Redis為什麼這麼快
前言
本篇部落格已被收錄GitHub://zhouwenxing.github.io/
在日常開發中,為了保證數據的一致性,我們一般都選擇關係型資料庫來存儲數據,如 MySQL,Oracle 等,因為關係型資料庫有著事務的特性。然而在並發量比較大的業務場景,關係型資料庫卻又往往會成為系統瓶頸,無法完全滿足我們的需求,所以就需要使用到快取,而非關係型資料庫,即 NoSQL 資料庫往往又會成為最佳選擇。
NoSQL 資料庫最常見的解釋是 non-relational,也有人解釋為 Not Only SQL。非關係型資料庫不保證事務,也就是不具備事務 ACID 特性,這也是非關係型資料庫和關係型資料庫最大的區別,而我們即將介紹的 Redis 就屬於 NoSQL 資料庫的一種。
什麼是 Redis
Redis 全稱是:REmote DIctionary Service,即遠程字典服務。Redis 是一個開源的(遵守 BSD 協議)、支援網路、可基於記憶體亦可持久化的日誌型、Key-Value 資料庫。
Redis 具有以下特性:
- 1、支援豐富的數據類型:字元串(strings),散列(hashes),列表(lists),集合(sets),有序集合(sorted sets),點陣圖等。
- 2、功能豐富:提供了持久化機制,過期策略,訂閱/發布等功能。
- 3、高性能,高可用且支援集群。
- 4、提供了多種語言的
API。
Redis 的安裝
- 1、下載對應版本的安裝包,如:Redis 5.0.5 版本,其他版本也可以點擊這裡進行下載。
- 2、下載好之後傳到伺服器指定目錄,執行命令
tar -zxvf redis-5.0.5.tar.gz進行解壓。 - 3、解壓成功之後,進入
Redis主目錄,執行命令make && make install PREFIX=/xxx/xxx/redis-5.0.5進行安裝,如果不指定目錄,則默認是安裝在/usr/local目錄下。 - 4、安裝成功之後可以看到
Redis主目錄下多了一個bin目錄,bin目錄內包含了一些可執行腳本。 - 5、回到
Redis主目錄下,找到redis.conf配置文件,將其中的配置daemonize no修改為daemonize yes,表示在後台啟動服務。 - 6、然後就可以執行命令
/xxx/xxx/redis-5.0.5/bin/redis-server /xxx/xxx/redis-5.0.5/redis.conf啟動Redis服務。
Redis 到底有多快
大家可能都知道 Redis 很快,可是 Redis 到底能有多快呢,比如 Redis 的吞吐量能達到多少?我想這就不是每一個人都能說的上來一個具體的數字了。
Redis 官方提供了一個測試腳本,可以供我們測試 Redis 的 吞吐量。
redis-benchmark -q -n 100000可以測試常用命令的吞吐量。redis-benchmark -t set,lpush -n 100000 -q測試Redis處理set和lpush命令的吞吐量。redis-benchmark -n 100000 -q script load "redis.call('set','foo','bar')"測試Redis處理Lua腳本等吞吐量。
下圖就是我這邊執行第一條命令的自測結果,可以看到大部分命令的吞吐量都可以達到 4 萬以上,也就是說每秒鐘可以處理 4 萬次以上請求:
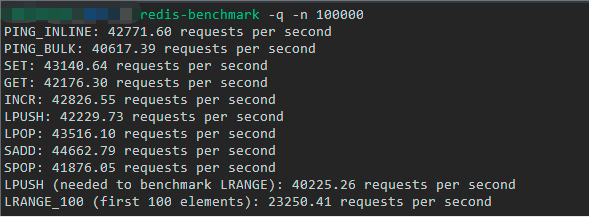
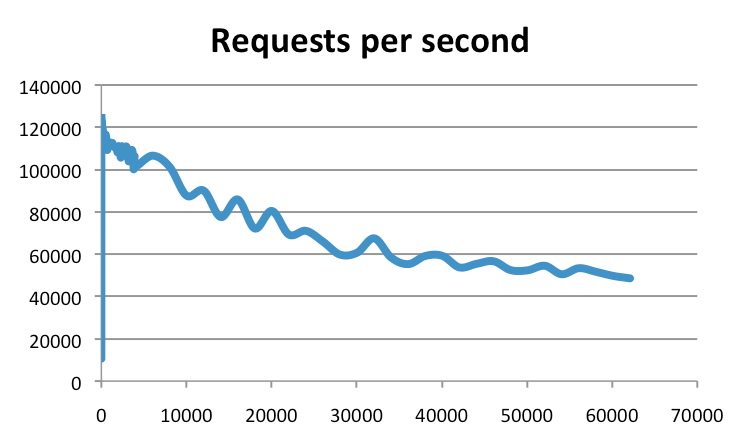
但是如果你以為這就是 Redis 的真實吞吐量,那就錯了。實際上,Redis 官方的測試結果是可以達到 10 萬的吞吐量,下圖就是官方提供的一個基準測試結果(縱坐標就是吞吐量,橫坐標是連接數):
Redis 是單執行緒還是多執行緒
這個問題比較經典,因為在很多人的認知里,Redis 就是單執行緒的。然而 Redis 從 4.0 版本開始就有了多執行緒的概念,雖然處理命令請求的核心模組確實是保證了單執行緒執行,然而在其他許多地方已經有了多執行緒,比如:在後台刪除對象,通過 Redis 模組實現阻塞命令,生成 dump 文件,以及 6.0 版本中網路 I/O 實現了多執行緒等,而且在未來 Redis 應該會有越來越多的模組實現多執行緒。
所謂的單執行緒,只是說 Redis 的處理客戶端的請求(即執行命令)時,是單執行緒去執行的,並不是說整個 Redis 都是單執行緒。
Redis 為什麼選擇使用單執行緒來執行請求
Redis 為什麼會選擇使用單執行緒呢?這是因為 CPU 成為 Redis 瓶頸的情況並不常見,成為 Redis 瓶頸的通常是記憶體或網路頻寬。例如,在一個普通的 Linux 系統上使用 pipelining 命令,Redis 可以每秒完成 100 萬個請求,所以如果我們的應用程式主要使用 O(N) 或 O(log(N)) 複雜度的命令,它幾乎不會使用太多的 CPU。
那麼既然 CPU 不會成為瓶頸,理所當然的就沒必要去使用多執行緒來執行命令,我們需要明確的一個問題就是多執行緒一定比單執行緒快嗎?答案是不一定。因為多執行緒也是有代價的,最直接的兩個代價就是執行緒的創建和銷毀執行緒(當然可以通過執行緒池來一定程度的減少頻繁的創建執行緒和銷毀執行緒)以及執行緒的上下文切換。
在我們的日常系統中,主要可以區分為兩種:CPU 密集型 和 IO 密集型。
- CPU 密集型:這種系統就說明
CPU的利用率很高,那麼使用多執行緒反而會增加上下文切換而帶來額外的開銷,所以使用多執行緒效率可能會不升反降。舉個例子:假如你現在在幹活,你一直不停的在做一件事,需要1分鐘可以做完,但是你中途總是被人打斷,需要花1秒鐘時間步行到旁邊去做另一件事,假如這件事也需要1分鐘,那麼你因為反覆切換做兩件事,每切換一次就要花1秒鐘,最後做完這2件事的時間肯定大於2分鐘(取決於中途切換的次數),但是如果中途不被打斷,你做完一件事再去做另一件事,那麼你最多只需要切換1次,也就是2分1秒就能做完。 - IO 密集型:
IO操作也可以分為磁碟IO和網路IO等操作。大部分IO操作的特點是比較耗時且CPU利用率不高,所以Redis 6.0版本網路IO會改進為多執行緒。至於磁碟IO,因為Redis中的數據都存儲在記憶體(也可以持久化),所以並不會過多的涉及到磁碟操作。舉個例子:假如你現在給樹苗澆水,你每澆完一次水之後就需要等別人給你加水之後你才能繼續澆,那麼假如這個等待過程需要5秒鐘,也就是說你澆完一次水就可以休息5秒鐘,而你切換去做另一件事來回只需要2秒,那麼你完全可以先去做另一件事,做完之後再回來,這樣就可以充分利用你空閑的5秒鐘時間,從而提升了效率。
使用多執行緒還會帶來一個問題就是數據的安全性,所以多執行緒編程都會涉及到鎖競爭,由此也會帶來額外的開銷。
什麼是 I/O 多路復用
I/O 指的是網路 I/O, 多路指的是多個 TCP 連接(如 Socket),復用指的是復用一個或多個執行緒。I/O 多路復用的核心原理就是不再由應用程式自己來監聽連接,而是由伺服器內核替應用程式監聽。
在 Redis 中,其多路復用有多種實現,如:select,epoll,evport,kqueue 等。
我們用去餐廳吃飯為的例子來解釋一下 I/O 多路復用機制(點餐人相當於客戶端,餐廳的廚房相當於伺服器,廚師就是執行緒)。
- 阻塞
IO:張三去餐廳吃飯,點了一道菜,這時候他啥事也不幹了,就是一直等,等到廚師炒好菜,他就把菜端走開始吃飯了。也就是在菜被炒好之前,張三被阻塞了,這就是BIO(阻塞IO),效率會非常低下。 - 非阻塞
IO:張三去餐廳吃飯,點了一道菜,這時候張三他不會一直等,找了個位置坐下,刷刷抖音,打打電話,做點其他事,然後每隔一段時間就去廚房問一下自己的菜好了沒有。這種就屬於非阻塞IO,這種方式雖然可以提高性能,但是如果有大量IO都來定期輪詢,也會給伺服器造成非常大的負擔。 - 事件驅動機制:張三去餐廳吃飯,點了一道菜,這時候他找了個位置坐下來等:
- 廚房那邊菜做好了就會把菜端出來了,但是並不知道這道菜是誰的,於是就挨個詢問顧客,這就是多路復用中的
select模型,不過select模型最多只能監聽1024個socket(poll模型解決了這個限制問題)。 - 廚房做好了菜直接把菜放在窗口上,大喊一聲,某某菜做好了,是誰的快過來拿,這時候聽到通知的人就會自己去拿,這就是多路復用中的
epoll模型。
- 廚房那邊菜做好了就會把菜端出來了,但是並不知道這道菜是誰的,於是就挨個詢問顧客,這就是多路復用中的
需要注意的是在 IO 多路復用機制下,客戶端可以阻塞也可以選擇不阻塞(大部分場景下是阻塞 IO),這個要具體情況具體分析,但是在多路復用機制下,服務端就可以通過多執行緒(上面示例中可以多幾個廚師同時炒菜)來提升並發效率。
Redis 中 I/O 多路復用的應用
Redis 伺服器是一個事件驅動程式,伺服器需要處理兩類事件:文件事件和時間事件。
- 文件事件:
Redis伺服器和客戶端(或其他伺服器)進行通訊會產生相應的文件事件,然後伺服器通過監聽並處理這些事件來完成一系列的通訊操作。 - 時間事件:
Redis內部的一些在給定時間之內需要進行的操作。
Redis 的文件事件處理器以單執行緒的方式運行,其內部使用了 I/O 多路復用程式來同時監聽多個套接字(Socket)連接,提升了性能的同時又保持了內部單執行緒設計的簡單性。下圖就是文件事件處理器的示意圖:
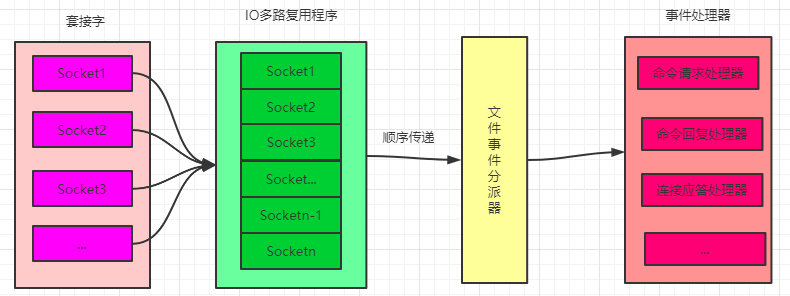
I/O 多路復用程式雖然會同時監聽多個 Socket 連接,但是其會將監聽的 Socket 都放到一個隊列裡面,然後通過這個隊列有序的,同步的將每個 Socket 對應的事件傳送給文件事件分派器,再由文件事件分派器分派給對應的事件處理器進行處理,只有當一個 Socket 所對應的事件被處理完畢之後,I/O多路復用程式才會繼續向文件事件分派器傳送下一個 Socket 所對應的事件,這也可以驗證上面的結論,處理客戶端的命令請求是單執行緒的方式逐個處理,但是事件處理器內並不是只有一個執行緒。
Redis 為什麼這麼快
Redis 為什麼這麼快的原因前面已經基本提到了,現在我們再進行總結一下:
- 1、
Redis是一款純記憶體結構,避免了磁碟I/O等耗時操作。 - 2、
Redis命令處理的核心模組為單執行緒,減少了鎖競爭,以及頻繁創建執行緒和銷毀執行緒的代價,減少了執行緒上下文切換的消耗。 - 3、採用了
I/O多路復用機制,大大提升了並發效率。


