聊聊自學大數據flume中容易被人忽略的細節
- 2020 年 12 月 21 日
- 筆記
- Flume, 大數據, 大數據flume細節, 大數據開發

前言:老劉不敢保證說的有多好,但絕對是非常良心地講述自學大數據開發路上的一些經歷和感悟,保證會講述一些不同於別人技術部落格的細節。
01 自學flume的細節
老劉現在想寫點有自己特色的東西,講講自學大數據遇到的一些事情,保證講一些別人技術部落格里忽略的知識點。
很多自學編程的人都會有一個問題,特別是研二即將找工作的小夥伴,因為馬上就要找工作了,自學時間不多了,所以在自學的路上,常常會忽略很多細小但很重要的知識點,很多夥伴都是直接背一些機構的資料。
自己沒有靜下心來好好研究各個知識點,也沒有考慮這些機構寫的知識點的對錯,完全照搬資料上的知識點,沒有形成自己的理解,這是非常危險的!
從今天開始,老劉就來給大家講講自學大數據開發路上的那些容易被人忽略的細節,讓大家對知識點形成自己的理解。
1、什麼是flume?
在解釋什麼是flume這類知識點上,很多機構的資料或者網上的技術部落格講的都不好,很多培訓機構的資料是這樣形容的「Flume是一個高可用,高可靠,分散式的海量日誌採集、聚合和傳輸的系統」。
一般都會覺得這句話沒啥問題,但是好好想想,這句話是不是相當於這個場景,男女相親,男方說我有車有房,但是沒有說是什麼車,什麼房,自行車也是車,租的房也是房啊!所以在說有車有房的時候,一定要拿出確鑿的證據。
所以呢,當面試的時候,直接說flume是一個高可用,高可靠,分散式的海量日誌採集、聚合和傳輸的系統是非常沒有說服力的,非常典型的照搬資料,沒有自己的理解。
它是如何做到高可用,高可靠,分散式也需要講一講,這樣才覺得可靠!這就是老劉說的和別人不一樣的地方,真的良心分享!
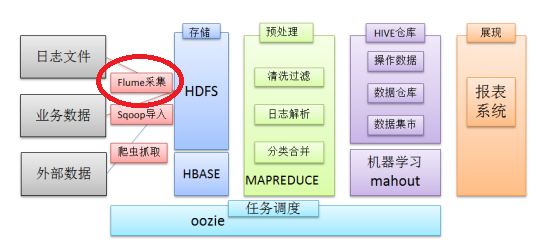
老劉覺得可以這樣說在一個完整的離線大數據處理系統中,除了hdfs+mapreduce+hive組成分析系統的核心之外,還需要數據採集、結果數據導出、任務調度等不可或缺的輔助系統,而這些輔助工具在hadoop生態體系中都有便捷的開源框架。
其中,flume就是一個日誌採集、聚合和傳輸系統的開源框架,它的高可用、高可靠、分散式這些特點,一般都是通過部署多個伺服器,然後在每個伺服器上部署flume agent模式形成的,並且flume通過事務機制保證了數據傳輸的完整性和準確性,flume事務在後面講。
flume的概念就講這麼多,這樣說的目的主要是不想讓大家照搬機構資料的內容,自己多想想,要有自己的理解。
2、flume架構

看到這個架構圖,老劉直接先說說flume是怎麼工作的?
外部數據源以特定格式向flume發送events事件,當source接收到events時,它將其存儲到一個或多個channel,channel會一直保存events直到它被sink消費。sink的主要功能是從channel中讀取events,並將其存入外部存儲系統或轉發到下一個source,成功後再從channe移除events。
接著講講各個組件agent、source、channe、sink。
agent
它是一個JVM進程,它以事件的形式將數據從源頭送至目的。
source
它是一個採集組件,用來獲取數據。
channel
它是一個傳輸通道組件,用來快取數據,用於從將source的數據傳遞到sink。
sink它
是一個下沉組件,它將數據發送給最終的存儲系統或者下一個agent。
3、flume事務
flume事務是非常非常重要的,之前就說過通過flume事務,實現了傳輸數據的完整性和準確性。
先看看這張圖:
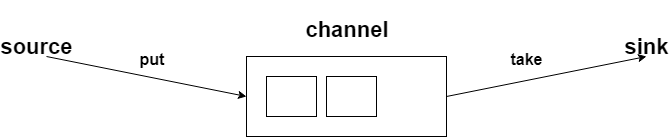
flume它有兩個事務,分別是put事務、take事務。
put事務的步驟分為兩步:
doput,它先將此數據寫入到臨時緩衝區putlist裡面;
docommit,它會去檢查channel裡面有沒有空位置,如果有空位置就會傳入數據;如果channel裡面沒有空位置,那就會把數據回滾到putlist裡面。
take事務也分為兩步:
dotake,它會將數據讀取到臨時緩衝區takelist,並把數據傳到hdfs上;
docommit,它會去判斷數據是否上傳成功,若成功那麼就會清除臨時緩衝區takelist里的數據;若不成功,比如hdfs發生崩潰啥的,那就會回滾數據到channel裡面。
通過講述兩個事務的步驟,是不是就知道了為什麼flume會保證傳輸數據的完整和準確。
老劉總結一下就是,數據在傳輸到下一個節點時,假設接收節點出現異常,比如網路異常之類的,那就會回滾這一批數據,因此就會導致數據重發。
那在同一個節點內,source寫入數據到channel,數據在一個批次內出現異常,那就會不寫入到channel中,已經接收到的部分數據會被直接拋棄,靠上一個節點重發數據。
通過這兩個事務,flume就提高了數據傳輸的完整性、準確性。
4、flume實戰
這部分是flume最重要的,作為一個日誌採集框架,flume的應用比它的概念還要重要,一定要知道flume要怎麼用!老劉最開始壓根就沒看這部分,光看知識點了,現在才發現實戰的重要性!
但是flume實戰案例數不勝數,我們難道要記住每一個案例嗎?
當然不是,這個flume案例我們可以根據官網裡的配置文件進行配置,如下圖:
看左下角藍色方框里的內容,就可以查詢到相關配置文件。在這裡老劉有句話說,如果想學習一個新的框架,咱們的學習資料就是官網,通過官網學習,不僅能提升技術,還能提高英語,且不美滋滋!
現在開始講案例,第一個是採集文件到HDFS,需求就是監控一個文件如果有新增的內容就把數據採集到HDFS上。
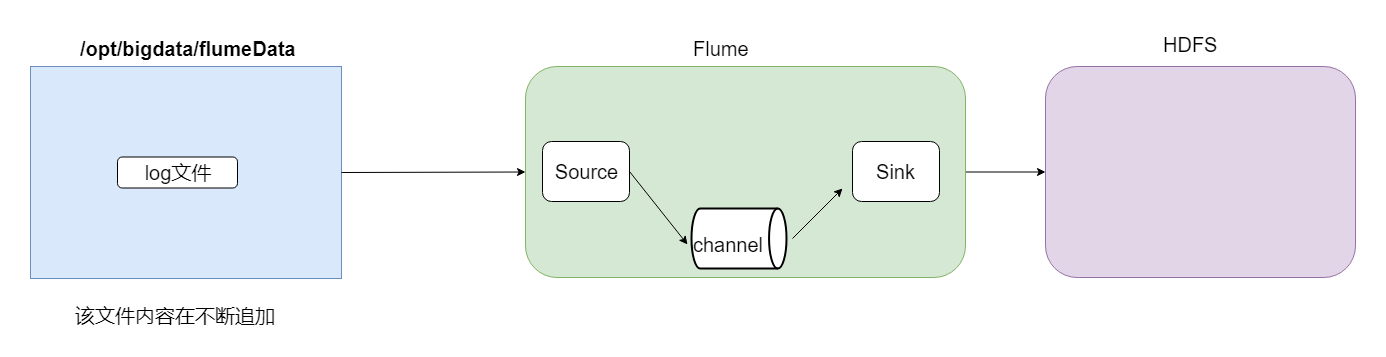
根據官網資料,flume配置文件開發需要在flume安裝目錄下創建一個文件夾,後期存放flume開發的配置文件。
根據需求的描述,source的配置應該選擇為exec;為了保證數據不丟失,channel的配置應該選擇file;sink的配置應該選擇為hdfs。
這樣雖然已滿足需求,但是我們做數據開發,肯定會存在非常多的小文件,一定要做相關的優化。例如,文件小,文件多怎麼解決?文件目錄多怎麼解決?
所以我們還要選擇一些參數來控制參數和目錄。
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 #配置source #指定source的類型為exec,通過unix命令來傳輸結果數據 a1.sources.r1.type = exec #監控這個文件,有新的數據產生就不斷採集 a1.sources.r1.command = tail -F /opt/bigdata/flumeData/tail.log #指定source的數據流入到channel中 a1.sources.r1.channels = c1 #配置channel #選擇file,就是保證數據不丟失,即使出現火災或者洪災 a1.channels.c1.type = file #設置檢查點目錄--該目錄是記錄下event在數據目錄下的位置 a1.channels.c1.checkpointDir=/kkb/data/flume_checkpoint #數據存儲所在的目錄 a1.channels.c1.dataDirs=/kkb/data/flume_data #配置sink a1.sinks.k1.channel = c1 #指定sink類型為hdfs a1.sinks.k1.type = hdfs #指定數據收集到hdfs目錄 a1.sinks.k1.hdfs.path = hdfs://node01:9000/tailFile/%Y-%m-%d/%H%M #指定生成文件名的前綴 a1.sinks.k1.hdfs.filePrefix = events- #是否啟用時間上的」捨棄」 -->控制目錄 a1.sinks.k1.hdfs.round = true #時間上進行「捨棄」的值 # 如 12:10 -- 12:19 => 12:10 # 如 12:20 -- 12:29 => 12:20 a1.sinks.k1.hdfs.roundValue = 10 #時間上進行「捨棄」的單位 a1.sinks.k1.hdfs.roundUnit = minute # 控制文件個數 #60s或者50位元組或者10條數據,誰先滿足,就開始滾動生成新文件 a1.sinks.k1.hdfs.rollInterval = 60 a1.sinks.k1.hdfs.rollSize = 50 a1.sinks.k1.hdfs.rollCount = 10 #每個批次寫入的數據量 a1.sinks.k1.hdfs.batchSize = 100 #開始本地時間戳--開啟後就可以使用%Y-%m-%d去解析時間 a1.sinks.k1.hdfs.useLocalTimeStamp = true #生成的文件類型,默認是Sequencefile,可用DataStream,則為普通文本 a1.sinks.k1.hdfs.fileType = DataStream
第二個是採集目錄到HDFS,如果一個目錄中不斷產生新的文件,就需要把目錄中的文件不斷地進行數據傳輸到HDFS上。
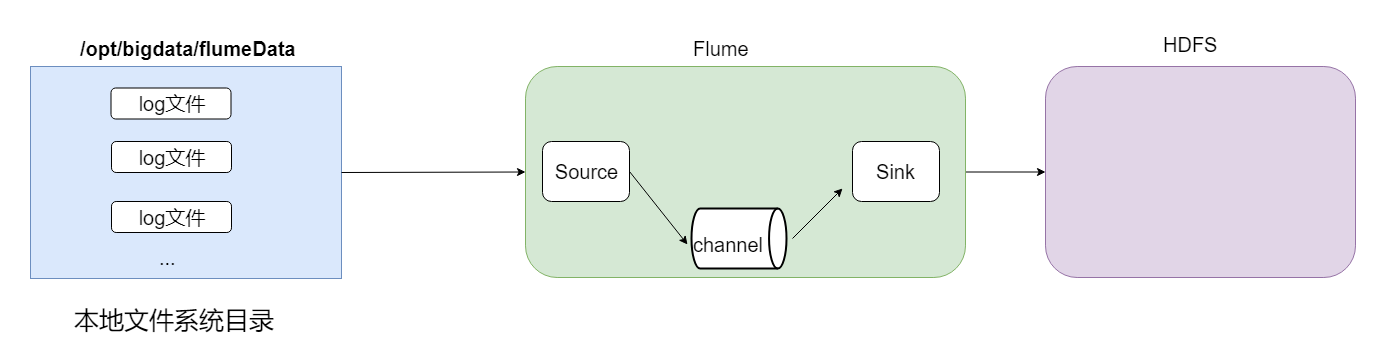
採集目錄的話,source的配置一般採用spooldir;channel的配置可以設置為file,也可以設置為別的,一般為memory;sink的配置還是設置為hdfs。
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 配置source ##注意:不能往監控目中重複丟同名文件 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /opt/bigdata/flumeData/files # 是否將文件的絕對路徑添加到header a1.sources.r1.fileHeader = true a1.sources.r1.channels = c1 #配置channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 #配置sink a1.sinks.k1.type = hdfs a1.sinks.k1.channel = c1 a1.sinks.k1.hdfs.path = hdfs://node01:9000/spooldir/%Y-%m-%d/%H%M a1.sinks.k1.hdfs.filePrefix = events- a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.hdfs.rollInterval = 60 a1.sinks.k1.hdfs.rollSize = 50 a1.sinks.k1.hdfs.rollCount = 10 a1.sinks.k1.hdfs.batchSize = 100 a1.sinks.k1.hdfs.useLocalTimeStamp = true #生成的文件類型,默認是Sequencefile,可用DataStream,則為普通文本 a1.sinks.k1.hdfs.fileType = DataStream
最後再說一個兩個agent串聯,就是第一個agent負責監控某個目錄中新增的文件進行數據收集,通過網路發送到第二個agent當中去,第二個agent負責接收第一個agent發送的數據,並將數據保存到hdfs上面去。
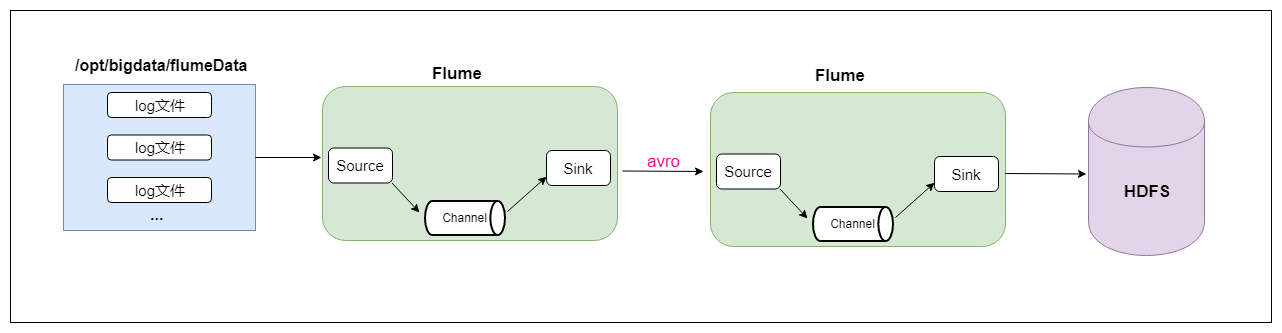
雖然是兩個agent串聯,但只要看了官網的配置文件以及經過之前的兩個案例,這兩個agent串聯難度也是很一般的。
首先是agent的配置文件是這樣的:
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 配置source ##注意:不能往監控目中重複丟同名文件 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /opt/bigdata/flumeData/files a1.sources.r1.fileHeader = true a1.sources.r1.channels = c1 #配置channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 #配置sink a1.sinks.k1.channel = c1 #AvroSink是用來通過網路來傳輸數據的,可以將event發送到RPC伺服器(比如AvroSource) a1.sinks.k1.type = avro #node02 注意修改為自己的hostname a1.sinks.k1.hostname = node02 a1.sinks.k1.port = 4141
agent2的配置文件是這樣的:
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 #配置source #通過AvroSource接受AvroSink的網路數據 a1.sources.r1.type = avro a1.sources.r1.channels = c1 #AvroSource服務的ip地址 a1.sources.r1.bind = node02 #AvroSource服務的埠 a1.sources.r1.port = 4141 #配置channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 #配置sink a1.sinks.k1.channel = c1 a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = hdfs://node01:9000/avro-hdfs/%Y-%m-%d/%H-%M a1.sinks.k1.hdfs.filePrefix = events- a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.hdfs.rollInterval = 60 a1.sinks.k1.hdfs.rollSize = 50 a1.sinks.k1.hdfs.rollCount = 10 a1.sinks.k1.hdfs.batchSize = 100 a1.sinks.k1.hdfs.useLocalTimeStamp = true #生成的文件類型,默認是Sequencefile,可用DataStream,則為普通文本 a1.sinks.k1.hdfs.fileType = DataStream
最後運行的時候,先啟動node02上的flume,然後在啟動node01上的flume。
02 flume細節的總結
老劉這次講了flume的四個容易被忽略的細節,就是想提醒自學的小夥伴們要注意細節,絕對不能完全照搬資料上說的內容,對每個知識點一定要有自己的理解。
最後,如果覺得有哪裡寫的不好或者有錯誤的地方,可以聯繫公眾號:努力的老劉,進行交流。希望能夠對大數據開發感興趣的同學有幫助,希望能夠得到同學們的指導。
如果覺得寫的不錯,給老劉點個贊!


