80行Python程式碼搞定全國區劃程式碼
微信搜索:碼農StayUp
主頁地址://gozhuyinglong.github.io
源碼分享://github.com/gozhuyinglong/blog-demos
1. 前言
在網站建設中一般會用到全國行政區域劃分,以便於做區域數據分析。
下面我們用 Python 來爬取行政區域數據,數據來源為比較權威的國家統計局。爬取的頁面為2020年統計用區劃程式碼和城鄉劃分程式碼。
這裡有個疑問,為啥統計局只提供了網頁版呢?提供文件版豈不是更方便大眾。歡迎了解的小夥伴給我留言。
2. 網站分析
在爬取數據之前要做的便是網站分析,通過分析來判斷使用何種方式來爬取。
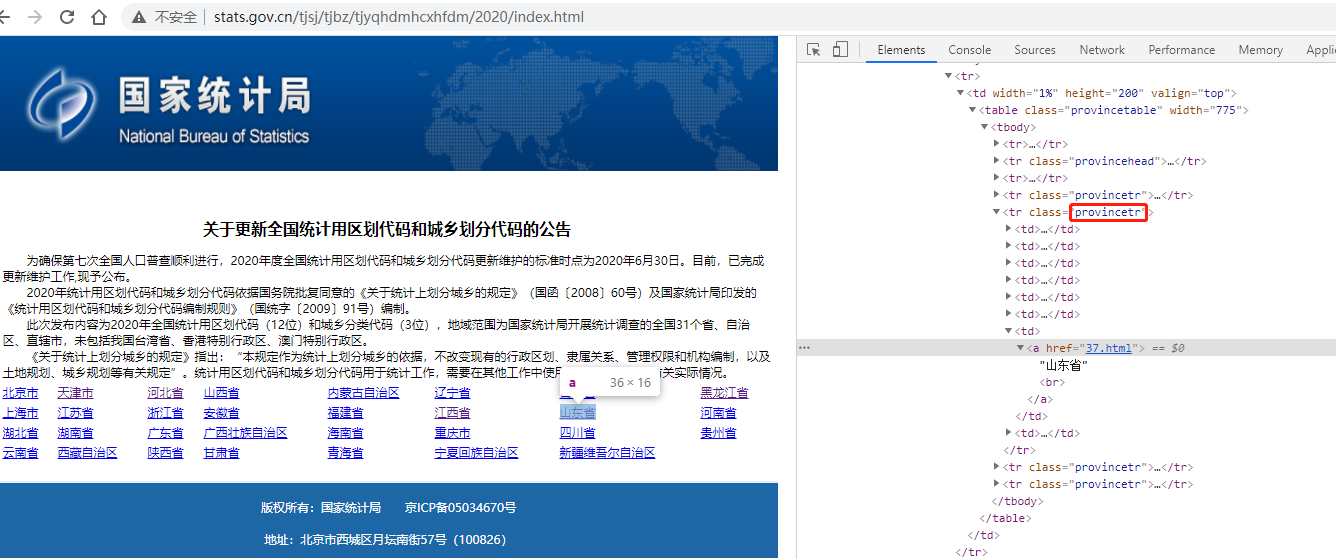
2.1 省份頁面
一個靜態頁面,其二級頁面使用的是相對地址,通過 class=provincetr 的tr元素來定位
2.2 城市頁面
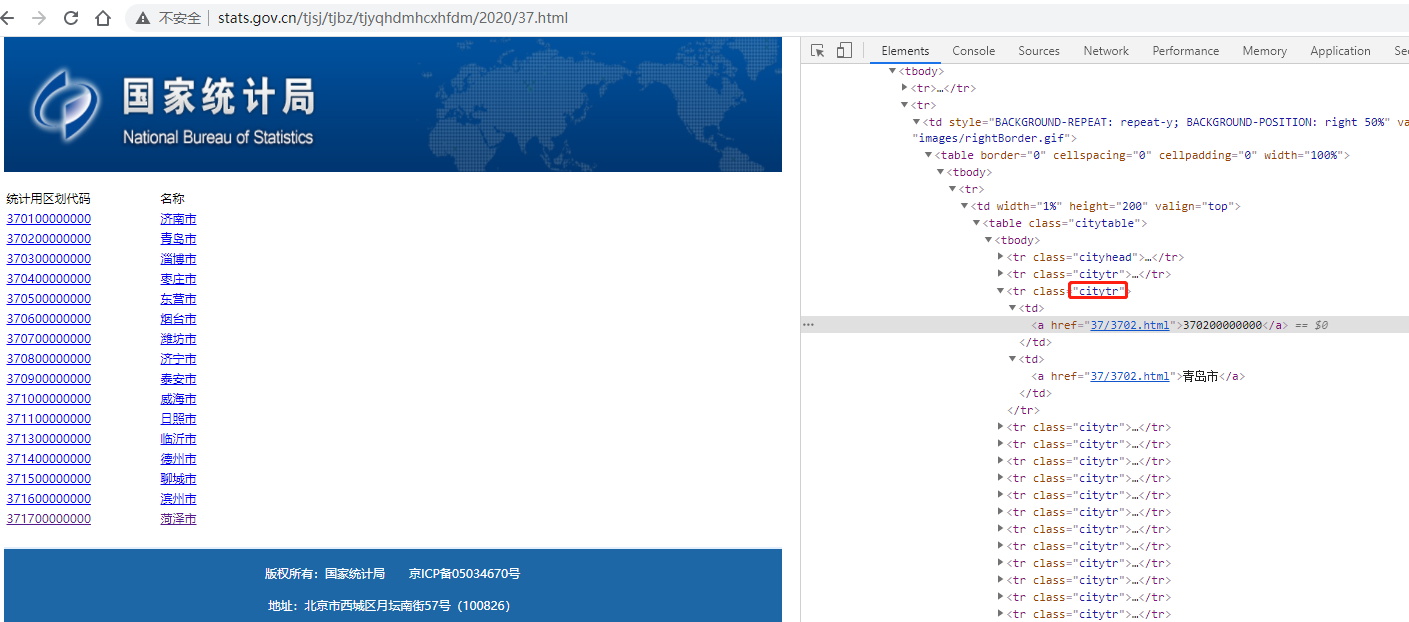
一個靜態頁面,其二級頁面使用的是相對地址,通過 class=citytr 的tr元素來定位
2.3 區縣頁面
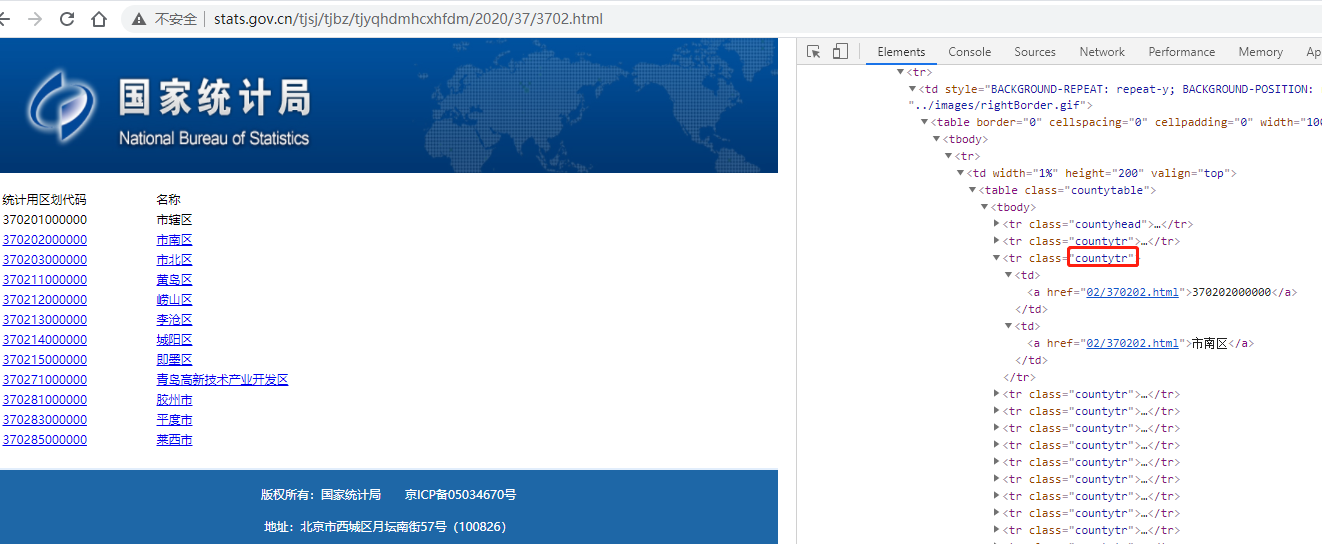
一個靜態頁面,其二級頁面使用的是相對地址,通過 class=countytr 的tr元素來定位
2.4 城鎮頁面
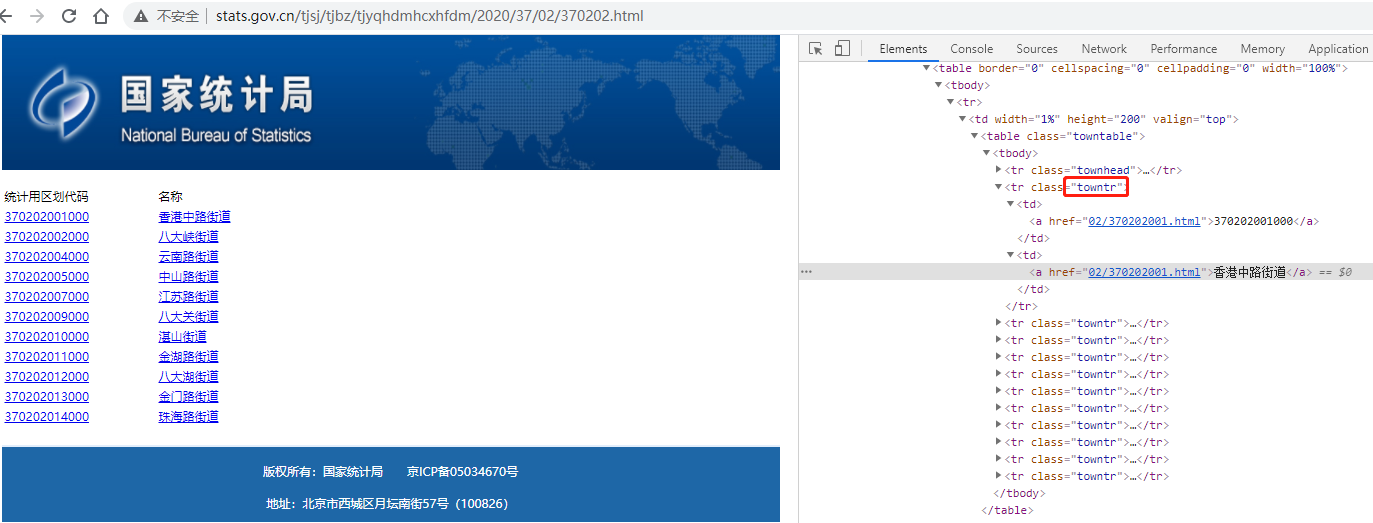
一個靜態頁面,其二級頁面使用的是相對地址,通過 class=towntr 的tr元素來定位
2.5 村莊頁面
一個靜態頁面,沒有二級頁面,通過 class=villagetr 的tr元素來定位
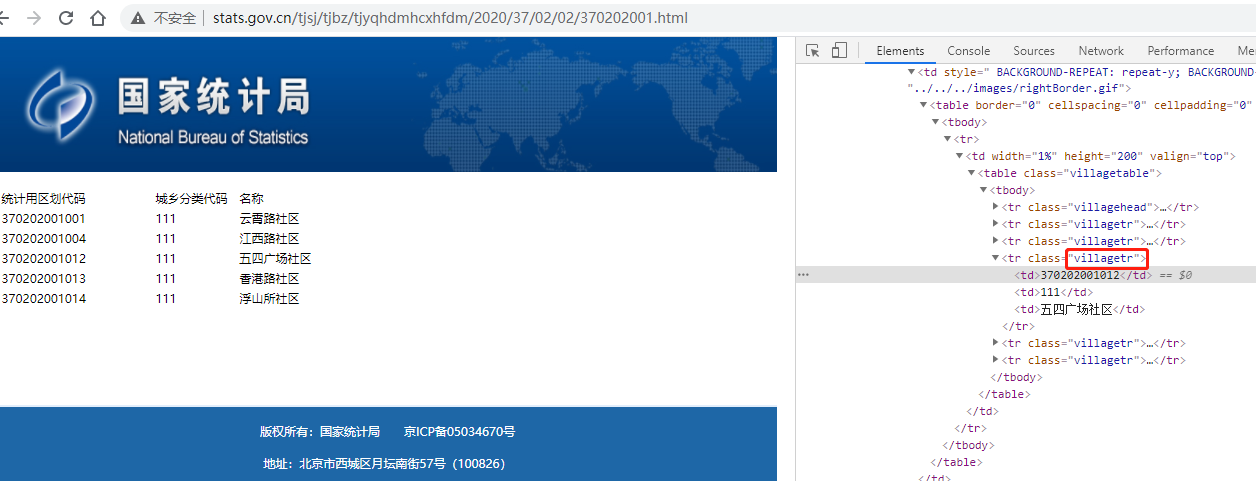
3. 安裝所需庫
通過上面的分析,使用爬取靜態網頁的方式即可。下面是一些必要的庫,需要提前安裝好:Requests、BeautifulSoup、lxml。
3.1 Requests
Requests 是一個 Python 的 HTTP 客戶端庫,用於訪問 URL 網路資源。
安裝Requests庫:
pip install requests
3.2 BeautifulSoup
Beautifu lSoup 是一個可以從 HTML 或 XML 文件中提取數據的 Python 庫。它能夠通過指定的轉換器實現頁面文檔的導航、查找、修改等。
安裝 BeautifulSoup 庫:
pip install beautifulsoup4
3.3 lxml
lxml 是一種使用 Python 編寫的庫,可以迅速、靈活地處理 XML 和 HTML。
它支援 XML Path Language (XPath) 和 Extensible Stylesheet Language Transformation (XSLT),並且實現了常見的 ElementTree API。
安裝lxml庫:
pip install lxml
4. 程式碼實現
爬蟲分以下幾步:
- 使用Requests庫來獲取網頁。
- 使用BeautifulSoup和lxml庫解析網頁。
- 使用Python的File來存儲數據。
輸出文件為:當前py文件所在目錄,文件名稱:area-number-2020.txt
輸出結果為:級別、區劃程式碼、名稱,中間使用製表符分隔,便於存到Exce和資料庫中。
下面看詳細程式碼:
# -*-coding:utf-8-*-
import requests
from bs4 import BeautifulSoup
# 根據地址獲取頁面內容,並返回BeautifulSoup
def get_html(url):
# 若頁面打開失敗,則無限重試,沒有後退可言
while True:
try:
# 超時時間為1秒
response = requests.get(url, timeout=1)
response.encoding = "GBK"
if response.status_code == 200:
return BeautifulSoup(response.text, "lxml")
else:
continue
except Exception:
continue
# 獲取地址前綴(用於相對地址)
def get_prefix(url):
return url[0:url.rindex("/") + 1]
# 遞歸抓取下一頁面
def spider_next(url, lev):
if lev == 2:
spider_class = "city"
elif lev == 3:
spider_class = "county"
elif lev == 4:
spider_class = "town"
else:
spider_class = "village"
for item in get_html(url).select("tr." + spider_class + "tr"):
item_td = item.select("td")
item_td_code = item_td[0].select_one("a")
item_td_name = item_td[1].select_one("a")
if item_td_code is None:
item_href = None
item_code = item_td[0].text
item_name = item_td[1].text
if lev == 5:
item_name = item_td[2].text
else:
item_href = item_td_code.get("href")
item_code = item_td_code.text
item_name = item_td_name.text
# 輸出:級別、區劃程式碼、名稱
content2 = str(lev) + "\t" + item_code + "\t" + item_name
print(content2)
f.write(content2 + "\n")
if item_href is not None:
spider_next(get_prefix(url) + item_href, lev + 1)
# 入口
if __name__ == '__main__':
# 抓取省份頁面
province_url = "//www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2020/index.html"
province_list = get_html(province_url).select('tr.provincetr a')
# 數據寫入到當前文件夾下 area-number-2020.txt 中
f = open("area-number-2020.txt", "w", encoding="utf-8")
try:
for province in province_list:
href = province.get("href")
province_code = href[0: 2] + "0000000000"
province_name = province.text
# 輸出:級別、區劃程式碼、名稱
content = "1\t" + province_code + "\t" + province_name
print(content)
f.write(content + "\n")
spider_next(get_prefix(province_url) + href, 2)
finally:
f.close()
5. 資源下載
如果你只是需要行政區域數據,那麼已經為你準備好了,從下面連接中下載即可。
鏈接://pan.baidu.com/s/18MDdkczwJVuRZwsH0pFYwQ
提取碼:t2eg
6. 爬蟲遵循的規則
引自://www.cnblogs.com/kongyijilafumi/p/13969361.html
- 遵守 Robots 協議,謹慎爬取
- 限制你的爬蟲行為,禁止近乎 DDOS 的請求頻率,一旦造成伺服器癱瘓,約等於網路攻擊
- 對於明顯反爬,或者正常情況不能到達的頁面不能強行突破,否則是 Hacker 行為
- 如果爬取到別人的隱私,立即刪除,降低進局子的概率。另外要控制自己的慾望

