回顧·攜程HBase實踐
- 2019 年 11 月 23 日
- 筆記

本文由DataFun社區根據攜程魏寧、顏志遠倆位老師在中國HBase技術社區第四屆MeetUp上海站中分享的《攜程HBase實踐》編輯整理而成。

今天分享的內容主要是攜程在HBase使用上的一些概況、場景以及在監控、客戶端、版本遷移/升級方面的一些工作,此外還有日常工作中的幾個問題和案例。

一、概況
目前我們使用的HBase版本為1.2.0-cdh5.7.1版,表的數量1000張以上,大表超過了100TB。白天QPS請求在5百萬上下,在促銷或者旅遊旺季更大,每天寫入HDFS數據量在50TB左右。主要場景有用戶行為數據採集(用戶的點擊、瀏覽等資訊都在HBase上提供給後方用戶畫像使用),還有風控,用戶產生的每一筆訂單和交易都會觸發一些風控規則的校驗。還有就是自研類OpenTSDB,將埋點數據分析給應用,查看應用請求量和延遲等資訊。還有就是廣告,主要用途是提供精準營銷、千人千面的廣告展示。

以廣告為例,我們來看一下HBase的應用。數據來源主要有網站的業務系統、各個BU以及來自站外合作夥伴的數據,首先數據先進入Hermes消息隊列裡面,通過Jstorm job寫入到HBase。當用戶瀏覽網站或者使用APP或有廣告投放站點時就會觸發廣告服務,根據用戶標籤或用戶id等從HBase查詢內容返回給用戶,由於HBase查詢是根據用戶的每次點擊實時查詢的,因此對於一些響應的延遲是非常敏感的,採用SSD技術緩解延遲,目前集群訪問延遲基本控制在10ms以內。
除了以上場景外,其他所有業務線都用到了HBase。使用方式基本類似,實時寫一般通過Jstorm/HBaseAPI寫入HBase,批量寫一般通過SPARK/MR/Hive/Kylin等,應用讀取HBase再去使用。

二、監控
大致思路是首先採集數據,包括來自hickwall監控平台的OS性能數據、來自jmx或者API採集的HBase性能數據和HDFS性能數據以及來自zookeeper的其它數據。數據落地到inflexDB,然後在Griffin上展示,同時依據一些規則產生一些告警。

下圖列出了一些常用指標如連接數、響應時間和處理時間,通過請求數判斷業務情況。有讀請求、寫請求以及總請求,跟性能有關的請求大小。一般監控比較感興趣的是flash隊列、Compaction隊列,flash隊列請求比較大意味著機群的寫負載比較重,如果高峰期Compaction隊列有積壓需要調整Compaction策略,避免業務高峰期影響性能。Blockcache命中率對讀寫性能影響比較大,如果讀的時候不能在快取中命中就需要在磁碟中讀取,這樣讀寫延遲比較高。Hlog、Storefile文件數過大,則表明寫的負載比較重,也會根據Storefile文件大小,如Regionserver上總Storefile文件大小預估Major Compaction的消耗。Major Compaction將所有數據讀出來寫成一個新的文件,如果Storefile很大,預示著Compaction消耗也很大。

有可能我們除了讀請求之外,還可能想關注Get次數和Scan的次數,在了解了是寫請求之外,還有可能想了解put次數。接下來還有GC的次數與GC的耗時,如果GC的頻率很高,耗時也很長的話,那往往意味著集群可能存在著一些問題,就需要具體分析。除了這些官方的指標之外,我們通過修改源程式碼,新加了一些指標,具體指標如下圖所示。

我們有一個需求:希望從用戶角度去感知集群的健康狀況,所以開發了模仿用戶檢測異常的功能,其思路是建一個表,建表的時候首先會知道集群有多少RegionServer,根據RegionServer數量進行預分區,構建Region;檢查確保每個RegionServer上都有Region;然後每個一段時間對所有RegionServer 進行put/scan一行,分別獲取耗時。這樣得到一個直觀的數據可以了解到用戶的訪問延遲或者哪個RegionServer的響應延遲比較大,可以方便排障,而且在讀寫的時候,如果產生了錯誤,我們也可以集成一些報警規則,比如連續失敗N次需要報警燈等。
我們平常工作中常用如下圖所示的看板,展示了所有的HBase集群伺服器的一些關鍵性指標,每個指標下面有個狀態燈,如果是綠色的,表示伺服器指標處於一個健康的狀態,用紅色表示需要馬上處理的狀態,黃色可能需要我們關注一下,我們會將紅色與黃色的呈現在最上端,以便更容易發現與及時處理。這些指示燈按鈕可以點擊來查看監測數據,例如打開Ping指示燈可以看最近一段時間Ping是否失敗與時長,Disk可以查看硬碟容量的使用情況,CPU點開可以展示最近CPU使用率的變化,SWAP展示有沒有使用SWAP以及使用率,QPS表示請求量,NetWork展示最近每塊網卡的流量使用情況,IO指IO延遲。

除此之外,我們還從幾個維度提供了幾個不同的看板,比如說下圖所示的第一個是「集群概覽」看板,展示了集群總的請求量,以及某些指標MaxTopN的RegionServer,比如說想知道有哪些RegionServer的請求量是最高的,可以通過MaxTopN指標展示哪些RegionServer比較高,還有它們的延遲或者各種隊列情況。總之,我們希望通過看板能比較容易地大概了解集群的整體情況。
第二是「伺服器」,這裡展示的是一個集群下面所有伺服器的指標,看板的主要作用是可以通過它能夠快速地知道這個集群中有哪個伺服器請求量特別大,或者它有什麼性能異常,能夠快速發現問題伺服器。

下圖一展示的是「表」看板,這裡展示的是這個表在集群所有RegionServer上的請求量,它的作用是讓我們快速發現表有沒有熱點或者熱點是在哪個RegionServer上。有時候我們需要從InfluxDB上根據自己需要自定義查詢,如下圖二所示「自定義查詢」,比如想查詢集群中請求量最大的表有哪些或者整個集群中最熱的Region是哪個,可以通過自定義查詢。以上這幾個功能基本可以完成日常運維的需要。

三、Client
客戶端方面,我們根據自己的需求作了一些調整工作,首先主要的改變就是接入攜程的整個框架中,比如說接入統一日誌收集平台、統一Bom文件、流量控制等。由於HBase對Guava依賴的是11版,而很多用戶使用的第三方產品可能依賴的是18版,那麼就會產生版本的衝突,我們可以通過Shade Guava來解決衝突問題。針對流量控制,我們做了一些規則,當伺服器比較繁忙的時候響應會超時,我們根據一定域值直接返回給當前用戶當前很忙,需要等待一段時間的資訊,主要目的是防止在伺服器負載很重的情況下,用戶又不斷請求,造成伺服器惡化。
我們也接入了攜程的配置中心,通過客戶端快速獲取集群的連接配置,主要作用是動態切換集群。比如客戶端想從A集群的訪問切換到B集群,只需要在QConfig中配置資訊改成B集群,那麼客戶端在新建連接的時候就能感知到配置資訊發生了變化,這時候就會關閉A集群上的Connection和Table,然後new Connection到B集群上,此時可能A集群原有的連接會有短暫的報錯。

此外我們在客戶端加了埋點資訊,用戶可以把這些訪問的一些統計資訊加到DashBoard上,比如說用戶請求量、每次請求的延遲情況、每次請求延遲大小。通過下圖這個產品我們可以方便地告訴用戶應用響應慢是因為用戶邏輯慢還是由於HBase響應慢。

四、遷移/升級
下面分享一下日常跨地區遷移或者版本遷移升級用的一些方法。目前同版本遷移可用的工具有很多,首先介紹一下離線遷移的概念。
離線遷移指的是為了遷移前後數據的一致性,在遷移前希望用戶能夠停止寫入,遷移完成後用戶可以把寫入直接集成到新的集群上,這種操作方式我們稱為離線遷移。第一種是直接在Hive上操作,把A集群的數據先加入到Hive,然後再寫入B集群,從而完成遷移;平時用的較多的是Export/Import,其優點是可以使用增量遷移,在遷移時可以指定時間戳;遷移較快的是直接Copy HFile,然後在新集群直接BulkLoad,因為它跳過了HBase層面的一些交互,速度非常快;偶爾我們也會用Copytable,因為與其他工具相比,它比較簡單。
在線遷移是指在不停止讀寫應用的前提下完成遷移,我們採用了兩種方法:第一種是通過Replication,首先在新舊集群之間複製表,將新數據同步到新集群中,再用Export/Import工具把舊的數據導入到新集群;第二種是直接在應用端修改,直接雙寫,將數據同時寫入新舊集群,在開始寫之後,再把舊集群的數據往新集群導一遍,導完之後切換應用。

還有升級問題,如果採用原地升級,可能需要停機,而且步驟比較繁瑣,可能需要先升級HDFS,然後升級HBase,等等,我們基本不採用這種方式。我們採用的升級基本是先搭建一個新的1.2的集群,然後在Hive上操作,把HBase0.94上的數據先讀到Hive,然後再寫入到1.2的集群,為了確保遷移前後數據的一致性,我們在遷移過程中要求用戶停止寫入。我們還可以通過修改Replication,通過模擬Replication來完成遷移。

如下圖所示,首先我們了解一下Replication的流程,當搭建好Replication以後,客戶端往Master集群寫入數據的時候,先寫入hlog,然後有一個Standby的RPL執行緒讀入日誌並解析數據,然後將數據寫入到Slave集群。

我們修改了往Slave集群寫入的步驟,如下圖所示,將解析出來的數據先加入到KAFKA,再用Jstrom消費寫入新的集群中。採用這種方式來完成遷移。

五、日常
接下來分享一下日常中的一些常見問題的處理和幾個案例。
1.如果在業務高峰期進行大表MajorCompaction,對性能影響比較大,會影響應用的訪問,那麼如何處理呢?
首先修改配置資訊,限制Compaction的頻寬,然後關閉自動的Compaction,然後通過腳本以Region為單位進行MajorCompaction,周期為N天,周期根據lastMajorCompactionTimestamp、TTL、writes判斷。
2.大表避免Split風暴問題
當表很大,Region非常多的時候,如果數據分布比較均勻,可能會同時觸發Split,在業務高峰期觸發Split,對性能損耗非常大。
最好的辦法是在進行表設計的時候進行預分區,評估一下數據量,做好分區方法。在很多時候,可能表已存在,那麼如何避免呢?我們通過獲取Client設置不當報錯以及其他熱點問題。舉例說明,在實際工作中遇到某個Client一直報錯RegionMovedException的問題。Region遷移了報錯,但為什麼平時沒有遇到這種問題呢?我們通過在業務低峰期提前Split的方式,避免業務高峰期自己Split。
3.大家關心的還有訪問的熱點問題,這個主要確保rowkey設計不存在熱點,當Region比較小時,實現自動化Split過熱的Region。
4.常見錯誤排障的分享。
比如某個Client一直報錯RegionMovedException?很多時候是因為Region 遷移了報錯。當發生錯誤後我們開始查找問題,如下圖所示,當hbase.client.retries.number<=1出現這種錯誤時直接throwable,沒有重試機會,或者當hbase.client.operation.timeout非常低時出現錯誤直接throwable,沒有重試機會。

5.一次IO問題
有時候應用突然響應變慢,後續自動恢復,過段時間可能還有緩慢,如下圖所示。
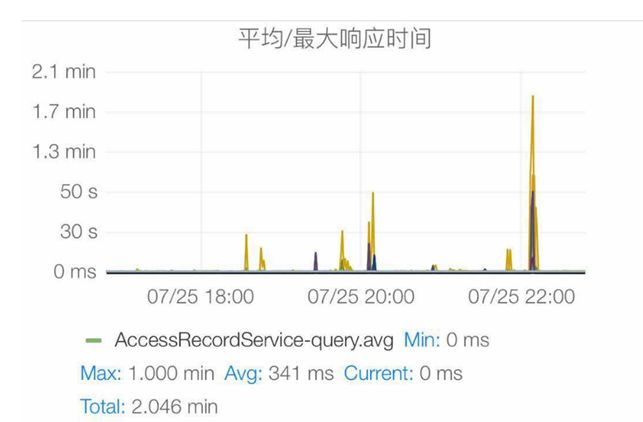
我們通過查看性能,發現有一個RegionServer在這個時間點CPU有沖高,然後我們也發現它的CPU_wio也有沖高,此時基本可以定位到IO問題導致的。我們通過HBase的錯誤日誌,發現訪問HDFS超時,然後查看datanode的日誌資訊也可以發現寫入耗時非常大,然後查看一些批處理的日誌消息,發現磁碟的一些異常資訊,發現磁碟的訪問延遲大。最後通過如下命令查看SMART資訊:sudo smartctl -A /dev/sdf ,第一天看到VALUE值為90多(低於100就有問題),正常值應該是100。第二天再次運行:直接報檢測失敗,值降低到15。至此可以確認是sdf磁碟壞掉了。
六、總結
前面報告主要介紹了HBase在攜程的一些應用。包括業務應用,監控告警,client封裝,遷移升級和遇到的一些問題。以後會調研下Hbase2.0一些新特性並在高可用方面做些嘗試。
作者介紹:
魏寧,攜程大數據高級工程師,主要負責 HBase、presto、kylin,熱衷於大數據開源技術;
顏志遠,攜程高級DBA,專註於HBase的開發運維,熱衷於mysql、redis、HBase等資料庫技術。
——END——


