Redis基礎(一)數據結構與數據類型
Redis數據結構
Redis一共有六種數據結構,分別是簡單動態字元串、鏈表、字典、跳錶、整數集合、壓縮列表。
簡單動態字元串(SDS)
Redis只會使用C字元串作為字面量,在大多數情況下,Redis使用SDS(Simple Dynamic String,簡單動態字元串)作為字元串表示。
SDS的數據結構:
struct sdshdr {
// 記錄buf數據中已使用位元組的數量
// 等於SDS所保存字元串的長度
int len;
// 記錄buf數組中未使用位元組的數量
int free;;
// 位元組數組,用於保存字元串
char buf[];
}
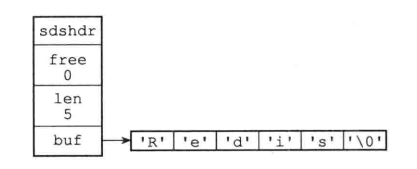
比起C字元串,SDS具有以下優點:
- 常數複雜度獲取字元串長度
- 杜絕緩衝區溢出
- 減少修改字元串時帶來的記憶體重分配次數
- 二進行安全
- 兼容部分C字元串函數
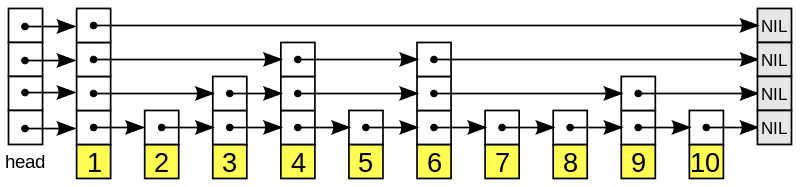
鏈表(list)
鏈表的數據結構:
typedef struct listNode {
// 前置節點
struct listNode *prev;
// 後置節點
struct listNode *next;
// 節點的值
void *value;
}listNode;
typedef struct list {
// 表頭節點
listNode *head;
// 表尾節點
listNode *tail;
// 鏈表所包含的節點數量
unsigned long len;
// 節點值複製函數
void *(*dup)(void *ptr);
// 節點值複製函數
void (*free)(void *ptr);
// 節點值對比函數
int (*match)(void *ptr,void *key);
}list;
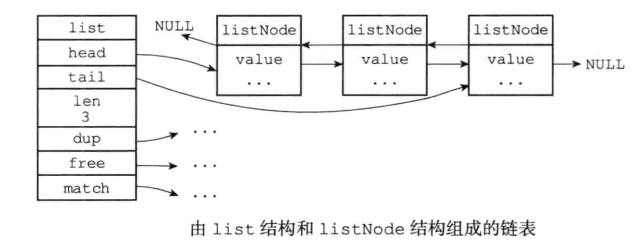
- 鏈表被廣泛用於實現Redis的各種功能,比如列表鍵、發布與訂閱、慢查詢、監視器等。
- 每個鏈表節點由一個listNode結構來表示,每個節點都有一個指向前置節點和後置節點的指針,所以Redis的鏈表實現是雙端鏈表。
- 每個鏈表使用一個list結構來表示,這個結構帶有表頭節點指針、表尾節點指針,以及鏈表長度等資訊。
- 因為鏈表表頭節點的前置節點和表尾節點的後置節點都指向NULL,所以Redis的鏈表實現是無環鏈表。
- 通過為鏈表設置不同的類型特定函數,Redis的鏈表可以用於保存各種不同類型的值。
字典(dict)
字典的數據結構:
typedef struct dictht {
// 哈希表數組
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩碼,用於計算索引值
unsigned long sizemask;
// 該哈希表已有節點的數量
unsigned long used;
}dictht;
typedef struct dictEntry {
// 鍵
void *key;
// 值
union {
void *val;
uint64_tu64;
int64_ts64;
}v;
// 指向下一個哈希表節點,形成鍵表
struct dictEntry *next;
}dictEntry;
typedef struct dict {
// 類型特定函數
dictType *type;
// 私有數據
void *privdate;
// 哈希表
dictht ht[2];
// rehash索引
// 當rehash不在進行時,值為-1
in trehashidx; /* rehashing not in progress if rehashidx == -1 */
}dict;
typedef struct dictType {
// 計算哈希值的函數
unsigned int (*hashFunction)(const void *key);
// 複製鍵的函數
void *(*keyDup)(void *privdata, const void *key);
// 複製值的函數
void *(*valDup)(void *privdata, const void *obj);
// 對比鍵的函數
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 銷毀鍵的函數
void (*keyDestructor)(void *privdata, void *key);
// 銷毀值的函數
void (*valDestructor)(void *privdata, void *obj);
}dictType;
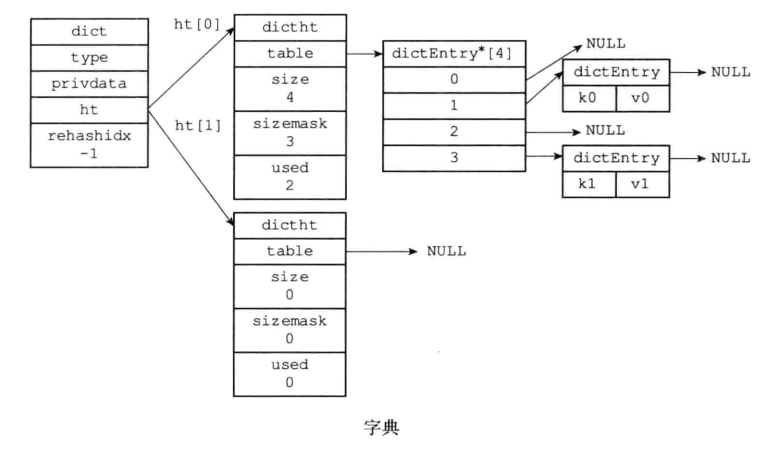
- 字典被廣泛用於實現Redis的各種功能,其中包括資料庫和哈希鍵。
- Redis中的字典使用哈希表作為底層實現,每個字典帶有兩個哈希表,一個平時使用,另一個僅在進行rehash時使用。
- 當字典被用作資料庫的底層實現,或者哈希鍵的底層實現時,Redis使用MurmurHash2演算法來計算鍵的哈希值。
- 哈希表使用鍵地址法來解決鍵衝突,被分配到同一個索引上的多個鍵值對會連接成一個單向鏈表。
- 在對哈希表進行擴展或者收縮操作時,程式需要將現有哈希表包含的所有鍵值對rehash到新哈希表裡面,並且這個rehash過程並不是一次性地完成的,而是漸進式地完成的。
跳錶(skiplist)
跳錶(skiplist)是一種有序數據結構,它通過在每個節點中維持多個指向其他節點的指針,從而達到快速訪問節點的目的。跳錶查詢的時間複雜度O(logN)、最壞情況是O(N),還可以通過順序操作來指處理節點。
跳錶的數據結構:
typedef struct zskiplistNode {
// 層
struct zskiplistLevel {
// 前進指針
struct zskiplistNode * forward;
// 跨度
unsigned int span;
} level[];
// 後退指針
struct zskiplistNode *backward;
// 分值
double score;
// 成員對象
robj *obj;
} zskiplistNode;
typedef struct zskiplist {
// 表頭節點和表尾節點
struct zskiplistNode *header, *tail;
// 表中節點數量
unsigned long length;
// 表中層數最大的節點的層數
int level;
} zskiplist;
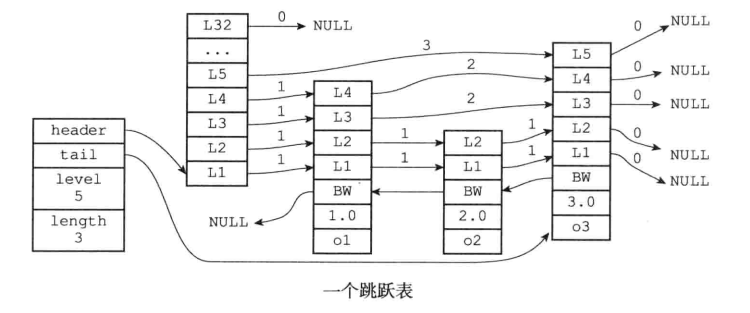
- 跳錶是有序集合的底層實現之一。
- Redis的跳錶實現由zskiplist和zskiplistNode兩個結構組成,其中zskiplist用於保存跳錶資訊(比如表頭節點、表尾節點、長度),而zskiplistNode則用於表示跳錶節點。
- 每個跳錶節點的層高都是1至32之間的隨機數。
- 在同一個跳錶中,多個節點可以包含相同的分值,但每個節點的成員對象必須是唯一的。
- 跳錶中的節點按照分值大小進行排序,當分值相同時,節點按照成員對象的大小進行排序。
整數集合(intset)
整數集合(intset)是集合鍵的底層實現之一,當一個集合只包含整數值元素,並且這個集合的元素數量不多時,Redis就會使用整數集合作為集合鍵的底層實現。
整數集合的數據結構:
typedef struct intset {
// 編碼方式
uint32_t encoding;
// 集合包含的元素數量
uint32_t length;
// 保存元素的數組
int8_t contents[];
} intset;
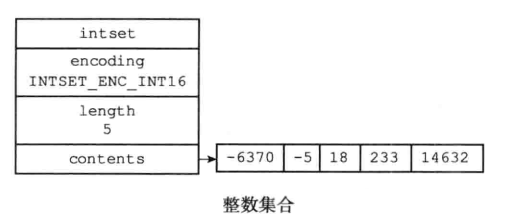
- 整數集合是集合鍵的底層實現之一。
- 整數集合的底層實現為數組,這個數組以有序、無重複的方式保存集合元素,在有需要時,程式會根據新添加元素的類型,改變這個數組的類型。
- 升級操作為整數集合帶來了操作上的靈活性,並且儘可能地節約了記憶體。
- 整數集合只支援升級操作,不支援降級操作。
壓縮列表(ziplist)
壓縮列表(ziplist)是列表鍵和哈希鍵的底層實現之一。當一個列錶鏈只包含少量列表項,並且每個列表項要麼就是小整數值,要麼就是長度比較短的字元串,那麼Redis就會使用壓縮列表來做列表鍵的底層實現。

- 壓縮列表是一種為節約記憶體而開發的順序型數據結構。
- 壓縮列表被用作列表鍵和哈希鍵的底層實現之一。
- 壓縮列表可以包含多個節點,每個節點可以保存一個位元組數組或者整數值。
- 添加新節點到壓縮列表,或者從壓縮列表中刪除節點,可能會引發連鎖更新操作,但這種操作出現的幾率並不高。
Redis數據類型
Redis中,鍵的數據類型是字元串,但提供了豐富的數據存儲方式,方便開發者使用,值的數據類型有很多,常用的數據類型有五種,分別是字元串(string)、列表(list)、字典(hash)、集合(set)、有序集合(sortedset)。
字元串(string)
「字元串(string)」這種數據結構類型非常簡單,對應到數據結構里,就是Redis里的簡單動態字元串(SDS)。
列表(list)
列表這種數據類型支援存儲一組數據。這種數據類型對應兩種實現方法,一種是壓縮列表(ziplist),另一種是雙向循環鏈表。
當列表中存儲的數據量比較小的時候,列表就可以採用壓縮列表的方式實現。具體需要同時滿足下面兩個條件:
- 列表中保存的單個數據(有可能是字元串類型的)小於64位元組;
- 列表中數據個數少於512。
字典(hash)
字典類型用來存儲一組數據對。每個數據對又包含鍵值兩部分。字典類型也有兩種實現方式。一種是壓縮列表,另一種是散列表。
同樣,只有當存儲的數據量比較小的情況下,Redis才使用壓縮列表來實現字典類型。具體需要滿足兩個條件:
- 字典中保存的鍵和值的大小都要小於64位元組;
- 字典中鍵值對的個數要小於512個。
集合(set)
集合這種數據類型用來存儲一組不重複的數據。有兩種實現方式:一種是基於有序數組,另一種是基於散列表。
當要存儲的數據,同時滿足下面這樣兩個條件的時候,Redis就採用有序數組,來實現集合這種數據類型。
- 存儲的數據都是整數;
- 存儲的數據元素個數不超過512個。
有序集合(sortedset)
有序集合用來存儲一組數據,並且每個數據會附帶一個得分。通過得分的大小,我們將數據組織成跳錶這種數據結構,以支援快速地按照得分值、得分區間獲得數據。
有序集合也有兩種實現方式:跳錶和壓縮列表。使用壓縮列表來實現有序集合的前提:
- 所有數據的大小都要小於64位元組;
- 元素個數要小於128個。