HDFS 01 – HDFS是什麼?它的適用場景有哪些?它的架構是什麼?
1、HDFS 是什麼
1.1 簡單介紹
在現代的企業環境中,單機容量太小,無法存儲海量的數據,這時候就需要多機器存儲。
—— 統一管理分布在集群上的文件,這樣的系統就稱為分散式文件系統。
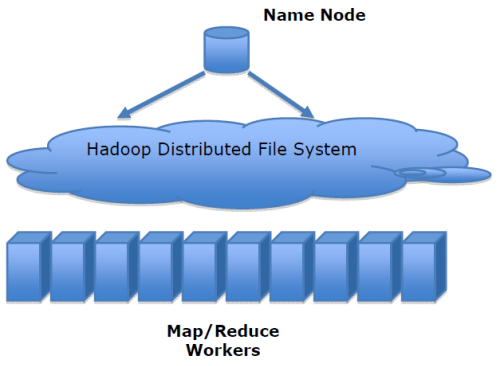
HDFS(Hadoop Distributed File System,Hadoop 分散式文件系統),是 Apache Hadoop 項目的一個子項目。
我們知道,Hadoop 天生就是為了存儲海量數據(比如 TB 和 PB級別)而設計的,它的存儲系統就是 HDFS。
HDFS 使用多台電腦存儲文件,並提供統一的訪問介面,像是訪問一個普通文件系統一樣使用分散式文件系統。
1.2 發展歷史
-
Doug Cutting 在做 Lucene 的時候,需要編寫一個爬蟲服務,過程中遇到了一些問題,諸如:如何存儲大規模的數據,如何保證集群的可伸縮性,如何動態容錯等。
-
2003年的時候,Google 發布了三篇論文,被稱作為三駕馬車,其中有一篇叫做 GFS,描述了 Google 內部的一個叫做 GFS 的分散式大規模文件系統,具有強大的可伸縮性和容錯性。
-
Doug Cutting 後來根據 GFS 的論文, 創造了一個新的文件系統, 叫做 HDFS
2、HDFS 應用場景
2.1 適合的應用場景
- 存儲非常大的文件:這裡非常大指的是成百上千 MB、GB,甚至 TB 級別的文件,需要高吞吐量,對延時沒有要求。
- 採用流式的數據訪問方式:即 一次寫入、多次讀取,數據集經常從數據源生成或者拷貝一次,然後在其上做很多分析工作。
- 運行於廉價的硬體上:不需要性能特別高的機器,可運行於普通廉價機器,節約成本。
- 需要高容錯性,HDFS 有多副本機制,丟失/損壞一定個數的副本後,不影響文件的完整性。
- 用作數據存儲系統,方便橫向擴展。
2.2 不適合的應用場景
-
低延時的數據訪問:對延時要求在毫秒級別的應用,不適合採用 HDFS。HDFS 是為高吞吐數據傳輸設計的,延時較高。
-
大量小文件:HDFS 系統中,文件的元數據保存在 NameNode 的記憶體中, 文件數量會受限於 NameNode 的記憶體大小。
通常,一個文件/目錄/文件塊的元數據記憶體空間約=150Byte。如果有100萬個文件,每個文件佔用1個 block,則需要大約300MB的記憶體。因此十億級別的文件數量在現有商用機器上難以支援。
-
多方讀寫,需要任意的文件修改:HDFS採用追加(append-only)的方式寫入數據。不支援文件任意 offset 的修改,也不支援多個寫入器(writer)。
3、HDFS 的架構
HDFS是一個 主/從(Mater/Slave)體系結構,HDFS由四部分組成,分別是:
HDFS Client、NameNode、DataNode 和 SecondaryNameNode。
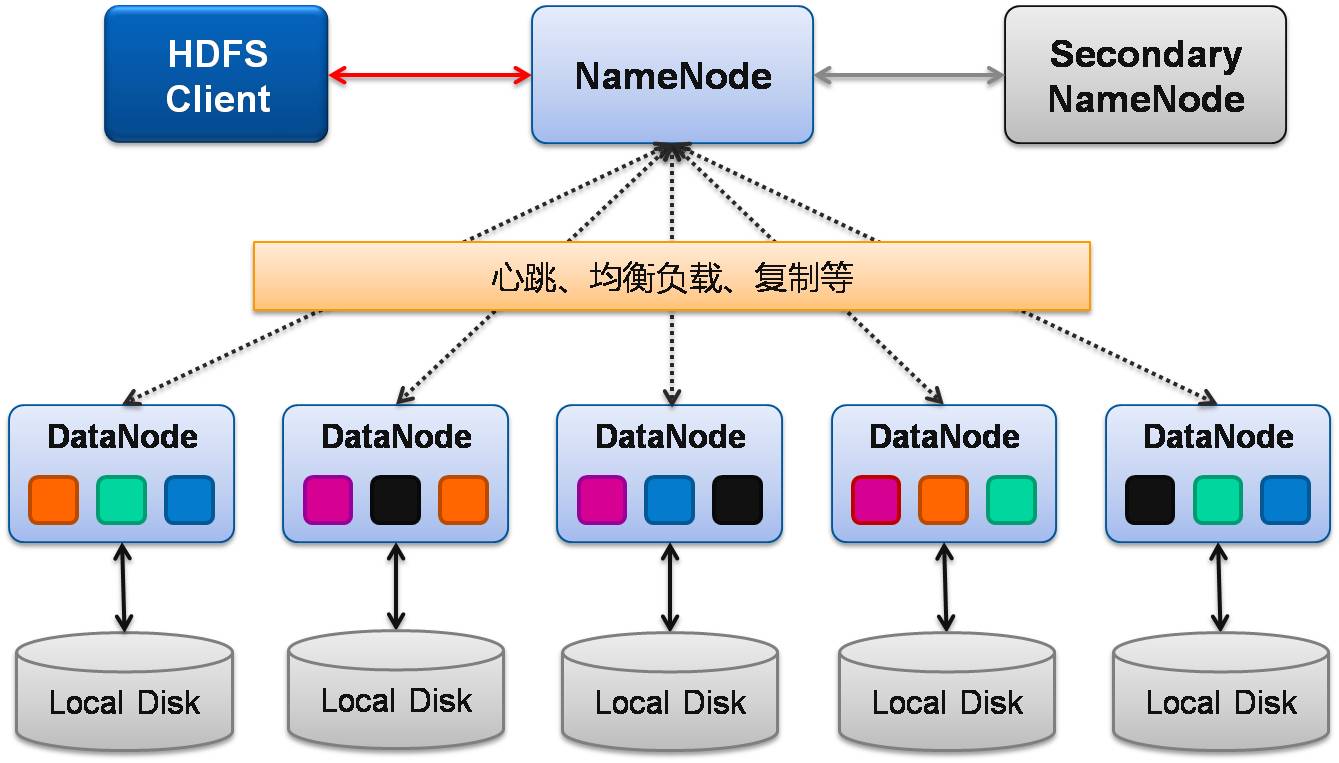
1、Client:就是客戶端。
- 文件切分。文件上傳 HDFS 的時候,Client 將文件切分成多個塊(block),然後存儲。
- 與 NameNode 交互,獲取文件的位置資訊。
- 與 DataNode 交互,讀取、寫入數據。
- Client 提供一些命令來管理和訪問 HDFS,比如啟動、關閉 HDFS。
2、NameNode:就是 master,是管理者。
- 管理 HDFS 的名稱空間。
- 管理數據塊(block)映射資訊。
- 配置副本策略。
- 處理客戶端的讀寫請求。
3、DataNode:就是 Slave。NameNode 下達命令,DataNode 執行實際的操作。
- 存儲實際的數據塊。
- 執行數據塊的讀/寫操作。
4、Secondary NameNode:不是 NameNode 的熱備份 —— NameNode 掛掉的時候,它並不能馬上替換 NameNode 並提供服務。
- 輔助 NameNode,分擔其工作量。
- 定期合併 fsimage 和 fsedits,並推送給 NameNode。
- 在緊急情況下,可輔助恢復 NameNode。
4、NameNode 和 DataNode
4.1 NameNode 的作用
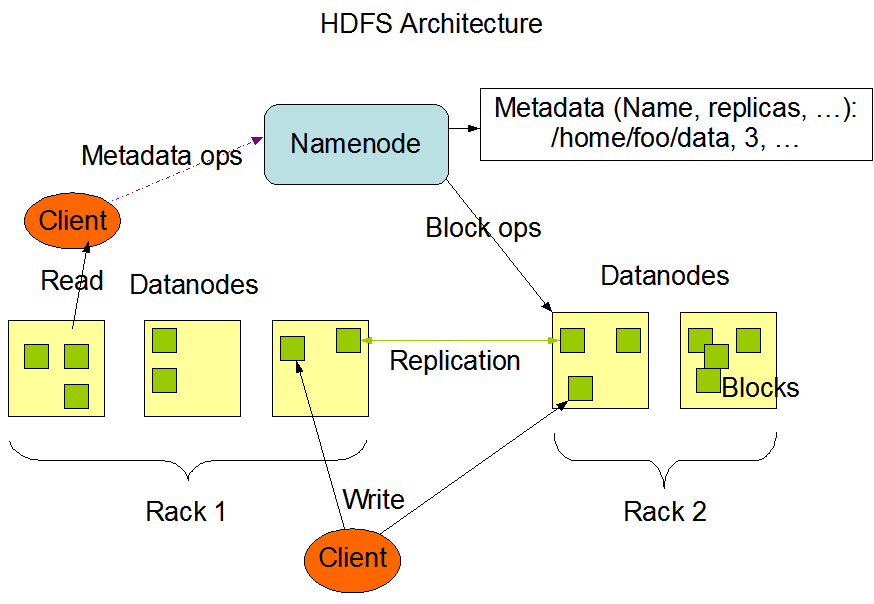
NameNode 在記憶體中保存著整個文件系統的名稱空間和文件數據塊的地址映射。
HDFS 集群可存儲的文件個數受限於 NameNode 的記憶體大小 。
1、NameNode 存儲元數據資訊
元數據包括:文件名,文件目錄結構,文件屬性(生成時間、副本數、許可權等),每個文件的塊列表,以及列表中的塊與塊所在的DataNode 之間的地址映射關係;
在記憶體中載入每個文件和每個數據塊的引用關係(文件、block、DataNode之間的映射資訊);
數據會定期保存到本地磁碟(fsImage 文件和 edits 文件)。
2、NameNode 文件元數據的操作
DataNode 負責處理文件內容的讀寫請求,數據流不會經過 NameNode,而是從 NameNode 獲取數據真正要流向的 DataNode。
3、NameNode 副本
文件數據塊到底存放到哪些 DataNode 上,是由 NameNode 決定的,它會根據全局的情況(機架感知機制),做出副本存放位置的決定。
4、NameNode 心跳機制
全權管理數據塊的複製,周期性的接受心跳和塊的狀態報告資訊(包含該DataNode上所有數據塊的列表)
若接受到心跳資訊,NameNode認為DataNode工作正常,如果在10分鐘後還接受到不到DN的心跳,那麼NameNode認為DataNode已經宕機 ,這時候NN準備要把DN上的數據塊進行重新的複製。 塊的狀態報告包含了一個DN上所有數據塊的列表,blocks report 每個1小時發送一次.
4.2 DataNode 的作用
提供真實文件數據的存儲服務。
-
DataNode 以數據塊的形式存儲 HDFS 文件
-
DataNode 響應 HDFS 客戶端的讀寫請求
-
DataNode 周期性向 NameNode 彙報心跳資訊
-
DataNode 周期性向 NameNode 彙報數據塊資訊
-
DataNode 周期性向 NameNode 彙報快取數據塊資訊
版權聲明
出處:部落格園-瘦風的南牆(//www.cnblogs.com/shoufeng)
感謝閱讀,公眾號 「瘦風的南牆」 ,手機端閱讀更佳,還有其他福利和心得輸出,歡迎掃碼關注🤝
本文版權歸部落客所有,歡迎轉載,但 [必須在頁面明顯位置標明原文鏈接],否則部落客保留追究相關人士法律責任的權利。


