HDFS 01 – HDFS是什么?它的适用场景有哪些?它的架构是什么?
1、HDFS 是什么
1.1 简单介绍
在现代的企业环境中,单机容量太小,无法存储海量的数据,这时候就需要多机器存储。
—— 统一管理分布在集群上的文件,这样的系统就称为分布式文件系统。
HDFS(Hadoop Distributed File System,Hadoop 分布式文件系统),是 Apache Hadoop 项目的一个子项目。
我们知道,Hadoop 天生就是为了存储海量数据(比如 TB 和 PB级别)而设计的,它的存储系统就是 HDFS。
HDFS 使用多台计算机存储文件,并提供统一的访问接口,像是访问一个普通文件系统一样使用分布式文件系统。
1.2 发展历史
-
Doug Cutting 在做 Lucene 的时候,需要编写一个爬虫服务,过程中遇到了一些问题,诸如:如何存储大规模的数据,如何保证集群的可伸缩性,如何动态容错等。
-
2003年的时候,Google 发布了三篇论文,被称作为三驾马车,其中有一篇叫做 GFS,描述了 Google 内部的一个叫做 GFS 的分布式大规模文件系统,具有强大的可伸缩性和容错性。
-
Doug Cutting 后来根据 GFS 的论文, 创造了一个新的文件系统, 叫做 HDFS
2、HDFS 应用场景
2.1 适合的应用场景
- 存储非常大的文件:这里非常大指的是成百上千 MB、GB,甚至 TB 级别的文件,需要高吞吐量,对延时没有要求。
- 采用流式的数据访问方式:即 一次写入、多次读取,数据集经常从数据源生成或者拷贝一次,然后在其上做很多分析工作。
- 运行于廉价的硬件上:不需要性能特别高的机器,可运行于普通廉价机器,节约成本。
- 需要高容错性,HDFS 有多副本机制,丢失/损坏一定个数的副本后,不影响文件的完整性。
- 用作数据存储系统,方便横向扩展。
2.2 不适合的应用场景
-
低延时的数据访问:对延时要求在毫秒级别的应用,不适合采用 HDFS。HDFS 是为高吞吐数据传输设计的,延时较高。
-
大量小文件:HDFS 系统中,文件的元数据保存在 NameNode 的内存中, 文件数量会受限于 NameNode 的内存大小。
通常,一个文件/目录/文件块的元数据内存空间约=150Byte。如果有100万个文件,每个文件占用1个 block,则需要大约300MB的内存。因此十亿级别的文件数量在现有商用机器上难以支持。
-
多方读写,需要任意的文件修改:HDFS采用追加(append-only)的方式写入数据。不支持文件任意 offset 的修改,也不支持多个写入器(writer)。
3、HDFS 的架构
HDFS是一个 主/从(Mater/Slave)体系结构,HDFS由四部分组成,分别是:
HDFS Client、NameNode、DataNode 和 SecondaryNameNode。
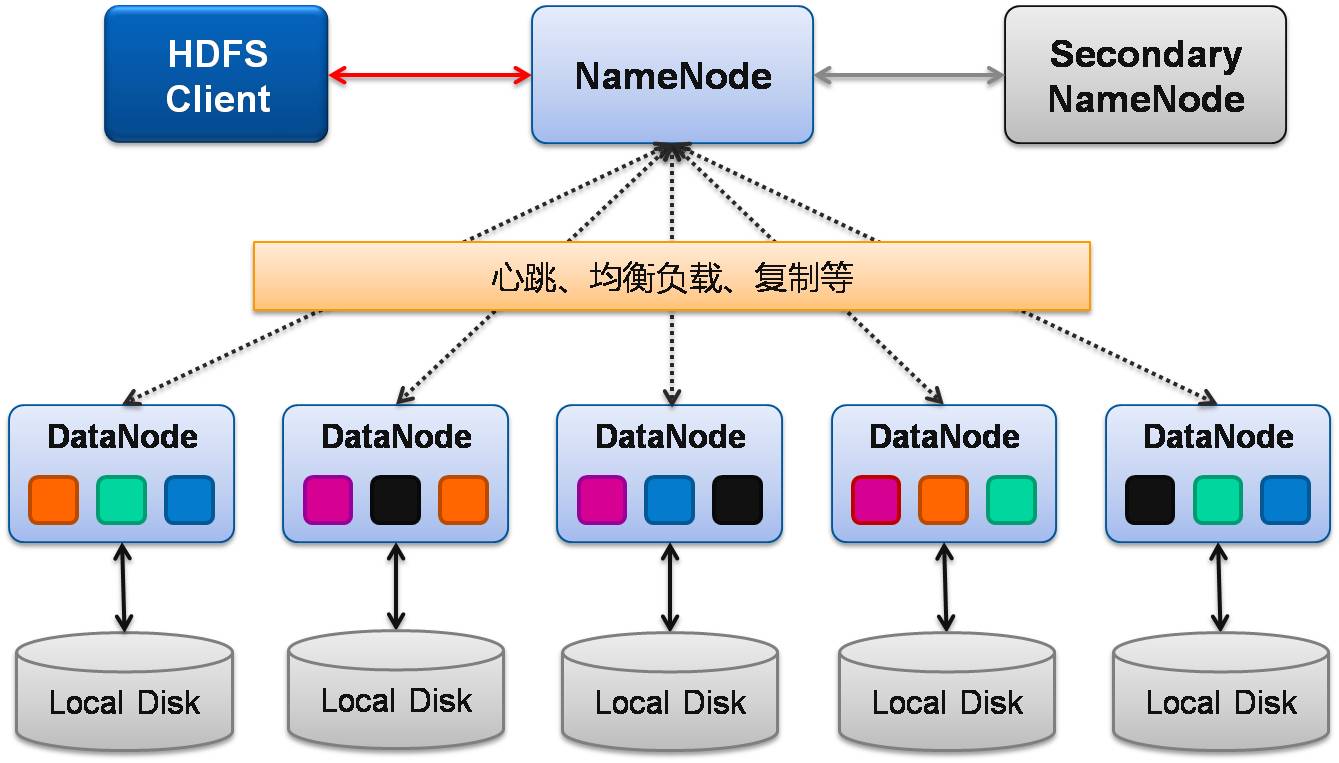
1、Client:就是客户端。
- 文件切分。文件上传 HDFS 的时候,Client 将文件切分成多个块(block),然后存储。
- 与 NameNode 交互,获取文件的位置信息。
- 与 DataNode 交互,读取、写入数据。
- Client 提供一些命令来管理和访问 HDFS,比如启动、关闭 HDFS。
2、NameNode:就是 master,是管理者。
- 管理 HDFS 的名称空间。
- 管理数据块(block)映射信息。
- 配置副本策略。
- 处理客户端的读写请求。
3、DataNode:就是 Slave。NameNode 下达命令,DataNode 执行实际的操作。
- 存储实际的数据块。
- 执行数据块的读/写操作。
4、Secondary NameNode:不是 NameNode 的热备份 —— NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
- 辅助 NameNode,分担其工作量。
- 定期合并 fsimage 和 fsedits,并推送给 NameNode。
- 在紧急情况下,可辅助恢复 NameNode。
4、NameNode 和 DataNode
4.1 NameNode 的作用
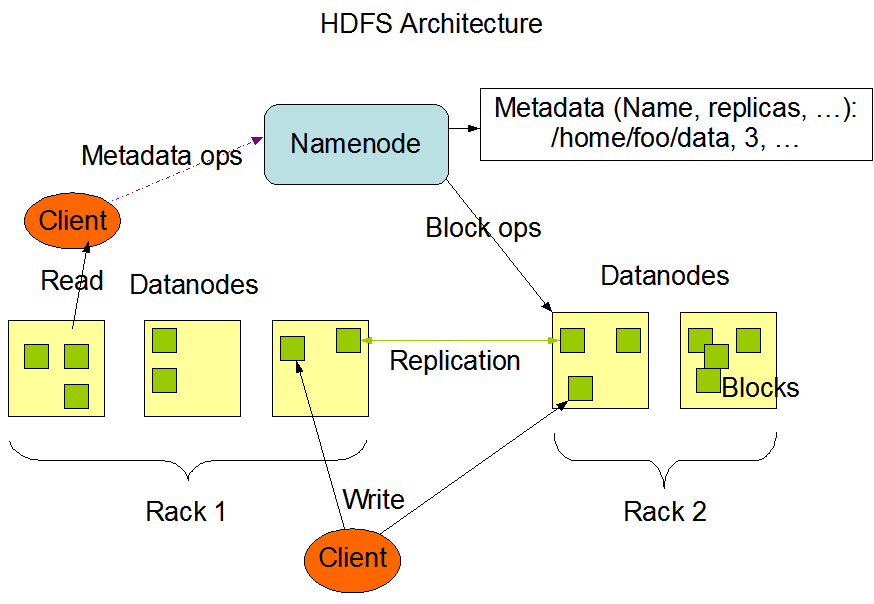
NameNode 在内存中保存着整个文件系统的名称空间和文件数据块的地址映射。
HDFS 集群可存储的文件个数受限于 NameNode 的内存大小 。
1、NameNode 存储元数据信息
元数据包括:文件名,文件目录结构,文件属性(生成时间、副本数、权限等),每个文件的块列表,以及列表中的块与块所在的DataNode 之间的地址映射关系;
在内存中加载每个文件和每个数据块的引用关系(文件、block、DataNode之间的映射信息);
数据会定期保存到本地磁盘(fsImage 文件和 edits 文件)。
2、NameNode 文件元数据的操作
DataNode 负责处理文件内容的读写请求,数据流不会经过 NameNode,而是从 NameNode 获取数据真正要流向的 DataNode。
3、NameNode 副本
文件数据块到底存放到哪些 DataNode 上,是由 NameNode 决定的,它会根据全局的情况(机架感知机制),做出副本存放位置的决定。
4、NameNode 心跳机制
全权管理数据块的复制,周期性的接受心跳和块的状态报告信息(包含该DataNode上所有数据块的列表)
若接受到心跳信息,NameNode认为DataNode工作正常,如果在10分钟后还接受到不到DN的心跳,那么NameNode认为DataNode已经宕机 ,这时候NN准备要把DN上的数据块进行重新的复制。 块的状态报告包含了一个DN上所有数据块的列表,blocks report 每个1小时发送一次.
4.2 DataNode 的作用
提供真实文件数据的存储服务。
-
DataNode 以数据块的形式存储 HDFS 文件
-
DataNode 响应 HDFS 客户端的读写请求
-
DataNode 周期性向 NameNode 汇报心跳信息
-
DataNode 周期性向 NameNode 汇报数据块信息
-
DataNode 周期性向 NameNode 汇报缓存数据块信息
版权声明
出处:博客园-瘦风的南墙(//www.cnblogs.com/shoufeng)
感谢阅读,公众号 “瘦风的南墙” ,手机端阅读更佳,还有其他福利和心得输出,欢迎扫码关注🤝
本文版权归博主所有,欢迎转载,但 [必须在页面明显位置标明原文链接],否则博主保留追究相关人士法律责任的权利。


