HBase 系列(八)——HBase 協處理器
- 2019 年 10 月 3 日
- 筆記
一、簡述
在使用 HBase 時,如果你的數據量達到了數十億行或數百萬列,此時能否在查詢中返回大量數據將受制於網路的頻寬,即便網路狀況允許,但是客戶端的計算處理也未必能夠滿足要求。在這種情況下,協處理器(Coprocessors)應運而生。它允許你將業務計算程式碼放入在 RegionServer 的協處理器中,將處理好的數據再返回給客戶端,這可以極大地降低需要傳輸的數據量,從而獲得性能上的提升。同時協處理器也允許用戶擴展實現 HBase 目前所不具備的功能,如許可權校驗、二級索引、完整性約束等。
二、協處理器類型
2.1 Observer協處理器
1. 功能
Observer 協處理器類似於關係型資料庫中的觸發器,當發生某些事件的時候這類協處理器會被 Server 端調用。通常可以用來實現下面功能:
- 許可權校驗:在執行
Get或Put操作之前,您可以使用preGet或prePut方法檢查許可權; - 完整性約束: HBase 不支援關係型資料庫中的外鍵功能,可以通過觸發器在插入或者刪除數據的時候,對關聯的數據進行檢查;
- 二級索引: 可以使用協處理器來維護二級索引。
2. 類型
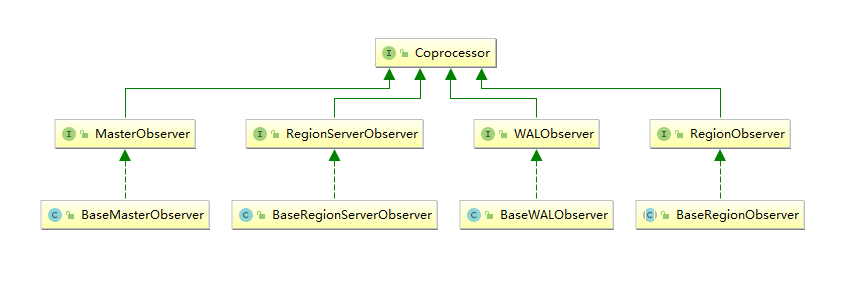
當前 Observer 協處理器有以下四種類型:
- RegionObserver :
允許您觀察 Region 上的事件,例如 Get 和 Put 操作。 - RegionServerObserver :
允許您觀察與 RegionServer 操作相關的事件,例如啟動,停止或執行合併,提交或回滾。 - MasterObserver :
允許您觀察與 HBase Master 相關的事件,例如表創建,刪除或 schema 修改。 - WalObserver :
允許您觀察與預寫日誌(WAL)相關的事件。
3. 介面
以上四種類型的 Observer 協處理器均繼承自 Coprocessor 介面,這四個介面中分別定義了所有可用的鉤子方法,以便在對應方法前後執行特定的操作。通常情況下,我們並不會直接實現上面介面,而是繼承其 Base 實現類,Base 實現類只是簡單空實現了介面中的方法,這樣我們在實現自定義的協處理器時,就不必實現所有方法,只需要重寫必要方法即可。
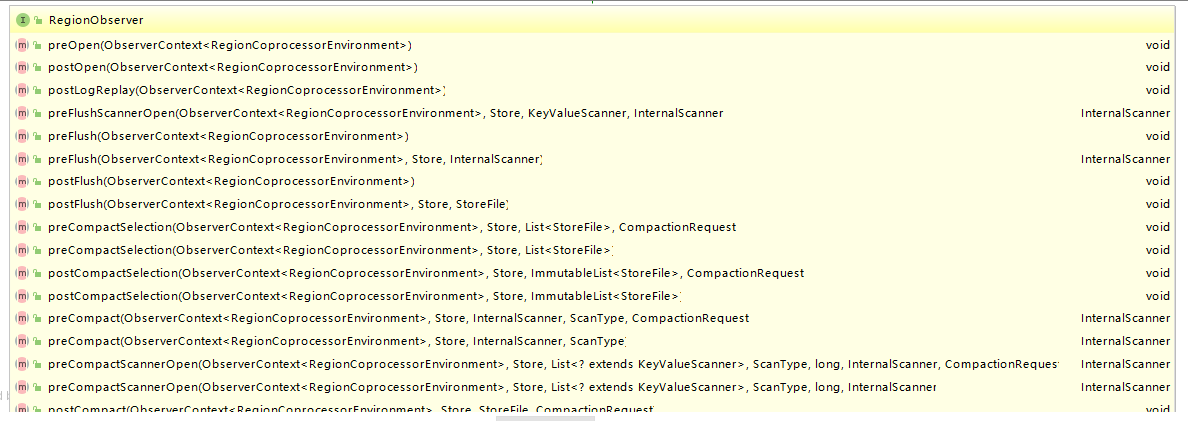
這裡以 RegionObservers 為例,其介面類中定義了所有可用的鉤子方法,下面截取了部分方法的定義,多數方法都是成對出現的,有 pre 就有 post:
4. 執行流程
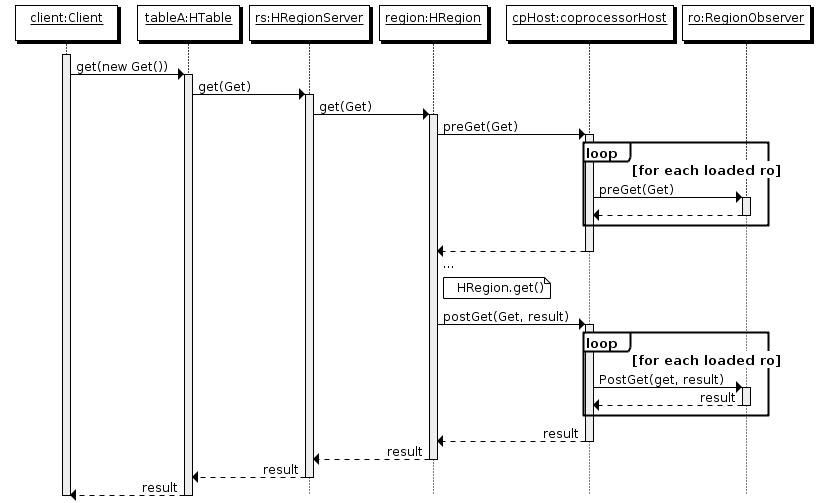
- 客戶端發出 put 請求
- 該請求被分派給合適的 RegionServer 和 region
- coprocessorHost 攔截該請求,然後在該表的每個 RegionObserver 上調用 prePut()
- 如果沒有被
prePut()攔截,該請求繼續送到 region,然後進行處理 - region 產生的結果再次被 CoprocessorHost 攔截,調用
postPut() - 假如沒有
postPut()攔截該響應,最終結果被返回給客戶端
如果大家了解 Spring,可以將這種執行方式類比於其 AOP 的執行原理即可,官方文檔當中也是這樣類比的:
If you are familiar with Aspect Oriented Programming (AOP), you can think of a coprocessor as applying advice by intercepting a request and then running some custom code,before passing the request on to its final destination (or even changing the destination).
如果您熟悉面向切面編程(AOP),您可以將協處理器視為通過攔截請求然後運行一些自定義程式碼來使用 Advice,然後將請求傳遞到其最終目標(或者更改目標)。
2.2 Endpoint協處理器
Endpoint 協處理器類似於關係型資料庫中的存儲過程。客戶端可以調用 Endpoint 協處理器在服務端對數據進行處理,然後再返回。
以聚集操作為例,如果沒有協處理器,當用戶需要找出一張表中的最大數據,即 max 聚合操作,就必須進行全表掃描,然後在客戶端上遍歷掃描結果,這必然會加重了客戶端處理數據的壓力。利用 Coprocessor,用戶可以將求最大值的程式碼部署到 HBase Server 端,HBase 將利用底層 cluster 的多個節點並發執行求最大值的操作。即在每個 Region 範圍內執行求最大值的程式碼,將每個 Region 的最大值在 Region Server 端計算出來,僅僅將該 max 值返回給客戶端。之後客戶端只需要將每個 Region 的最大值進行比較而找到其中最大的值即可。
三、協處理的載入方式
要使用我們自己開發的協處理器,必須通過靜態(使用 HBase 配置)或動態(使用 HBase Shell 或 Java API)載入它。
- 靜態載入的協處理器稱之為 System Coprocessor(系統級協處理器),作用範圍是整個 HBase 上的所有表,需要重啟 HBase 服務;
- 動態載入的協處理器稱之為 Table Coprocessor(表處理器),作用於指定的表,不需要重啟 HBase 服務。
其載入和卸載方式分別介紹如下。
四、靜態載入與卸載
4.1 靜態載入
靜態載入分以下三步:
- 在
hbase-site.xml定義需要載入的協處理器。
<property> <name>hbase.coprocessor.region.classes</name> <value>org.myname.hbase.coprocessor.endpoint.SumEndPoint</value> </property><name> 標籤的值必須是下面其中之一:
- RegionObservers 和 Endpoints 協處理器:
hbase.coprocessor.region.classes - WALObservers 協處理器:
hbase.coprocessor.wal.classes - MasterObservers 協處理器:
hbase.coprocessor.master.classes
<value> 必須是協處理器實現類的全限定類名。如果為載入指定了多個類,則類名必須以逗號分隔。
-
將 jar(包含程式碼和所有依賴項) 放入 HBase 安裝目錄中的
lib目錄下; -
重啟 HBase。
4.2 靜態卸載
-
從 hbase-site.xml 中刪除配置的協處理器的<property>元素及其子元素;
-
從類路徑或 HBase 的 lib 目錄中刪除協處理器的 JAR 文件(可選);
-
重啟 HBase。
五、動態載入與卸載
使用動態載入協處理器,不需要重新啟動 HBase。但動態載入的協處理器是基於每個表載入的,只能用於所指定的表。
此外,在使用動態載入必須使表離線(disable)以載入協處理器。動態載入通常有兩種方式:Shell 和 Java API 。
以下示例基於兩個前提:
- coprocessor.jar 包含協處理器實現及其所有依賴項。
- JAR 包存放在 HDFS 上的路徑為:hdfs:// <namenode>:<port> / user / <hadoop-user> /coprocessor.jar
5.1 HBase Shell動態載入
- 使用 HBase Shell 禁用表
hbase > disable 'tableName'- 使用如下命令載入協處理器
hbase > alter 'tableName', METHOD => 'table_att', 'Coprocessor'=>'hdfs://<namenode>:<port>/ user/<hadoop-user>/coprocessor.jar| org.myname.hbase.Coprocessor.RegionObserverExample|1073741823| arg1=1,arg2=2'Coprocessor 包含由管道(|)字元分隔的四個參數,按順序解釋如下:
- JAR 包路徑:通常為 JAR 包在 HDFS 上的路徑。關於路徑以下兩點需要注意:
-
允許使用通配符,例如:
hdfs://<namenode>:<port>/user/<hadoop-user>/*.jar來添加指定的 JAR 包; -
可以使指定目錄,例如:
hdfs://<namenode>:<port>/user/<hadoop-user>/,這會添加目錄中的所有 JAR 包,但不會搜索子目錄中的 JAR 包。 - 類名:協處理器的完整類名。
- 優先順序:協處理器的優先順序,遵循數字的自然序,即值越小優先順序越高。可以為空,在這種情況下,將分配默認優先順序值。
-
可選參數 :傳遞的協處理器的可選參數。
- 啟用表
hbase > enable 'tableName'- 驗證協處理器是否已載入
hbase > describe 'tableName'協處理器出現在 TABLE_ATTRIBUTES 屬性中則代表載入成功。
5.2 HBase Shell動態卸載
- 禁用表
hbase> disable 'tableName'- 移除表協處理器
hbase> alter 'tableName', METHOD => 'table_att_unset', NAME => 'coprocessor$1'- 啟用表
hbase> enable 'tableName'5.3 Java API 動態載入
TableName tableName = TableName.valueOf("users"); String path = "hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar"; Configuration conf = HBaseConfiguration.create(); Connection connection = ConnectionFactory.createConnection(conf); Admin admin = connection.getAdmin(); admin.disableTable(tableName); HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName); HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet"); columnFamily1.setMaxVersions(3); hTableDescriptor.addFamily(columnFamily1); HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet"); columnFamily2.setMaxVersions(3); hTableDescriptor.addFamily(columnFamily2); hTableDescriptor.setValue("COPROCESSOR$1", path + "|" + RegionObserverExample.class.getCanonicalName() + "|" + Coprocessor.PRIORITY_USER); admin.modifyTable(tableName, hTableDescriptor); admin.enableTable(tableName);在 HBase 0.96 及其以後版本中,HTableDescriptor 的 addCoprocessor() 方法提供了一種更為簡便的載入方法。
TableName tableName = TableName.valueOf("users"); Path path = new Path("hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar"); Configuration conf = HBaseConfiguration.create(); Connection connection = ConnectionFactory.createConnection(conf); Admin admin = connection.getAdmin(); admin.disableTable(tableName); HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName); HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet"); columnFamily1.setMaxVersions(3); hTableDescriptor.addFamily(columnFamily1); HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet"); columnFamily2.setMaxVersions(3); hTableDescriptor.addFamily(columnFamily2); hTableDescriptor.addCoprocessor(RegionObserverExample.class.getCanonicalName(), path, Coprocessor.PRIORITY_USER, null); admin.modifyTable(tableName, hTableDescriptor); admin.enableTable(tableName);5.4 Java API 動態卸載
卸載其實就是重新定義表但不設置協處理器。這會刪除所有表上的協處理器。
TableName tableName = TableName.valueOf("users"); String path = "hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar"; Configuration conf = HBaseConfiguration.create(); Connection connection = ConnectionFactory.createConnection(conf); Admin admin = connection.getAdmin(); admin.disableTable(tableName); HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName); HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet"); columnFamily1.setMaxVersions(3); hTableDescriptor.addFamily(columnFamily1); HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet"); columnFamily2.setMaxVersions(3); hTableDescriptor.addFamily(columnFamily2); admin.modifyTable(tableName, hTableDescriptor); admin.enableTable(tableName);六、協處理器案例
這裡給出一個簡單的案例,實現一個類似於 Redis 中 append 命令的協處理器,當我們對已有列執行 put 操作時候,HBase 默認執行的是 update 操作,這裡我們修改為執行 append 操作。
# redis append 命令示例 redis> EXISTS mykey (integer) 0 redis> APPEND mykey "Hello" (integer) 5 redis> APPEND mykey " World" (integer) 11 redis> GET mykey "Hello World"6.1 創建測試表
# 創建一張雜誌表 有文章和圖片兩個列族 hbase > create 'magazine','article','picture'6.2 協處理器編程
完整程式碼可見本倉庫:hbase-observer-coprocessor
新建 Maven 工程,導入下面依賴:
<dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-common</artifactId> <version>1.2.0</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>1.2.0</version> </dependency>繼承 BaseRegionObserver 實現我們自定義的 RegionObserver,對相同的 article:content 執行 put 命令時,將新插入的內容添加到原有內容的末尾,程式碼如下:
public class AppendRegionObserver extends BaseRegionObserver { private byte[] columnFamily = Bytes.toBytes("article"); private byte[] qualifier = Bytes.toBytes("content"); @Override public void prePut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException { if (put.has(columnFamily, qualifier)) { // 遍歷查詢結果,獲取指定列的原值 Result rs = e.getEnvironment().getRegion().get(new Get(put.getRow())); String oldValue = ""; for (Cell cell : rs.rawCells()) if (CellUtil.matchingColumn(cell, columnFamily, qualifier)) { oldValue = Bytes.toString(CellUtil.cloneValue(cell)); } // 獲取指定列新插入的值 List<Cell> cells = put.get(columnFamily, qualifier); String newValue = ""; for (Cell cell : cells) { if (CellUtil.matchingColumn(cell, columnFamily, qualifier)) { newValue = Bytes.toString(CellUtil.cloneValue(cell)); } } // Append 操作 put.addColumn(columnFamily, qualifier, Bytes.toBytes(oldValue + newValue)); } } }6.3 打包項目
使用 maven 命令進行打包,打包後的文件名為 hbase-observer-coprocessor-1.0-SNAPSHOT.jar
# mvn clean package6.4 上傳JAR包到HDFS
# 上傳項目到HDFS上的hbase目錄 hadoop fs -put /usr/app/hbase-observer-coprocessor-1.0-SNAPSHOT.jar /hbase # 查看上傳是否成功 hadoop fs -ls /hbase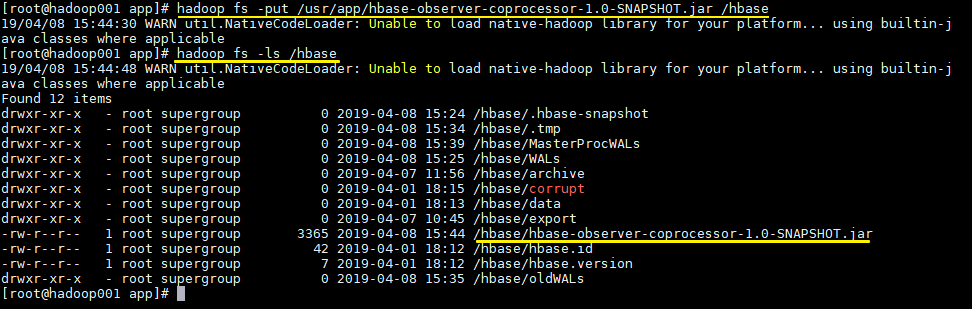
6.5 載入協處理器
- 載入協處理器前需要先禁用表
hbase > disable 'magazine'- 載入協處理器
hbase > alter 'magazine', METHOD => 'table_att', 'Coprocessor'=>'hdfs://hadoop001:8020/hbase/hbase-observer-coprocessor-1.0-SNAPSHOT.jar|com.heibaiying.AppendRegionObserver|1001|'- 啟用表
hbase > enable 'magazine'- 查看協處理器是否載入成功
hbase > desc 'magazine'協處理器出現在 TABLE_ATTRIBUTES 屬性中則代表載入成功,如下圖:
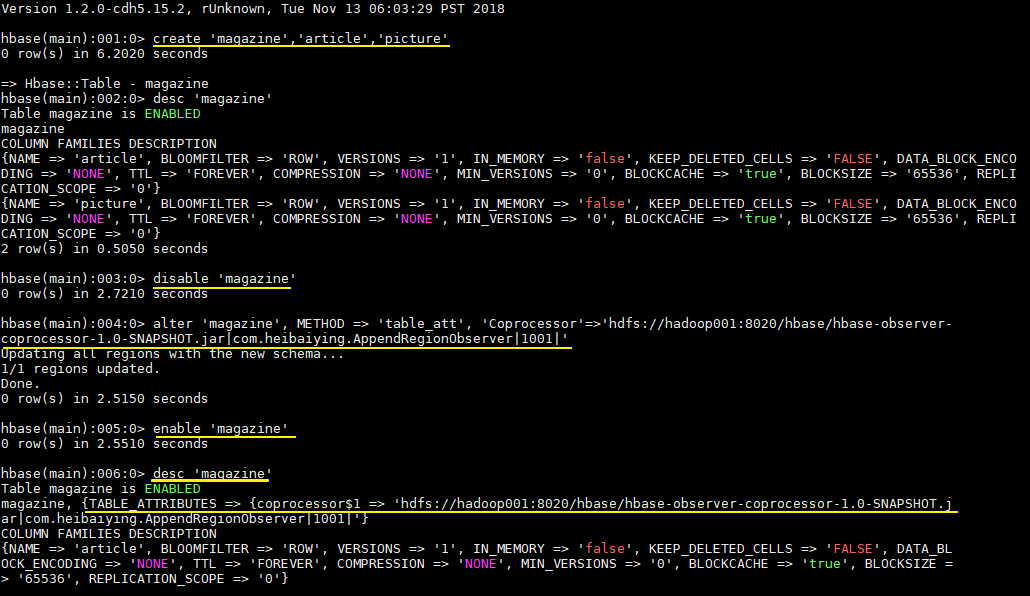
6.6 測試載入結果
插入一組測試數據:
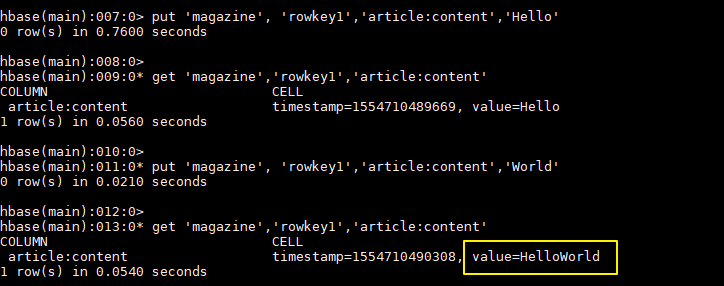
hbase > put 'magazine', 'rowkey1','article:content','Hello' hbase > get 'magazine','rowkey1','article:content' hbase > put 'magazine', 'rowkey1','article:content','World' hbase > get 'magazine','rowkey1','article:content'可以看到對於指定列的值已經執行了 append 操作:
插入一組對照數據:
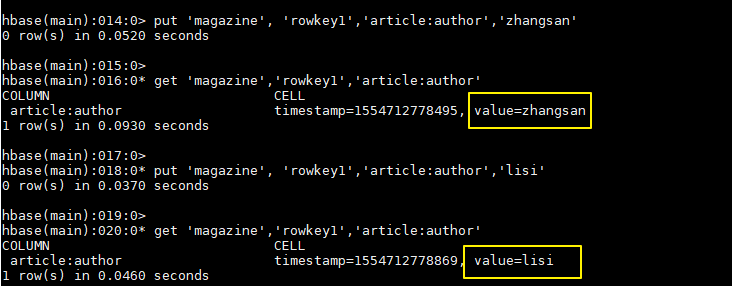
hbase > put 'magazine', 'rowkey1','article:author','zhangsan' hbase > get 'magazine','rowkey1','article:author' hbase > put 'magazine', 'rowkey1','article:author','lisi' hbase > get 'magazine','rowkey1','article:author'可以看到對於正常的列還是執行 update 操作:
6.7 卸載協處理器
- 卸載協處理器前需要先禁用表
hbase > disable 'magazine'- 卸載協處理器
hbase > alter 'magazine', METHOD => 'table_att_unset', NAME => 'coprocessor$1'- 啟用表
hbase > enable 'magazine'- 查看協處理器是否卸載成功
hbase > desc 'magazine'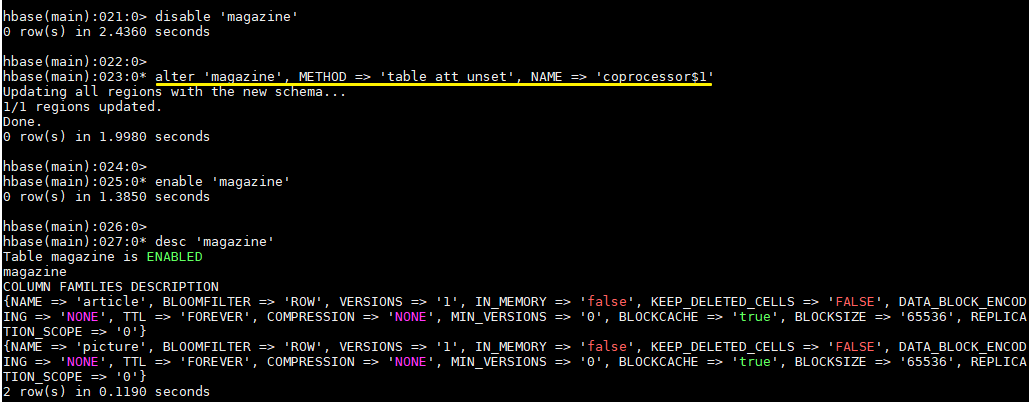
6.8 測試卸載結果
依次執行下面命令可以測試卸載是否成功
hbase > get 'magazine','rowkey1','article:content' hbase > put 'magazine', 'rowkey1','article:content','Hello' hbase > get 'magazine','rowkey1','article:content'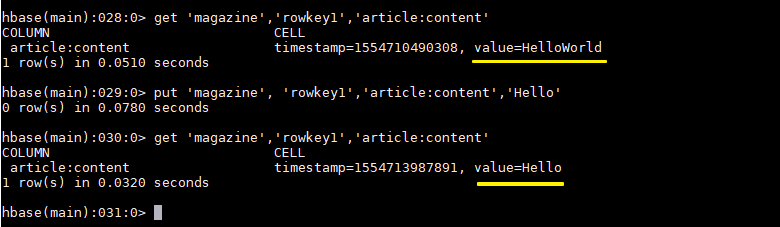
參考資料
更多大數據系列文章可以參見 GitHub 開源項目: 大數據入門指南
