跟我一起學Redis之高可用從主從複製開始
- 2020 年 12 月 21 日
- 筆記
- 跟我一起學Redis
前言
現在遇到高並發場景時,快取技術應該算是性能優化的第一步,緩解資料庫壓力的同時還能提高訪問效率,而Redis應該是絕大多數應用場景的首選。但是儘快Redis性能再優秀,在當今高並發場景下,一台伺服器負責讀寫,機器的性能和記憶體的瓶頸肯定避免不了,到這肯定有小夥伴會想到集群, 對的,思路沒錯,只是在集群之前,主從複製模式的優化策略能解決很多問題,如果主從模式還抗不住高並發,那再來集群也不晚;這裡先來說說Redis的主從複製。
為了更好的演示,搞了一台雲伺服器,Linux環境; 方便的同時,也能更符合實際應用場景;
正文
主從複製:主從指有多台Redis伺服器,其中一台為主伺服器,其他為從伺服器,可以通過命令或配置實現主從關係;複製指將主伺服器的數據同步到從伺服器,數據只能從主伺服器向從伺服器單向同步;其作用如下:
- 讀寫分離:主伺服器複製寫,各從伺服器負責讀;根據二八原則,80%的操作都是讀,只有20%進行寫,所以在一定程度上也解決了單機瓶頸問題;
- 數據持久化更加安全:主從多台伺服器進行持久化操作,任意一台服務宕機也不會影響數據恢復,避免了單點故障問題;
- 其他:主從複製是實現哨兵模式和Redis集群的前提,這個後續會說到。
好啦,老規矩,了解其作用之後,接下來就先實操再總結。
實現主從複製
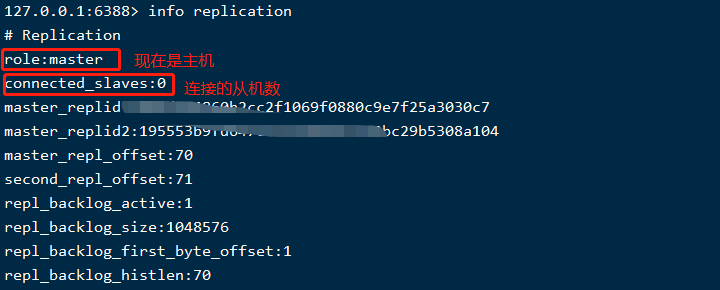
每一台Redis伺服器啟動時,默認都是主伺服器(Master),可以通過命令info replication查看,如下圖所示:
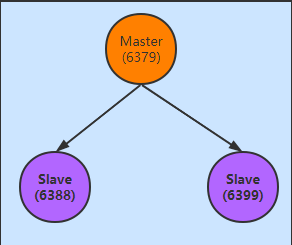
開始實操搭建一主二從的環境,如下:
1. 配置文件修改
由於是在同一台機器上模擬,所以將redis配置文件拷貝三份出來,主要修改項如下:
- 配置文件名稱:分別為redis.conf、redis6388.conf、redis6399.conf;
- port:埠,三個配置文件分別修改為6379、6388、6399,這是為了避免同一台機器演示埠衝突;
- pidfile:修改此文件名,避免文件衝突,改文件名即可,分別修改為redis.pid、redis6388.pid、redis6399.pid;
- dbfilename:持久化文件名,避免持久化文件衝突,分別修改為dump.rdb、dump6388.rdb、dump6399.rdb;
2. 啟動redis伺服器
然後分別指定配置文件啟動redis-server,在redis中bin目錄下執行./redis-server redis.conf、./redis-server redis6388.conf、./redis-server redis6399.conf命令即可,可以通過命令ps -ef | grep redis查看啟動redis效果,如下:

3.1 使用命令實現主從關係
默認情況下,啟動的三台伺服器默認都是主伺服器,現在可以通過簡單的命令實現一主二從的關係,這裡以6379這台伺服器為主,6388和6399兩台伺服器為從,配置主從關係只針對從節點伺服器配置即可,如下:
-
分別連上6388和6399兩台伺服器,執行
slaveof masterip masterport即可: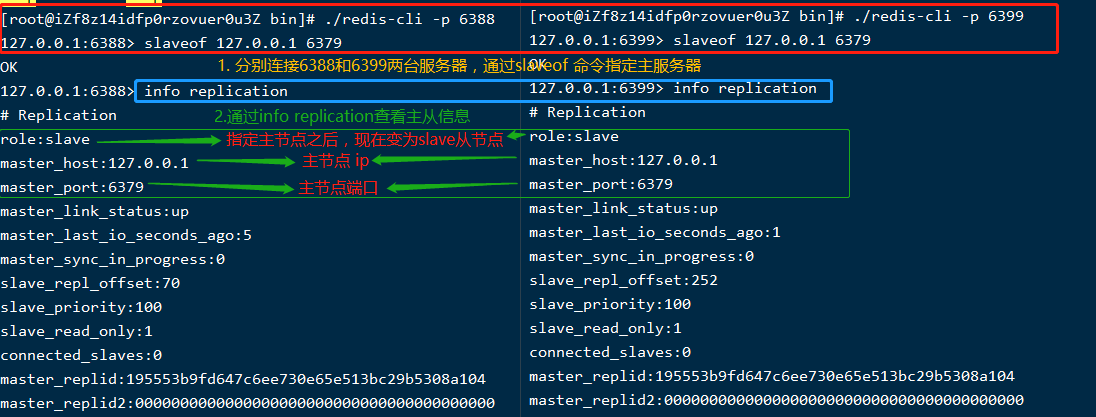
-
從節點顯示沒問題,看看主節點狀態資訊,連上6379這台看看,如下:
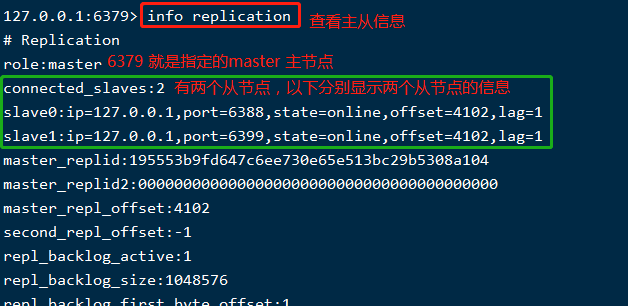
-
主從關係維護好了,接下來看看數據複製,通常主節點負責寫,將數據同步到從節點,從節點負責讀; 現在三台伺服器都沒數據,接下來往主節點中寫入點數據,看看是否能同步到從節點:
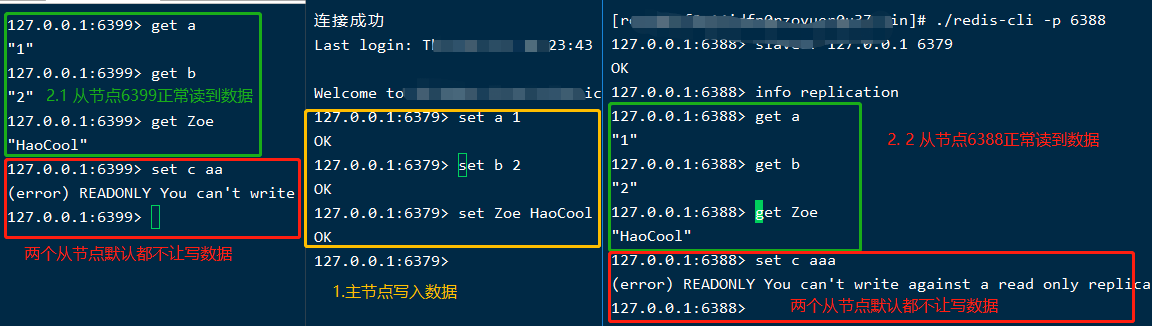



註:如果通過命令方式實現主從關係,那當從伺服器重啟時,主從關係就丟了,還得手動再執行命令,所以推薦配置文件的形式進行配置;
3.2 通過配置文件實現主從配置
還是很簡單的,主伺服器不用動,僅修改從伺服器配置文件,然後重啟即可,根據前面章節的學習經驗,打開配置文件,直接找到REPLICATION模組進行如下配置修改:
replicaof <masterip> <masterport>:指定主節點ip和埠即可,如:replicaof 127.0.0.1 6379;masterauth <master-password>:指定主節點密碼,如果主節點配置密碼,直接通過這配置就行;
修改完這兩項,重啟伺服器即可,和命令行一樣簡單,只是通過配置文件搭建的主從關係不會因為關閉伺服器而丟失;這裡配置文件的演示就不截圖了,只是實現方式不一樣,其他都是和命令行一致;
小總結
-
配從不配主,即只針對從伺服器配置即可,主伺服器無需配置;
-
一個主節點有多個從節點,從節點只能有一個主節點;從節點也可以作為其他從節點的主節點,如下:
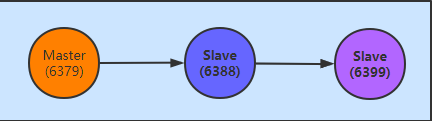
這種方式的演示截圖就不提供了,小夥伴實操一把,這裡說明一下,雖然6388是6399的主節點,但扮演的角色還是6379的從節點,只是它下面連接了其他從節點而已;
-
如果用命令方式實現主從,主伺服器斷開後,重新連接,主從關係還在;從伺服器斷開之後重連關係消失,需要手動執行命令重新指定主節點;
-
如果希望斷開重連主從關係還在,推薦配置文件方式實現;

實現主從複製的搭建是不是很簡單,不管是命令還是配置文件的方式,都很輕鬆實現;但小夥伴是不是也有疑問: 主從節點之間的數據是如何同步的?關於主從複製的其他參數有什麼用?
主從複製原理
通過上面實操,在主伺服器中寫入的數據,在無感知的情況下就同步到各個從伺服器,中間到底經歷了什麼呢? 接下來簡單的了解一下;
在Redis2.8之前同步方式都以全量方式同步,之後為了提高效率,數據複製方式分為兩種,一種為全量複製,一種為部分複製:
- 全量複製:即將主伺服器中的數據,全部同步到從伺服器;一般是在從伺服器啟動初始化數據的時候進行全量同步;
- 部分複製:即將未同步的增量數據,同步到從伺服器,無需全部再同步一遍;一般用於因網路中斷等無法同步數據的情況,待恢復正常之後,將中斷期間數據進行部分同步;
為了方便查看日誌分析,使用兩台redis伺服器進行搭建主從, 將之前搭建的關係去除,通過修改配置文件重啟即可;
這裡以6388作為主節點(Master),6399作為從節點(Slave),當連接6399執行命令slaveof 127.0.0.1 6388配置主從關係時,主從節點分別列印日誌如下:
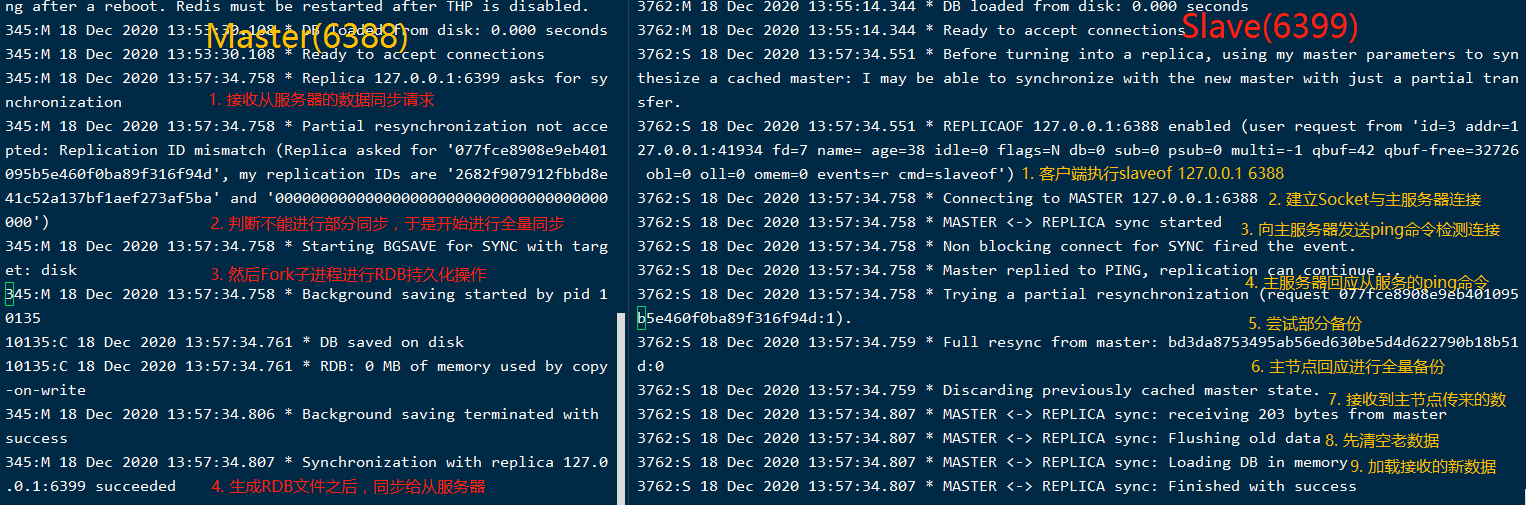
上圖是剛開始建立主從關係時,進行了全量複製,大概流程如下:
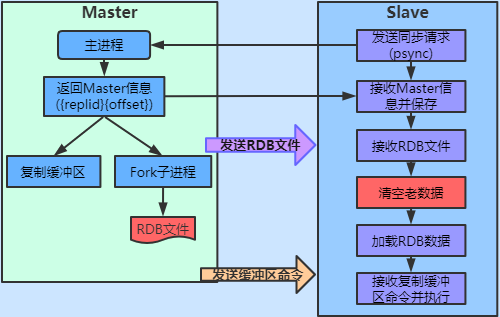
簡要說明:
- 從節點與主節點建立連接,然後發送同步請求psync;
- 主節點給從節點發送資訊,replid和offset,這兩個參數後續是判斷是否部分複製的關鍵數據;
- 主節點fork子進程將全部數據生成RDB文件;
- 主節點期間接收到的寫命令存入到複製緩衝區中;
- 當主節點RDB文件完成之後發送給從節點;
- 從節點接收到文件,先清空老數據;
- 從節點清空數據後,載入接收到的數據到記憶體中;
- 主節點發送複製緩衝區中的數據到從節點;
- 從節點接收到命令並執行,最終同步到最新數據;
主從關係是通過網路進行通訊,可能出現網路中斷或網路抖動情況,導致短時間的數據不能及時同步到從節點上,理想情況下,當連接恢復的時候,希望只同步中斷期間的數據,從而提高同步效率,流程大概如下:
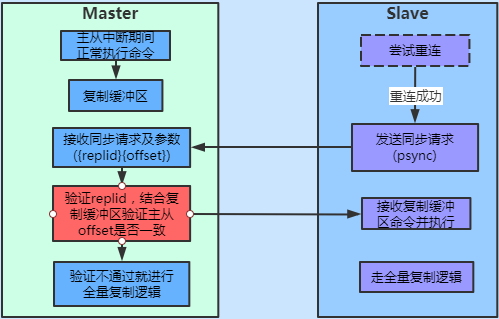
簡要說明:
- 當主從之間由於網路中斷時,從節點會嘗試重連主節點;
- 在此期間,主節點接收到的寫命令會記錄到複製緩衝區中;
- 當網路恢復,從節點連上主節點,會請求發布同步請求psync,並帶上之前主節點發送過來的replid和offset;
- 主節點接收到從節點的請求,會驗證接收的replid與主節點replid是否匹配,不匹配會進行全量複製;還會驗證offset數據偏移量是否在合法範圍內,如果中斷期間數據量過大,導致複製緩衝區的數據超出,主從節點的offset數據偏移量不一致,也會進行全複製;
- 當從節點傳遞過來的replid和offset驗證通過時,則進行部分複製,並記錄最新的offset;
這裡就不模擬演示部分複製流程了,留給小夥伴操作。演示流程如下:已經搭建主從關係的兩台機器,手動模擬網路斷開,斷開期間在主伺服器寫入數據,一會之後恢復網路,查看主從伺服器日誌列印情況;
主從複製的相關配置參數
以上演示在配置文件中只是配置了部分參數,還有其他參數的配置可以輕鬆實現功能,這裡結合主從複製的內容可以回顧一下相關配置參數的意義,如下:
- slaveof:設置本機為從機,指定主機的IP和埠;
- masterauth:如果主機需要密碼,通過這設置;
- slave-serve-stale-data:從機如果與主機斷開或數據正在同步,獲取數據是否繼續,如果設置為yes,還可以正常讀取數據,設置為no,獲取數據返回錯誤提示;
- slave-read-only:配置從主機為只讀模式,默認為yes,也強烈建議為只讀模式;
- repl-diskless-sync:是否採用無磁碟方式進行主從傳遞數據,即採用Socket方式,默認沒採用,如果機器磁碟性能不好,而網路環境良好,可以嘗試使用這種模式;
- repl-diskless-sync-delay:當使用無磁碟方式傳遞數據時,伺服器開始傳遞數據前等待指定時間,等待從伺服器進入傳輸隊列,提高數據傳輸效率,默認為5秒;
- repl-ping-slave-period:設置從機向主機發送ping消息間隔,即理解為心跳檢測;
- repl-timeout:設置超時時間,主從機傳遞數據的時間,如果超過指定時間,從機會重連。一般主從複製數據比較大時,可以將其改大,默認為60s ;
- repl-disable-tcp-nodelay:主從複製數據是否採用TCP_NODELAY,默認為no,代表不啟用,標識主機立即同步數據,保證數據一致性失效;如果設置為yes,合併較小的TCP包一併發送,延遲高,但可以提升頻寬性能,但推薦不啟用;
- repl-backlog-size:用於設置複製緩衝區的大小,此緩衝區用於從機斷開重連之後同步的增量數據,在一定時間內不用全量複製,提升同步效率;默認為1mb,可以根據需求進行修改;
- repl-backlog-ttl:設置從機斷開後沒有連接主機的間隔時間,超過此時間,設置的backlog緩衝區就會釋放,默認為3600s;
- slave-priority:用於哨兵模式選擇,即當主機掛掉時,選擇優先順序較高的從機代替掛掉的主機,快速恢復;默認值為100;
- min-slaves-to-write 3:指可用從伺服器少於3個時,主伺服器只能讀,不能寫,一般和min-slaves-max-lag搭配用,默認不使用,根據需要進行配置;
- min-slaves-max-lag 10:指從伺服器的延遲超過10秒時,主伺服器也只能讀,不能寫,一般和min-slaves-to-write搭配用,默認不使用,根據需要進行配置;
主從複製有哪些問題
主從複製緩解了單節點性能和存儲的瓶頸,那又帶來什麼問題呢?
- 主從複製架構會有延時,儘快很快,也有,特別數據量和並發大的時候;目前的主從架構沒有好的方法處理延時,MySql、SqlServer也是如此;
- 過期Key數據在早期版本不能及時將從伺服器數據失效,可以升級到redis3.2之後解決,因為加入了過期判斷;
- 主節點宕機之後,只能手動重新配置主從關係,從伺服器可以執行
slaveof no one命令重寫回到主伺服器角色,然後重新配置主從關係; - 如果從節點過多,當剛開始初始化數據全量同步或多個從節點斷開重連時,就會導致主節點的IO劇增;
總結
主從複製演練看似簡單,但還需要不斷在實踐中獲取經驗,搭配相關配置參數,從而使得更加適合應用場景;配置沒有固定都一樣,而是應用場景是否適合。隨著主節點宕機不能自動選舉的問題,下次在此基礎上說說哨兵模式,讓自動選舉不是問題;
一個被程式搞丑的帥小伙,關注”Code綜藝圈”,跟我一起學~~~



