跳錶(SkipList)原理篇
1、什麼是跳錶?
維基百科:跳錶是一種數據結構。它使得包含n個元素的有序序列的查找和插入操作的平均時間複雜度都是 O(logn),優於數組的 O(n)複雜度。快速的查詢效果是通過維護一個多層次的鏈表實現的,且與前一層(下面一層)鏈表元素的數量相比,每一層鏈表中的元素的數量更少。
- 優於數組的插入操作時間複雜度
簡單理解跳錶是基於鏈表實現的有序列表,跳錶通過維護一個多層級的鏈表實現了快速查詢效果將平均時間複雜度降到了O($log^n$),這是一個典型的異空間換時間數據結構。
2、為什麼需要跳錶?
在實際開發中經常遇到需要在數據集中查找一個指定數據的場景,而常用的支援高效查找演算法的實現方式有以下幾種:
-
有序數組。插入時可以先對數據排序,查詢時可以採用二分查找演算法降低查找操作的複雜度。缺點是插入和刪除數據時,為了保持元素的有序性,需要進行大量數據的移動操作。
-
二叉查找樹。既支援高效的二分查找演算法,又能快速的進行插入和刪除操作的數據結構,理想的時間複雜度為 O($log^n$),但是在某些極端情況下,二叉查找樹有可能變成一個線性鏈表,即退化成鏈表結構。
-
平衡二叉樹。基於二叉查找樹的優點,對其缺點進行了優化改進,引入了平衡的概念。為了維持二叉樹的平衡衍生出了多種平衡演算法,根據平衡演算法的不同具體實現有AVL樹 /B樹(B-Tree)/ B+樹(B+Tree)/紅黑樹 等等。但是平衡演算法的實現大多數比較複雜且較難理解。
針對大體量、海量數據集中查找指定數據有更好的解決方案,我們得評估時間、空間的成本和收益。
跳錶同樣支援對數據進行高效的查找,插入和刪除數據操作時間複雜度能與平衡二叉樹媲美,最重要的是跳錶的實現比平衡二叉樹簡單幾個級別。缺點就是「以空間換時間」方式存在一定數據冗餘。
如果存儲的數據是大對象,跳錶冗餘的只是指向數據的指針,幾乎可以不計使用的記憶體空間。
3、跳錶的實現原理
添加、刪除操作都需要先查詢出操作數據的位置,所以理解了跳錶的查詢原理後,剩下的只是對鏈表的操作。
3.1、查詢數據
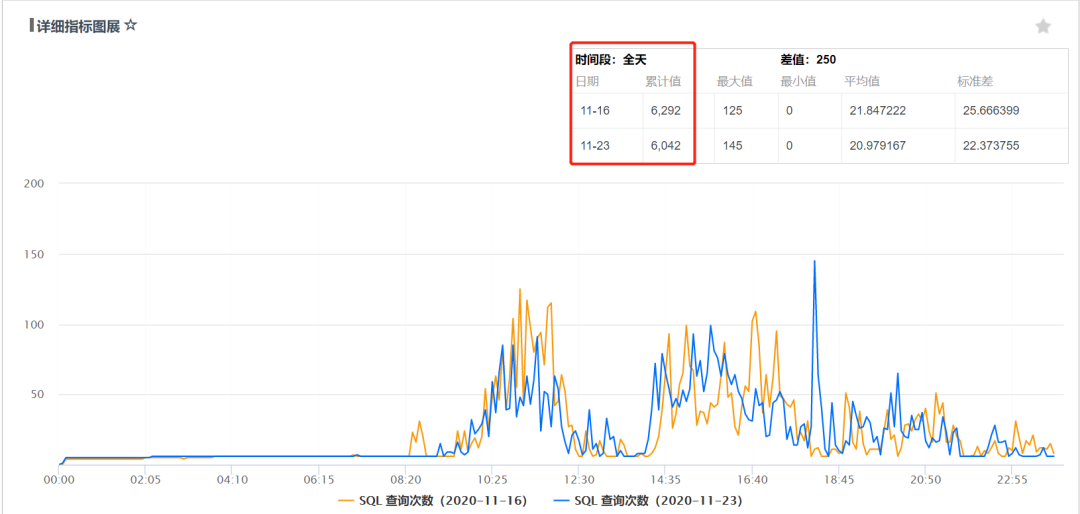
例設原始鏈表上的有序數據為【9,11,14,19,20,24,27】,如果我要查找的數據是20,只能從頭結點沿著鏈表依次比較查找,如圖所示:

鏈表不能像數組那樣通過索引快速訪問數據,只能沿著指針方向依次訪問,所以不能使用二分查找演算法快速進行數據查詢。但是可以借鑒創建索引的這種思路,就像圖書的目錄一樣,如果我要查看第六章的內容,直接翻到通過目錄查詢到的第六章對應頁碼處就行。
這裡的目錄就相當於創建的索引,該索引能夠縮小我們查詢數據的範圍減少查詢次數。在原始鏈表的基礎上,我們增加一層索引鏈表,假如原始鏈表的每兩個結點就有一個結點也在索引鏈表當中,如圖所示:
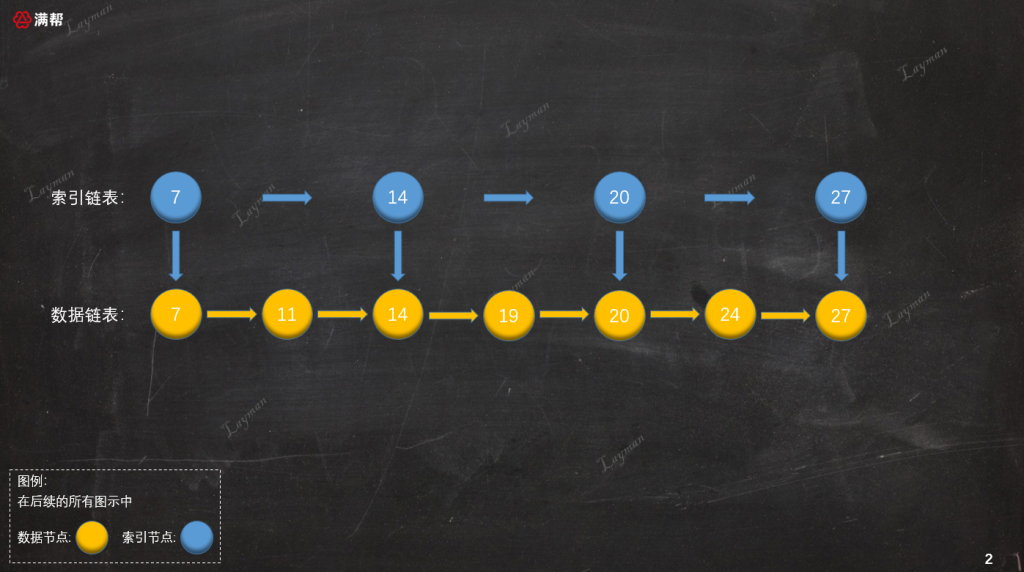
當建立了索引後檢索數據的方式就發生了變化,當我們想要定位到DataNode-20,我們不需要在原始鏈表中一個一個結點訪問,而是首先訪問索引鏈表:
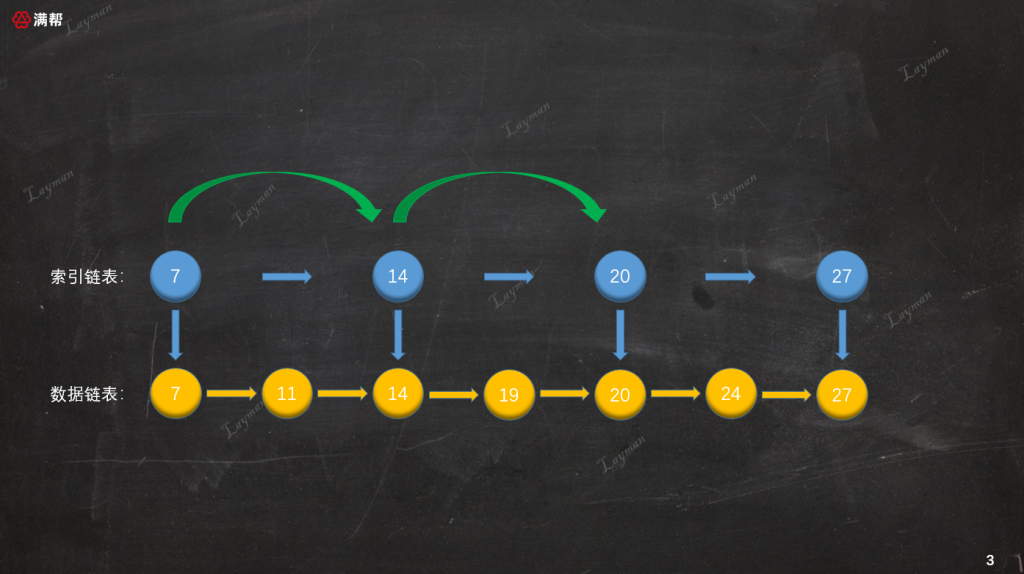
由於索引鏈表的結點個數是原始鏈表的一半,查找結點所需的訪問次數也就相應減少了一半,經過兩次查詢我們便找到DataNode-20。
正如圖書的目錄不止按照「章節」劃分,還可以按照「第幾部分」、「第幾小節」進行劃分,鏈表的索引也一樣。我們可以繼續為鏈表創建更多層索引,每層索引節點為前一層索引(對應圖例的下一層)的一半,在數據量比較大時能夠大大的提升我們的查詢效率。
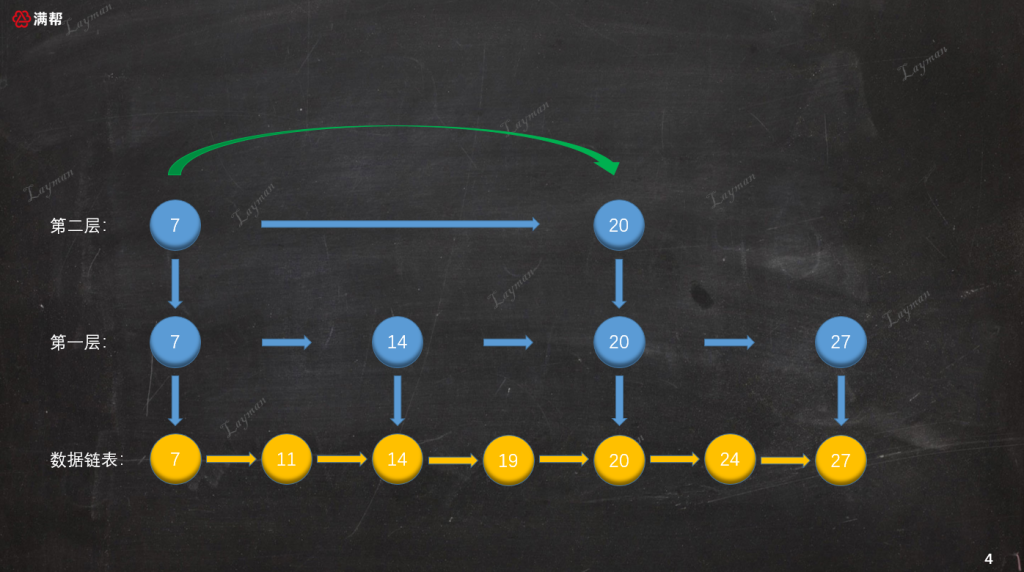
如圖所示,我們基於原始鏈表的第1層索引,抽出了第2層更為稀疏的索引,結點數量是第1層索引的一半。這樣的多層索引可以進一步提升查詢效率,那麼它是如何進行查詢的呢?假如這次要查找DataNode-27,讓我們來演示一下檢索過程:
- 首先,我們從最上層(第二層)的
HeadIndex-7開始查找,HeadIndex-7指向DataNode-7比DataNode-27小,所以繼續向右查詢找到第二個索引節點IndexNode-20。
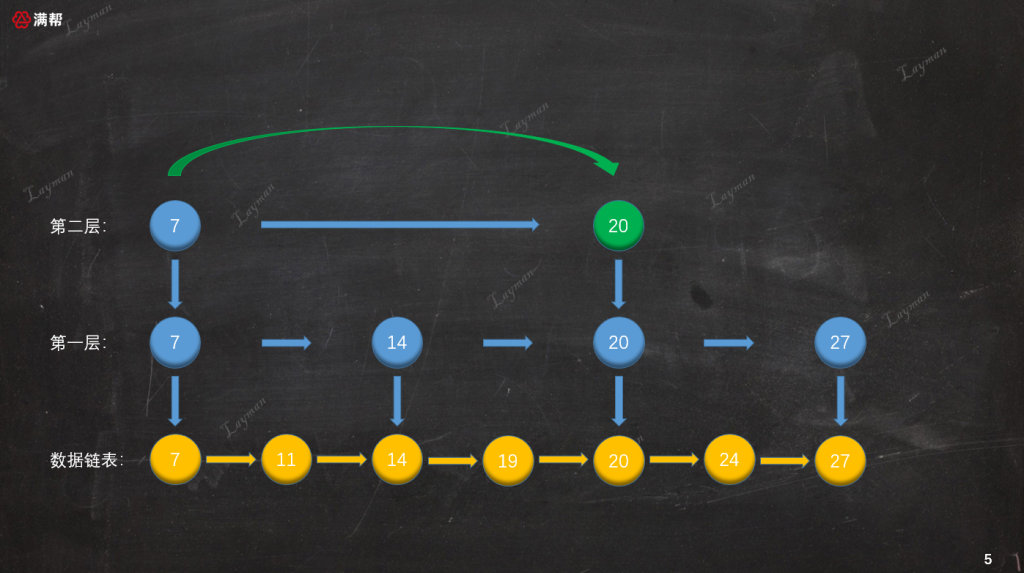
IndexNode-20指向DataNode-20也比DataNode-27小,但是此時第二層已經沒有後續的索引節點,所以我們需要順著IndexNode-20訪問下一層索引,即第一層的IndexNode-20。
從索引節點訪問方式可知,索引節點保存著「數據節點」、「下層索引節點」的指針。
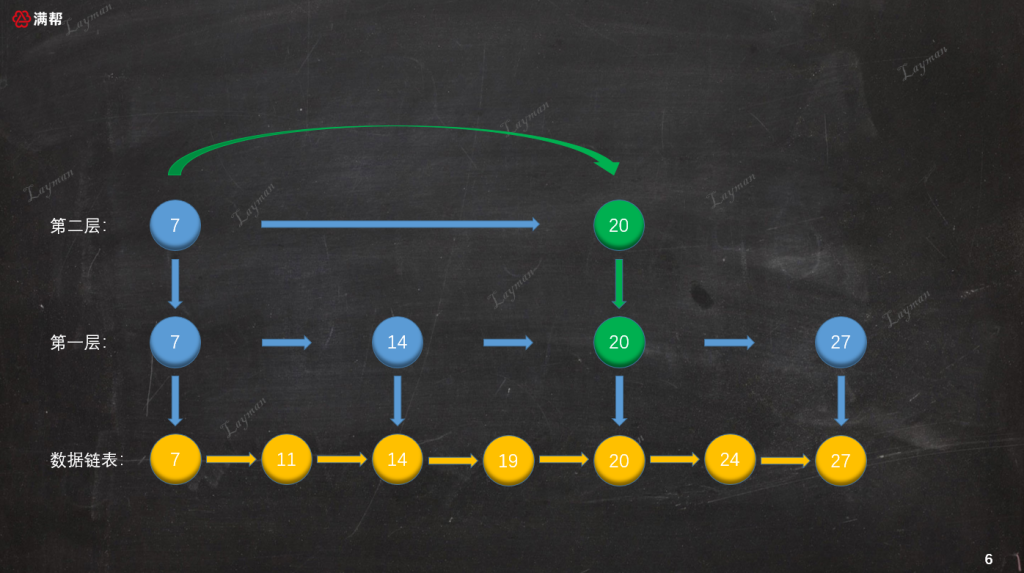
- 通過第一層的
IndexNode-20繼續向右檢索找到IndexNode-27便檢索到了DataNode-27。
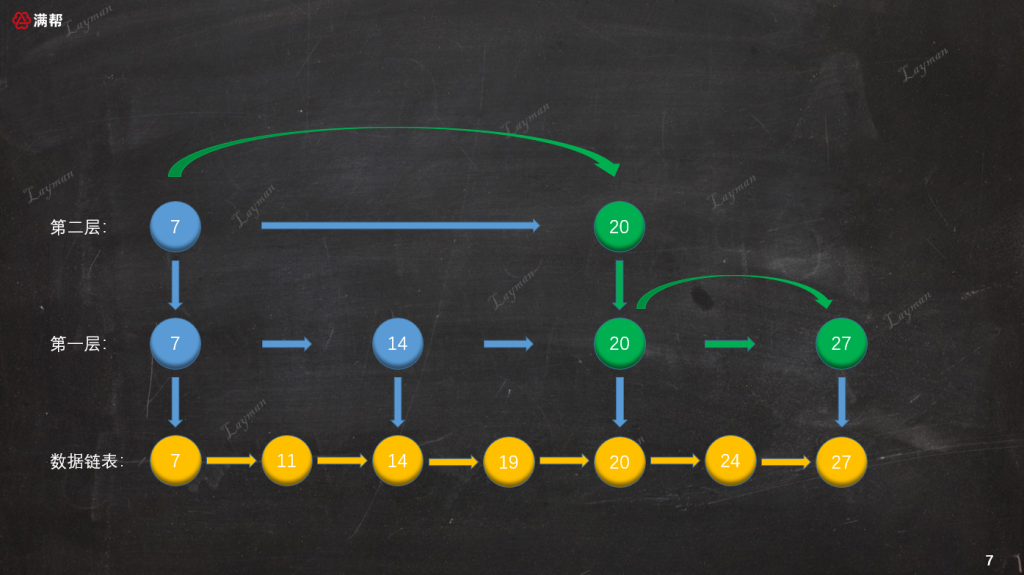
總結:
維基百科:
跳躍列表是按層建造的。底層是一個普通的有序鏈表。每個更高層都充當下面列表的「快速通道」,這裡在第 i 層中的元素按某個固定的概率 $p$(通常為 $\frac 12$ 或 $\frac 14$ 出現在第 i + 1 層中。每個元素平均出現在 ${1\over 1-p}$ 個列表中,而最高層的元素(通常是在跳躍列表前端的一個特殊的頭元素)在 $log_{1/p}^n$個列表中出現。在查找目標元素時,從頂層列表、頭元素起步。演算法沿著每層鏈表搜索,直至找到一個大於或等於目標的元素,或者到達當前層列表末尾。如果該元素等於目標元素,則表明該元素已被找到;如果該元素大於目標元素或已到達鏈表末尾,則退回到當前層的上一個元素,然後轉入下一層進行搜索。每層鏈表中預期的查找步數最多為$\frac 1p$,而層數為 -${log_p^n}\over{p}$,由於 $p$ 是常數,查找操作總體的時間複雜度為 O($log^n$)。而通過選擇不同 $p$ 值,就可以在查找代價和存儲代價之間獲取平衡。
上面的查詢例子中索引節點已經是創建好的,那麼原始鏈表哪些數據節點需要創建索引節點、什麼時候創建?這些問題的答案都要回歸到往原始鏈表添加數據時。
3.2、插入數據
從上面的總結不難理解在向原始鏈表中插入數據時,當前插入的數據按照某個固定的概率$p$($\frac 12$ 或 $\frac 14$)在每層索引鏈表中創建索引節點。假設現在插入DataNode-18,我們來看看是如何插入和創建索引節點的:
3.2.1、找到插入數據的前置節點
首先我們按照跳錶查找結點的方法,找到待插入結點的前置結點(僅小於待插入結點):
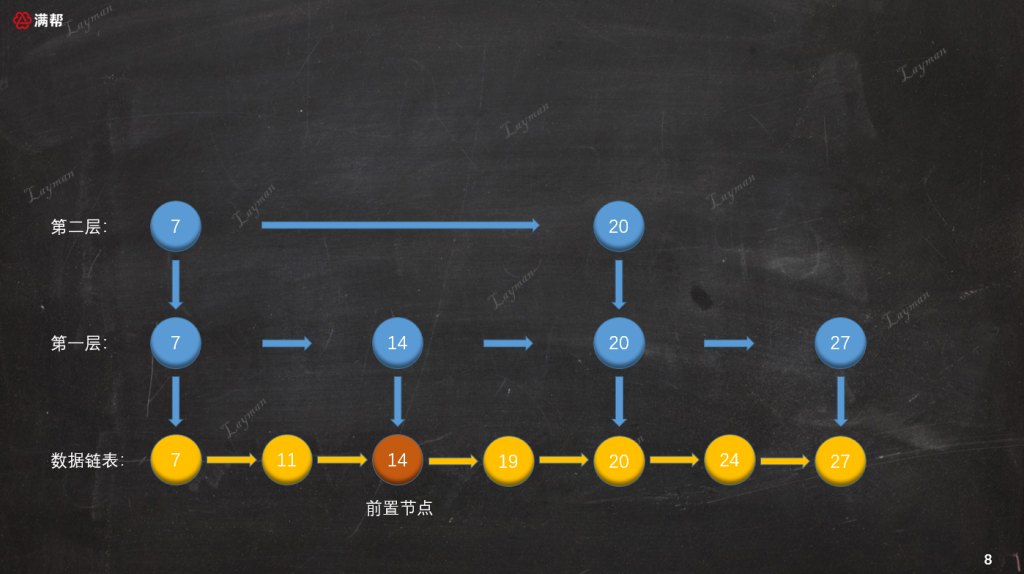
3.2.2、插入原始鏈表
接下來按照一般鏈表的插入方式,把DataNode-18插入到結點DataNode-14的後續位置:
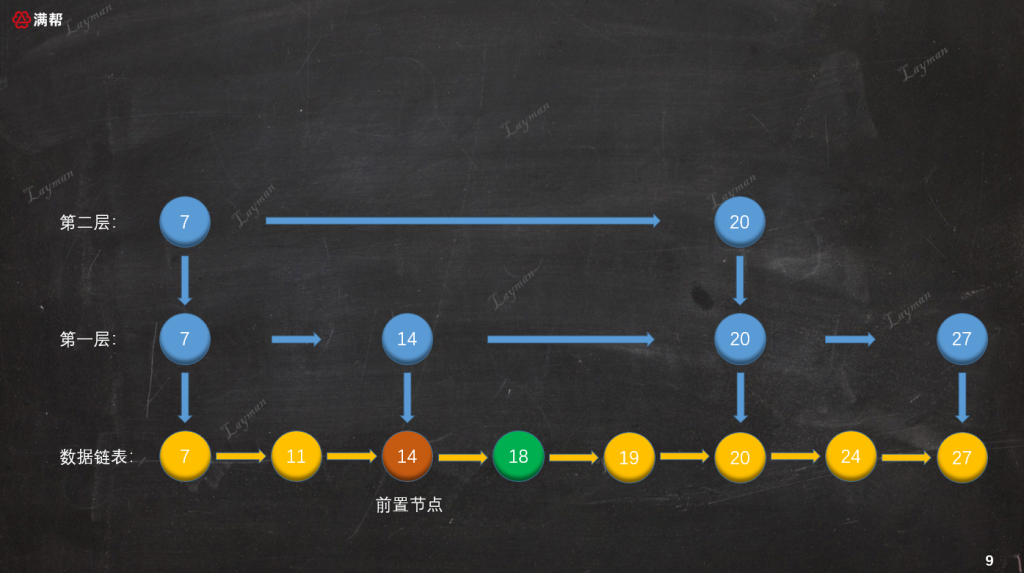
這樣數據就插入到了原始鏈表中,但是我們的插入操作並沒有結束。按照定義我們需要讓新插入的結點隨機(拋硬幣的方式)「晉陞」,也就是為DataNode-18創建索引節點,正是採取這種簡單的隨機方式,跳錶也被稱為一種隨機化的數據結構。
3.2.3、創建索引節點
假設第一、第二次隨機的結果都是晉陞成功,那麼我們需要為DataNode-18創建索引節點,插入到第一層和第二層索引的對應位置,並且向下指向原始鏈表的DataNode-18。
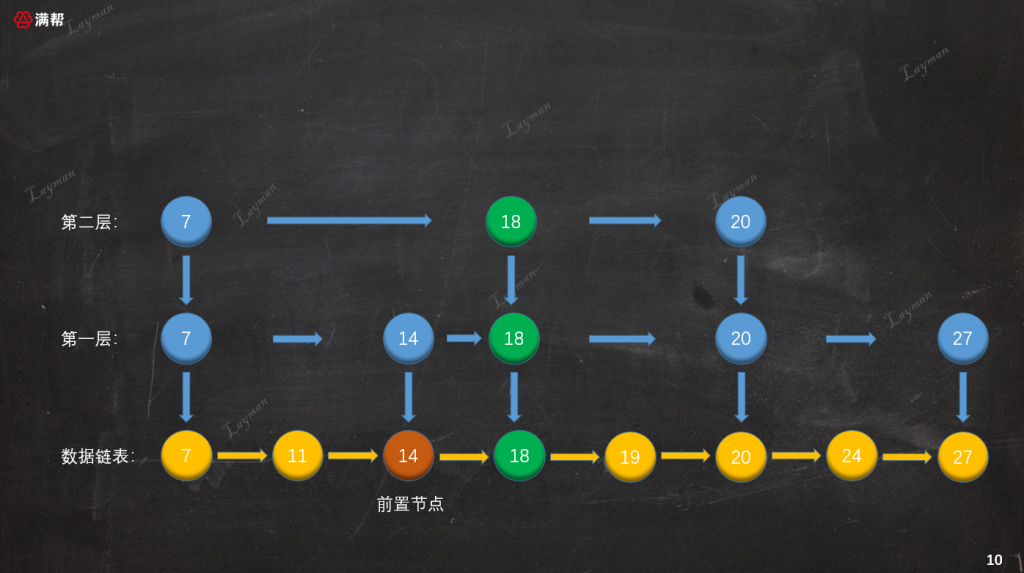
在索引鏈表中插入新創建的索引節點時需要注意幾點:
- 找到待插入索引節點的前置索引節點指向新索引節點,新索引節點指向前置節點之前指向的索引節點。(也就是鏈表的插入操作)
- 隨機的結果是「晉陞成功」就可以繼續向上一層創建索引,直到假設隨機的結果是「晉陞失敗」或者「新增索引層」。
- 每層是否創建索引節點可以一次性拋幾次硬幣,而不是添加一層索引後再進行投幣。(這樣做的目的是為了更好的用程式碼實現)。
新建的索引節點何如銜接到前置索引節點以及如何用程式碼實現,這個我們在下篇文章「SkipList 程式碼實現」去解析。
3.2.4、添加索引層
如果在第二層(目前索引最大層級)創建索引節點後,下一次隨機的結果仍然是晉陞成功,這時候該怎麼辦呢?這個時候我們就需要添加一層索引層:
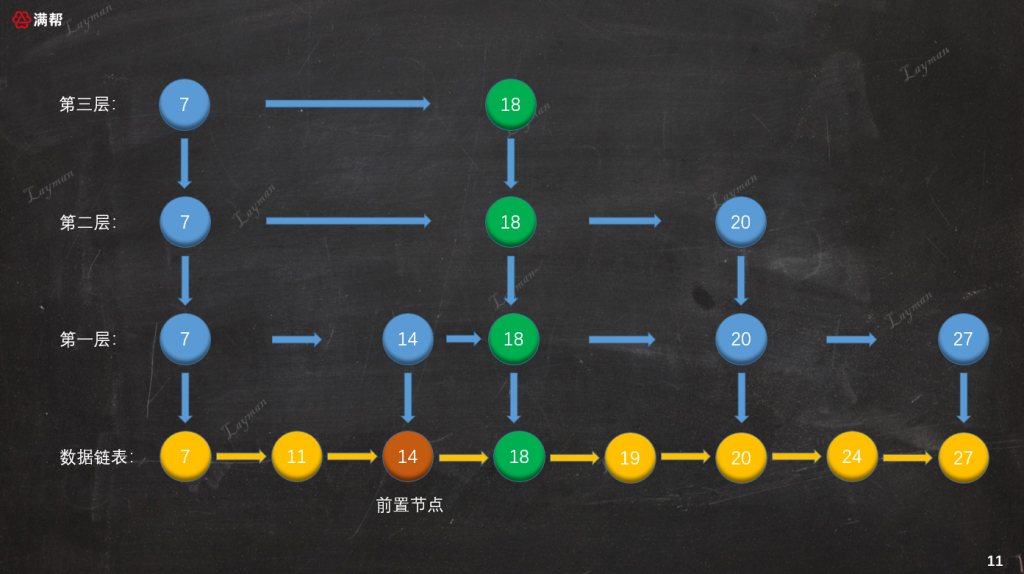
可以看到此時第三層只有HeadIndex-7和IndexNode-18,此時不會繼續向上層創建索引,因為就算繼續創建仍只有HeadIndex-7和IndexNode-18,這顯得毫無意義。至此跳錶的插入操作包括索引的創建過程已經解析完,跳錶的刪除過程正好和插入是相反的思路。
3.3、刪除數據
3.3.1、查找待刪除節點
假設我們要刪除剛才插入的DataNode-18,首先我們要按照跳錶查找結點的方法找到待刪除的DataNode-18,當然如果沒有找到對應的數據直接返回進行。
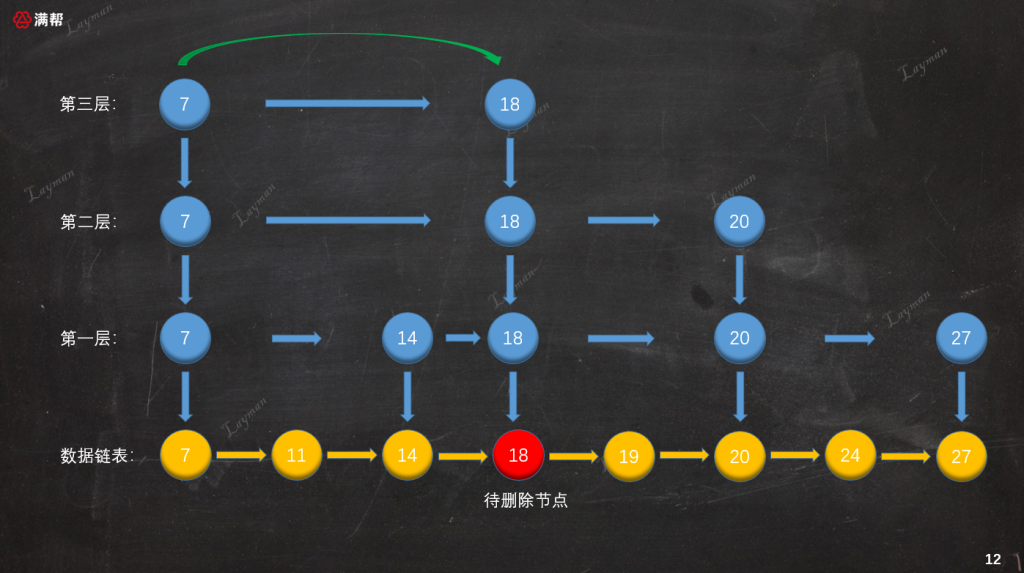
3.3.2、刪除原始鏈表節點
接下來按照鏈表的刪除方式,把DataNode-18從原始鏈表當中刪除
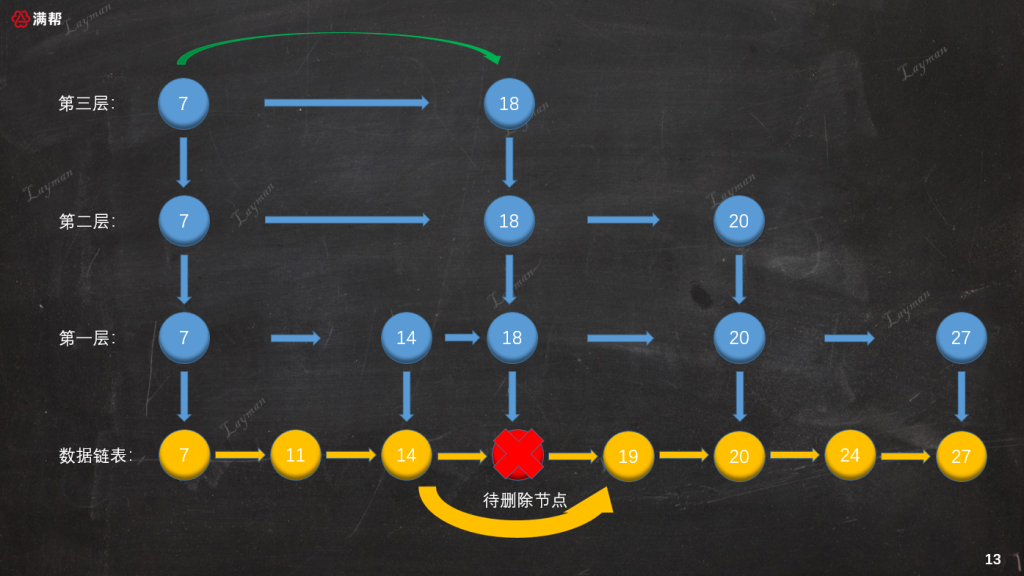
3.3.3、刪除索引節點
同插入數據一樣,刪除工作並沒有就此完成,我們需要將DataNode-18在索引層對應的IndexNode-18也一 一刪除:
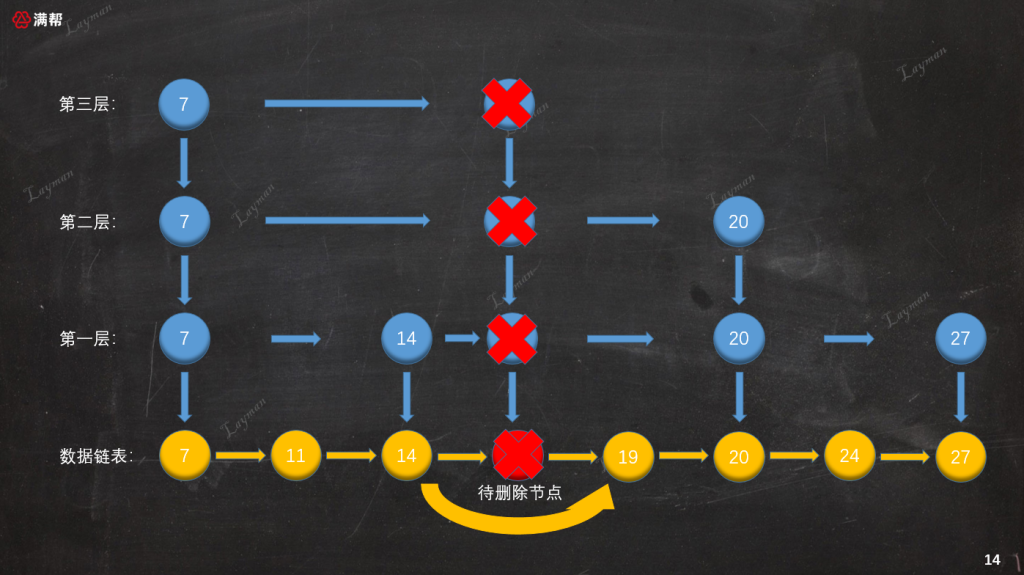
3.3.4、刪除索引層
同插入索引節點一樣,刪除索引節點時也需要維護前置節點的指向關係。這裡需要特別注意最上層索引(第三層),當刪除IndexNode-18後該層只剩下HeadIndex-7,這個時候需要將該索引層也一同刪除。
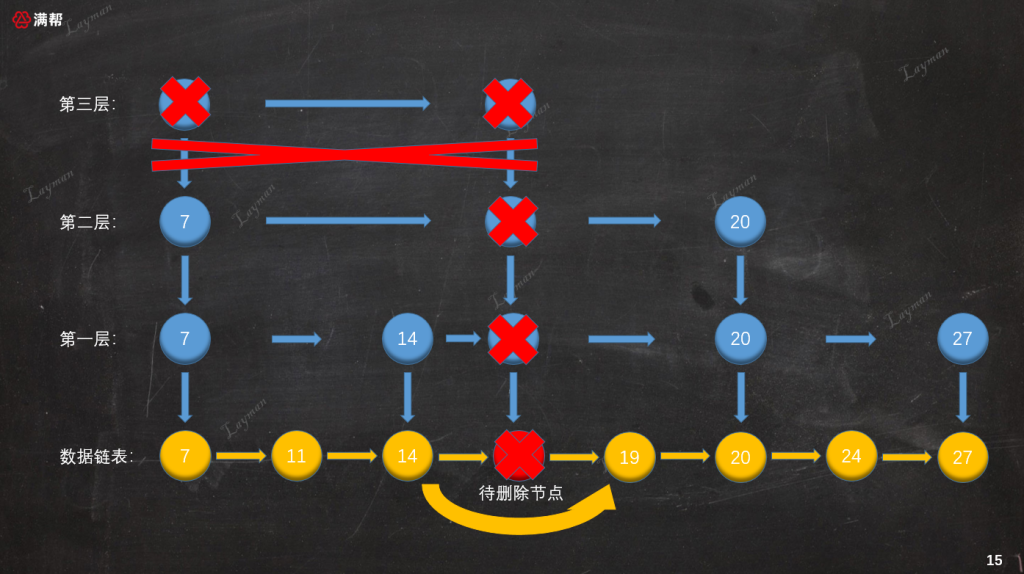
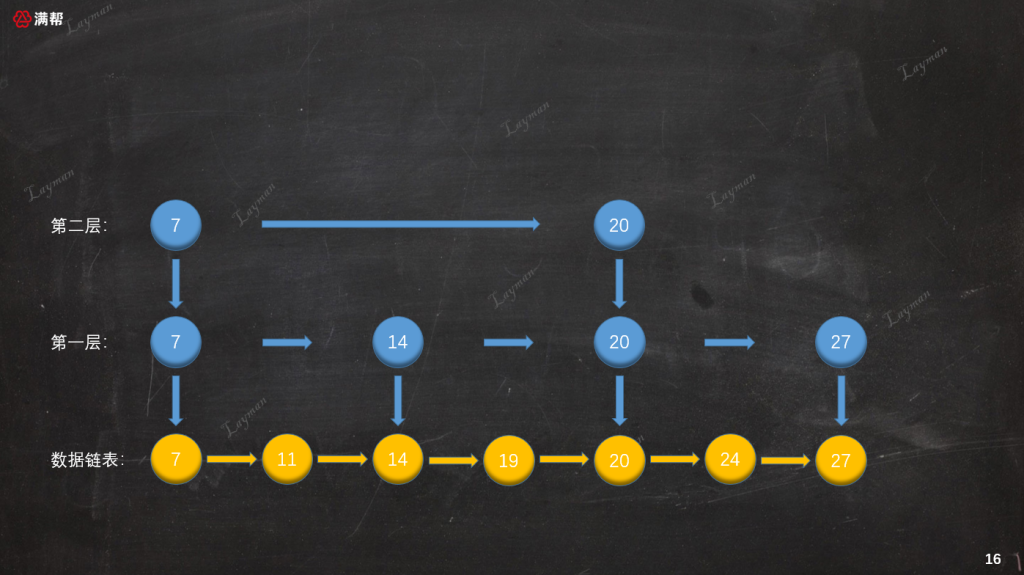
至此整個刪除操作就算完成了,此時跳錶的結構就和我們之前插入之前保持一致了:
總結
- 簡單對比了跳錶和其他幾種高效查找演算法的優缺點。
- 跳錶是基於鏈表實現的,是一種「以空間換時間」的「隨機化」數據結構。
- 跳錶引入了索引層的概念,有了它才有了時間複雜度為O($logn$)的查詢效率,從而實現了增刪操作的時間複雜度也是O($logn$)。
- 跳錶擁有平衡二叉樹相同的查詢效率,但是跳錶對於樹平衡的實現是基於一種隨機化的演算法的,相對於AVL樹/B樹(B-Tree)/B+樹(B+Tree)/紅黑樹的實現簡單得多。
跳錶的檢索、插入、刪除的原理篇就解析到這裡,下篇將分析SkipList數據結構的程式碼實現,to be expected !!!
可恥的貼個個人Git地址:SkipList原理篇