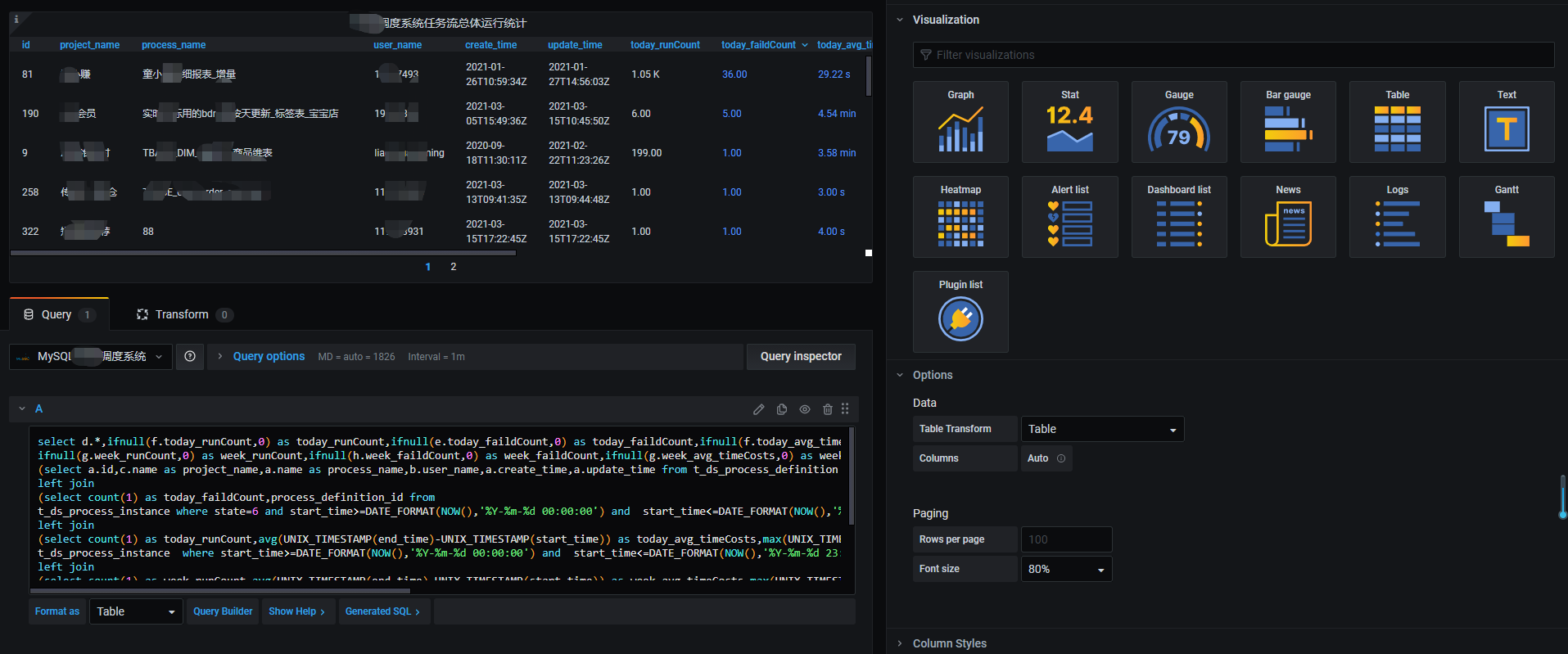
比如如下sql,統計本周以及當日正在運行的調度任務的情況。
select d.*,ifnull(f.today_runCount,0) as today_runCount,ifnull(e.today_faildCount,0) as today_faildCount,ifnull(f.today_avg_timeCosts,0) as today_avg_timeCosts,ifnull(f.today_max_timeCosts,0) as today_max_timeCosts, ifnull(g.week_runCount,0) as week_runCount,ifnull(h.week_faildCount,0) as week_faildCount,ifnull(g.week_avg_timeCosts,0) as week_avg_timeCosts,ifnull(g.week_max_timeCosts,0) as week_max_timeCosts from (select a.id,c.name as project_name,a.name as process_name,b.user_name,a.create_time,a.update_time from t_ds_process_definition a,t_ds_user b, t_ds_project c where a.user_id=b.id and c.id=a.project_id and a.release_state=$status) d left join (select count(1) as today_faildCount,process_definition_id from t_ds_process_instance where state=6 and start_time>=DATE_FORMAT(NOW(),'%Y-%m-%d 00:00:00') and start_time<=DATE_FORMAT(NOW(),'%Y-%m-%d 23:59:59') group by process_definition_id ) e on d.id=e.process_definition_id left join (select count(1) as today_runCount,avg(UNIX_TIMESTAMP(end_time)-UNIX_TIMESTAMP(start_time)) as today_avg_timeCosts,max(UNIX_TIMESTAMP(end_time)-UNIX_TIMESTAMP(start_time)) as today_max_timeCosts,process_definition_id from t_ds_process_instance where start_time>=DATE_FORMAT(NOW(),'%Y-%m-%d 00:00:00') and start_time<=DATE_FORMAT(NOW(),'%Y-%m-%d 23:59:59') group by process_definition_id ) f on d.id=f.process_definition_id left join (select count(1) as week_runCount,avg(UNIX_TIMESTAMP(end_time)-UNIX_TIMESTAMP(start_time)) as week_avg_timeCosts,max(UNIX_TIMESTAMP(end_time)-UNIX_TIMESTAMP(start_time)) as week_max_timeCosts,process_definition_id from t_ds_process_instance where start_time>=DATE_FORMAT(SUBDATE(CURDATE(),DATE_FORMAT(CURDATE(),'%w')-1), '%Y-%m-%d 00:00:00') and start_time<=DATE_FORMAT(SUBDATE(CURDATE(),DATE_FORMAT(CURDATE(),'%w')-7), '%Y-%m-%d 23:59:59') group by process_definition_id ) g on d.id=g.process_definition_id left join (select count(1) as week_faildCount,process_definition_id from t_ds_process_instance where state=6 and start_time>=DATE_FORMAT(SUBDATE(CURDATE(),DATE_FORMAT(CURDATE(),'%w')-1), '%Y-%m-%d 00:00:00') and start_time<=DATE_FORMAT( SUBDATE(CURDATE(),DATE_FORMAT(CURDATE(),'%w')-7), '%Y-%m-%d 23:59:59') group by process_definition_id ) h on d.id=h.process_definition_id
這些配置完後,保存就可以得到如下的表格:(本文作者:張永清,轉載請註明來源部落格園://www.cnblogs.com/laoqing/p/14538635.html)
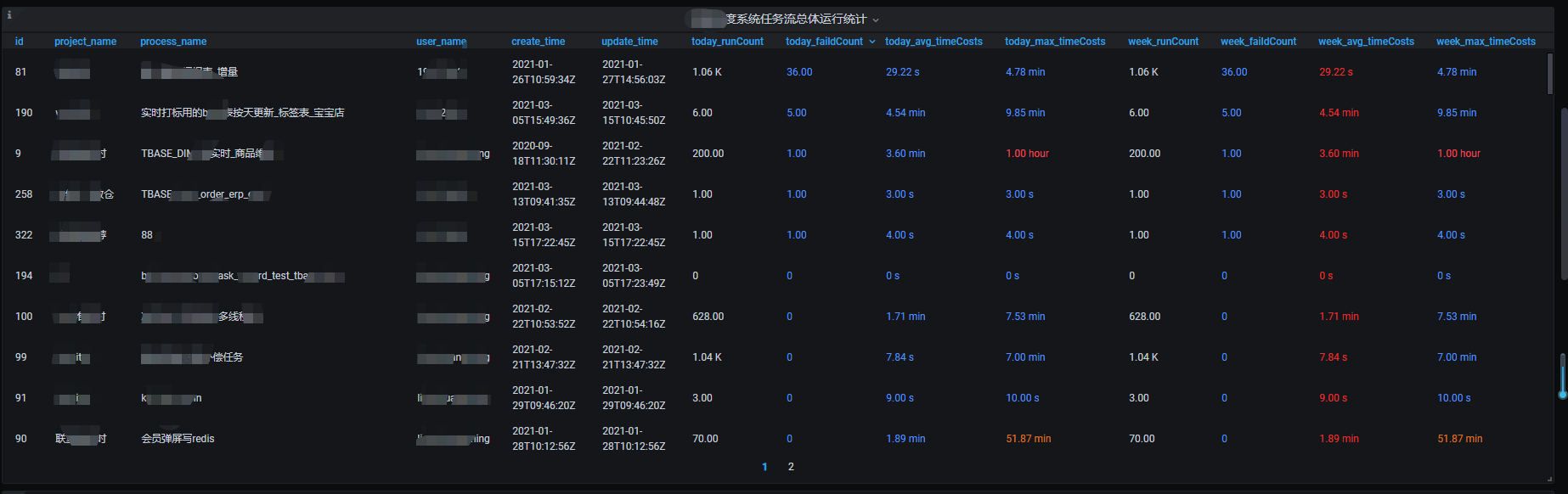
還可以支援甘特圖等多種圖,此處不再一一介紹了。