x86-TSO : 適用於x86體系架構並發編程的記憶體模型
- 2020 年 9 月 19 日
- 筆記
Abstract :
如今大數據,雲計算,分散式系統等對算力要求高的方向如火如荼。提升電腦算力的一個低成本方法是增加CPU核心,而不是提高單個硬體工作效率。
這就要求軟體開發者們能準確,熟悉地運用高級語言編寫出能夠充分利用多核心CPU的軟體,同時程式在高並發環境下要準確無誤地工作,尤其是在商用環境下。
但是做為軟體工程師,實際上不太可能花大量的時間精力去研究CPU硬體上的同步工作機制。
退而求其次的方法是總結出一套比較通用的記憶體模型,並且運用到並發編程中去。
本文結合對CPU的黑盒測試,介紹一個能夠通用於 x86 系列CPU的並發編程的記憶體模型。
此記憶體模型 被測試在 AMD 與 x86 系列CPU上具有可行性,正確性。
本文章節:
1.關於各型號CPU的說明書規定或模型規定
2.官方發布的黑盒測試及它們可復現/不可復現的CPU型號
3.指令重排的發生
4.根據黑盒測試定義抽象記憶體模型 x86-TSO
5.A Rigorous and Usable Programmer』s Model for x86 Multiprocessors 的發布團隊在AMD/Intel系列CPU上進行的一系列黑盒測試及它們與x86-TSO模型結構的關係
6.擴展
6.1 通過Hotspot源碼分析 java volatile 關鍵字的語意及其與x86-TSO/普通TSO記憶體模型的關係
6.2 Linux記憶體屏障宏定義 與 x86-TSO 模型的關係
7.總結
8.參考文獻
1.各個型號CPU的規定
CPU相關的模型或規定:
x86-CC 模型(出自 The semantics of x86-CC multiprocessor machine code. In Proc. POPL 2009, Jan. 2009)
IWP (Intel White Paper,英特爾在2007年8月發布的一篇CPU模型準則,內容給出了P1~P8共8條規則,並且用10個在CPU上的黑盒測試
來支援這8條規則)
Intel SDM (繼承IWP的Intel 模型)
AMD3.14 說明手冊對CPU的規定
2.官方黑盒測試
下面的可在…觀察到,不可在…觀察到,都是針對 最後的 State 而言,亦即 Proc 0: EAX = 0 ^ … 語句表示的最終狀態
其中倒著的V是且的意思
以下提到的StoreBuffer即CPU核心暫時快取寫入操作的物理部件,StoreBuffer中的寫入操作會在任意時刻被刷入共享存儲(主存/快取),前提是匯流排沒被鎖/快取行沒被鎖
以下提到的Store Fowarding 指的是CPU核心在讀取記憶體單元時 會去 StoreBuffer中尋找該變數,如果找到了就讀取,以便得到該記憶體單元在本核心上最新的版本
1.測試SB : 可在現代Intel CPU 和 AMD x86 中觀察到
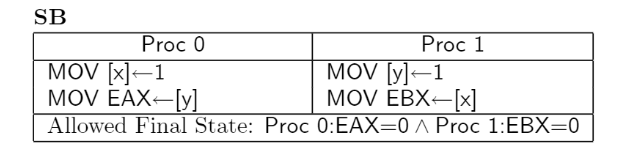
核心0 和 核心1 各有自己的Store Buffer,會造成上述情況。
核心0將 x = 1 快取在自己的StoreBuffer里,並且從共享記憶體中獲取 y = 0,之所以見不到 y = 1 是因為 核心1 將 y = 1 的操作快取在自己的StoreBuffer里
核心1將 y = 1 快取在自己的StoreBuffer里,並且從共享記憶體中獲取 x = 0,無法見到 x = 1 與上述同理
2.測試IRIW : 實際上不允許在任何CPU上觀察到,但是有的CPU模型的描述可能讓該測試發生
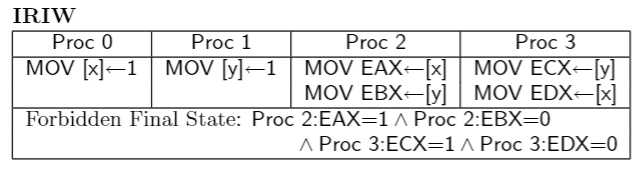
如果 核心0 和 核心2 共享 StoreBuffer,因為讀取時會先去 StoreBuffer 讀取修改,所以 核心0 執行的 x = 1 會被 CPU2 讀取,故 EAX = 1 , 因為核心1 和 核心2 不共享StoreBuffer,核心1 的 y = 1 操作快取在自己和核心3的共享StoreBuffer中
所以 EBX = 0 , CPU3的暫存器狀態同理
3.測試n6 : 在 Intel Core 2 上可以觀察到,但卻是被X86-CC模型和IWP說明禁止的

核心0 和 核心1 有各自的Store Buffer
核心0將 x = 1 快取在自己的Store Buffer 中,並且根據 Store Forwarding 原則 , 核心0 讀取 x 到 EAX 的時候
會讀取自己的Store Buffer,讀取x 的值是 1,故EAX = x = 1
同理,核心1也會快取自己的寫操作, 即快取 y = 2 和 x = 2 到自己的 StoreBuffer,因此 y = 2 這個操作不會被
核心0 觀察到,核心0 從主記憶體中載入 y 。故 EBX = y = 0
4.測試n5 / n4b :實際上不能在任何CPU上觀察到
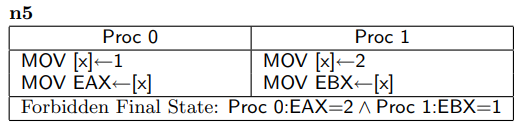
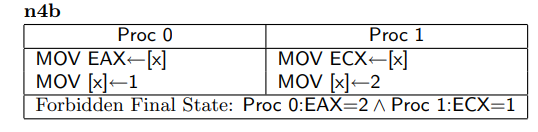
n5和n4b是同樣類型的測試,假如 核心0和 核心1都有自己的StoreBuffer
對於n5,核心0的EAX如果等於2,那麼說明 核心1的StoreBuffer刷入到 共享的主存中, 那麼 EAX = x 必然=執行於 x = 2
之後,一位 x = 1 對 EAX = x 來說是有影響的,EAX = x 和 x = 1 禁止重排,那麼 x = 1 必然不能出現在 x = 2 之前,
更不可能出現在 ECX = x 之前 (x = 2 對 ECX = x 也是有影響的,語義上嚴禁重排)
對於n4b,如果EAX = 2 ,說明 核心1的 x = 2 操作已經刷入主存被 核心0 觀察到,那麼對於 核心0來說 x = 2 先於 EAX = x 執行
同上理,ECX = x 和 x = 2 也是嚴禁重排的,故 ECX = x 要先於 EAX = x 執行,更先於 x = 1 執行
n5 和 n4b 測試在AMD3.14 和Intel SDM 中好像是可以被允許的,也就是上面的 Forbidden Final State 被許可,但實際上不能
A Rigorous and Usable Programmer』s Model for x86 Multiprocessors 中作者原話 : However, the principles stated in revisions 29–34 of the Intel SDM appear, presumably unintentionally, to allow them. The AMD3.14 Vol. 2, §7.2 text taken alone would allow them, but the implied coherence from elsewhere in the AMD manual would forbid them
實際上是概念模型如果從局部描述,沒有辦法說確切,但是從整體上看,整個模型的說明很多地方都禁止了n5和n4b的發生,可見想描述一個鬆散執行順序的CPU模型是多麼難的一件事。軟體開發者也沒辦法花大量的時間精力去鑽研硬體的結構組成和工作原理,只能依靠硬體廠商提供的概念模型去理解硬體的行為
在AMD3.15的模型說明中,語言清晰地禁止了IRIW,而不是模稜兩可的否定。
以下表格總結了上述的黑盒測試在不同CPU模型中的觀察結果(3.14 3.15是AMD不同版本的模型,29~34是Intel SDM在這個版本範圍的模型)

3.指令重排的發生
上述的黑盒測試的解釋中,提到了重排的概念,讓我們看一下從軟體層面的指令到硬體上,哪些地方可能出現 重排序:
CPU接收二進位指令流,流水線設計的CPU會依照流水線的方式串列地執行每條指令的各個階段
舉例描述:一個餐廳里 每個人的就餐需要三個階段:盛飯,打湯,拿餐具。有三個員工,每人各負責一個階段,顯然每個員工只能同時處理一個客人,也就是同一時刻,同一階段只能有一個客人,也就是任何時刻不可能出現兩位客人同時打湯的情況,當然也不可能出現兩個員工同時服務一個客人。能形成一條有條不紊的進餐流水線,不用等一個客人一口氣完成3個階段其他客人才能開始盛飯。
對於CPU也是,指令的執行分為 取指,解碼,取操作數,寫回記憶體 等階段,每個階段只能有一條指令在執行。
CPU應當有 取值工作模組,解碼工作模組,等等模組來執行指令。每種模組同一時刻只能服務一條指令,對於CPU來說,流水線式地執行指令,是串列的,沒有CPU聰明到給指令重排序一說,如果指令在CPU內部的執行順序和高級語言的語義順序不一樣,那麼很可能是編譯器優化重排,導致CPU接受到的指令
本來就是編譯器重排過的。
真正的指令重排出現在StoreBuffer的不可見上,快取一致性已經保證了CPU間的快取一致性。具體重拍的例子就是第一個黑盒測試SB:
初值:x = 0, y = 0

在我們常規的並發編程思維中,會為這4條語句排列組合(按我們的認知,1一定在2之前,3一定在4之前),並且認為無論執行緒怎麼切換,這四條語句的排列組合(1在2前,3在4前的組合)一定有一條符合最後的實際運行結果。假如按照 1 3 2 4 這樣的組合來執行,那麼最後 EAX = 1 , EBX = 1,或者 1 2 3 4 這樣的順序來執行,最後 EAX = 0 且 EBX = 1,怎麼都不可能 EAX = 0, EBX = 0
但實際上SB測試可以在Intel系列上觀察到,從軟體開發者的角度上看,就好像 按照 2 4 1 3 的順序執行了一樣,如同 2 被排在1 之前,3 被排在4 之前,是所謂 指令重排 的一種情況
實際上,是因為StoreBuffer的存在,才導致了上述的指令重排。
試想一下,CPU0將 x = 1 指令的執行快取在了自己的StoreBuffer里,CPU1也把 y = 1 的執行快取在自己的StoreBuffer里,這樣的話當兩者執行各自的讀取操作的時候,亦即CPU0執行 EAX = y
CPU1執行 EBX = x , 都會直接去快取或主存中讀取,而快取又MESI協議保證一致,但是不保證StoreBuffer一致,所以兩者無法互相見到對方的StoreBuffer中對變數的修改,於是讀到x, y都是初值 0
4.根據黑盒測試定義抽象記憶體模型 x86-TSO
從以上的試驗無法總結出一套通用的記憶體模型,因為每個CPU的實現不同,但是我們可以總結出一個合理的關於x86的記憶體模型
並且這個模型適合軟體開發者參考,並且符合CPU廠商的意圖
首先是關於StoreBuffer的設計:
1.在Intel SDM 和 AMD3.15模型中,IRIW黑盒測試是明文禁止的,而IRIW測試意味著某些CPU可以共享StoreBuffer所以我們想創造的合理記憶體模型不能讓CPU共享StoreBuffer
2.但是在上述黑盒測試中,比如n6和SB,都證明了,StoreBuffer確實存在
總結:StoreBuffer存在且每個CPU獨佔自己的StoreBuffer
上述的黑盒測試表明,除了StoreBuffer造成的CPU寫不能馬上被其他CPU觀察到,各個CPU對主存的觀察應該都是一致的,可以忽略掉快取行,因為MESI協議會保證各個CPU的快取行之間的一致性,但是無法保證StoreBuffer中的內容的一致性,因為MESI是快取一致性協議,每個字母對應快取(cache)的一種狀態,保證的只是快取行的一致性。
總結一下:我們想構造的x86模型的特點:
1. 在硬體上必然是有StoreBuffer存在的,設計時需要考慮進去
2. 快取方面因為MESI協議,各個CPU的快取之間不存在不一致問題,所以快取和主存可以抽象為一個共享的記憶體
3. 額外的一個特點是 匯流排鎖,x86提供了 lock 前綴 ,lock前綴可以修飾一些指令來達到 read-modify-write 原子性的效果,比如最常見的 read-modify-write 指令 ADD,CPU需要從記憶體中取出變數,
加一後再寫回記憶體,lock前綴可以讓當前CPU鎖住匯流排,讓其他CPU無法訪問記憶體,從而保證要修改的變數不會在修改中途被其他CPU訪問,從而達到原子性 ADD 的效果。在x86中還有其他的指令自帶
lock 前綴的效果,比如XCHG指令。帶鎖快取行的指令在鎖釋放的時候會把StoreBuffer刷入共享存儲
最後可以得到如下模型:
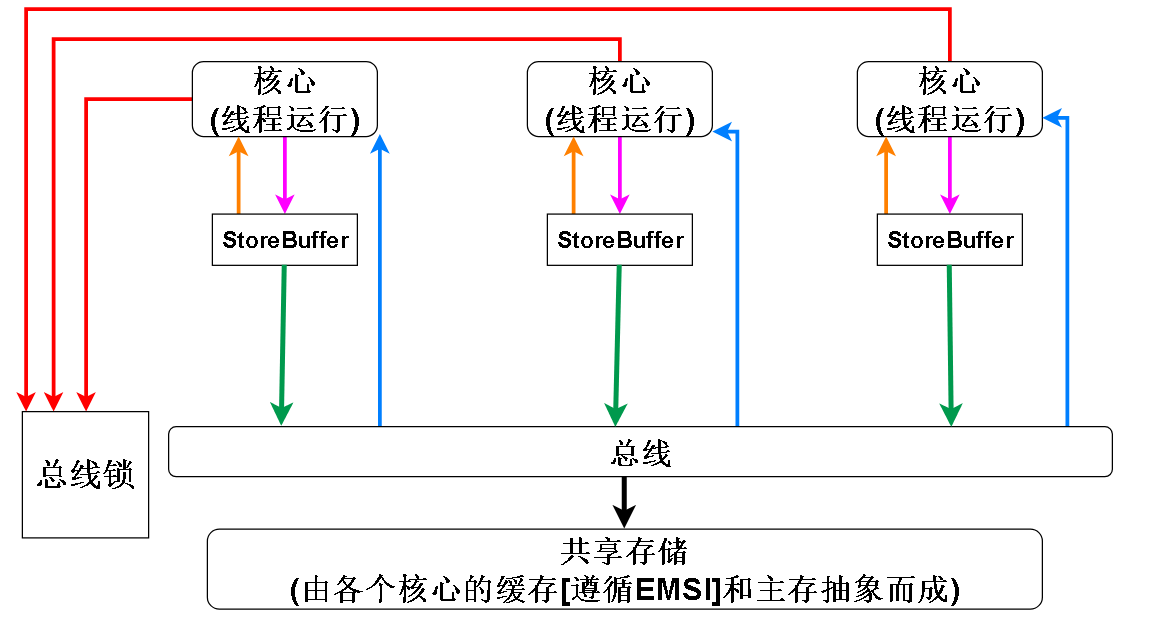
其中各顏色線段的含義:
紅色:CPU的各個核心可以爭奪匯流排鎖,佔有匯流排鎖的CPU可以將自己的storeBuffer刷入到共享存儲中(其實匯流排鎖不是真的一定要鎖匯流排,也可以鎖快取行,如果要鎖的目標不只一個快取行,則鎖匯流排),佔有期間其他CPU無法將自己的storeBuffer刷入共享存儲
橙色:根據StoreFowarding原則,CPU核心讀取記憶體單元時,首先去StoreBuffer讀取最近的修改,並且x86的StoreBuffer是遵循FIFO的隊列,x86不允許CPU直接修改快取行,所以StoreStore記憶體屏障在x86上是空操作,因為對於一個核心來說,寫操作都是FIFO的,寫操作不會重排序。x86不允許直接修改快取行也是快取和主存能抽象成一體的原因。
紫色: 核心向StoreBuffer寫入數據,在一些英文文獻中會表示為:Buffered writes to 變數名,也就是對變數的寫會被快取在StoreBuffer,暫時不會被其他CPU觀察到
綠色: CPU核心將快取的寫操作刷入共享存儲,除了有其他核心佔有鎖的情況 (因為其他核心佔有鎖的話,鎖住了快取行或匯流排,則當前核心不能修改這個快取行或訪問共享存儲),任何情況下,StoreBuffer都可以被刷入共享存儲
藍色:如果要讀取的變數不在StoreBuffer中,則去共享存儲讀取(快取或主存)
5.A Rigorous and Usable Programmer』s Model for x86 Multiprocessors 的發布團隊在AMD/Intel系列CPU上進行的一系列黑盒測試及它們與x86-TSO模型結構的關係
在A Rigorous and Usable Programmer』s Model for x86 Multiprocessors 一文中,作者為了驗證x86-TSO模型的正確性,在普遍流行的 AMD和 Intel 處理器上使用嵌入彙編的C程式進行測試。
並且使用memevents工具監視記憶體並且查看最終結果,並且用HOL4監控指令執行前後暫存器和記憶體的狀態,最後進行驗證,共進行了4600次試驗。
結果如下:
1.寫操作不允許重排序,無論是對其他核心來說還是自己來說

解釋:
從核心1 的角度看 核心0,x 和 y 的寫入順序不能顛倒
從x86-TSO模型的物理構件角度解釋就是,寫操作會按照 FIFO 的規則 進入 StoreBuffer,並且按照FIFO的順序刷入共享存儲,所以 寫操作無法重排序。
所以 x = 1 寫操作先入StoreBuffer隊列,接著 y = 1 入,刷入共享存儲的時候, x = 1 先刷入,y = 1 再刷入, 所以如果 y 讀到 1 的話,x 一定不能是 0
2.讀操作不能延遲 :對於其他核心來說,對於自己來說如果不是同一個記憶體單元,是否重排無關緊要,(因為讀不能通知寫,只有寫改變了某些狀態才能通知讀去做些什麼, 比如 x = 1; if (x == 1); )

解釋:
從核心1的角度觀察,如果EBX = 1 , 那麼說明 核心0的 y = 1 操作已經從 StoreBuffer中刷入到共享存儲,之前說過,CPU流水線執行指令在物理上是不能對指令流進行重排的,所以 EAX = x 的操作 在 y = 1 之前執行
同理,EBX = y 這個讀操作也不能延後到 x = 1 之後執行,所以 EAX = x 先於 y = 1 ,y = 1 先於 EBX = y , EBX = y 先於 x = 1 , 所以 EAX 不可能接受到 x = 1 的結果
3.讀操作可以提前:上述2是讀操作不能延後,但是可以提前,並且是從其他核心的角度觀察到的
例子是 上面的 SB測試,
如果忽視StoreBuffer,從核心1的角度看,EBX = 0,說明 x = 1 未執行,那麼 EBX = x 應該在 x = 1 之前執行,又因為 y = 1 在 EBX = x 之前,那麼 y = 1 應該在 x = 1 之前,EAX = y 在 x = 1 之後,理應在 y = 1 之後
那麼EAX 理應 = 1。

但是最後狀態可以兩者均為0.。就好像 讀取的指令被重新排到前面(下面是一種重排情況)
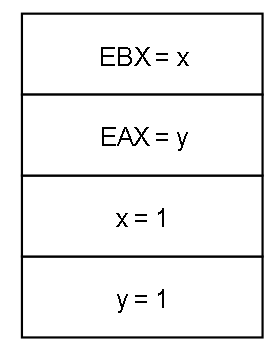
在x86-TSO模型中,寫操作是允許被提前的,從物理硬體的角度解釋如下:
假設核心0是左邊的核心,核心1是右邊的核心,如果兩者都把 寫操作快取在 StoreBuffer中,並且讀操作執行之前,StoreBuffer沒有同步回共享存儲,那麼兩者讀到的 x 和 y 都來自共享存儲,並且都是 0。

4.對於單個核心來說,因為Store Forwarding 原則,同一個記憶體單元 之前的寫操作必對之後的讀操作可見
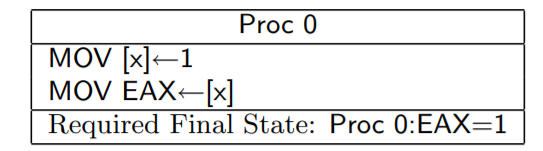
解釋:對一個核心而言,自己的寫入是能馬上為自己所見的
5.寫操作的可見性是傳遞的,這一點與 happens-before 原則的傳遞性類似,如果 A 能 看到 B 的動作,B能看到 C 的動作,那麼 A一定能看到C 的動作

解釋: 對於核心1,如果EAX = 1 ,那麼說明核心1已經見到了 核心0的動作,對於核心2,EBX = 1,說明核心2已經見到了 核心1的動作,又根據之前的 讀操作不能延後,EAX = x 不能延遲到 y = 1 之後,
所以 核心2 必能見到 核心0 的動作,所以 ECX = x 不能為 0
6.共享存儲的狀態對所有核心來說都是一致的
上面的IRIW測試就是違反共享記憶體一致性的例子:
核心2 和 核心3 觀察到 核心0 和 核心1 的行為,那麼他們的行為應該都是一樣的,因為都刷入到共享存儲中了
7.帶lock前綴的指令或者 XCHG指令,會清空StoreBuffer,使得之前的寫操作馬上被其他核心觀察到
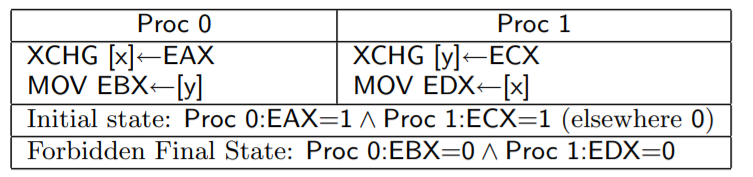
解釋:EAX一開始是1,將EAX的值寫入 x ,核心0 的 XCHD會把StoreBuffer清空,亦即將 x = EAX (1) 刷入共享存儲,核心1如果看到 x = 0 (EDX = 0 ),說明 x = EAX 在後面才執行。推得y = ECX 在 x = EAX 之前執行
y = ECX 也會馬上刷入共享存儲,必然對 核心 0 可見,所以 最後不可能 x = 0, y = 0
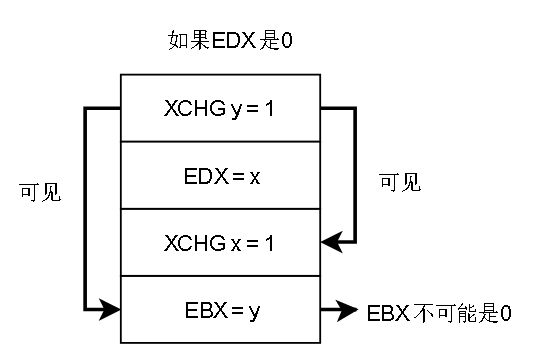
MFENCE指令在x86-TSO模型上也能達到刷StoreBuffer的效果。
總結:在x86-TSO模型上,唯一可能重排序的清空是 讀被提前了(從多個CPU的視角看),實際上是 StoreBuffer快取了寫操作,導致寫操作沒寫出來。
6.擴展:
6.1 通過Hotspot源碼分析 java volatile 關鍵字的語意及其與x86-TSO/普通TSO記憶體模型的關係
Java 的 volatile語意:Hotspot實現
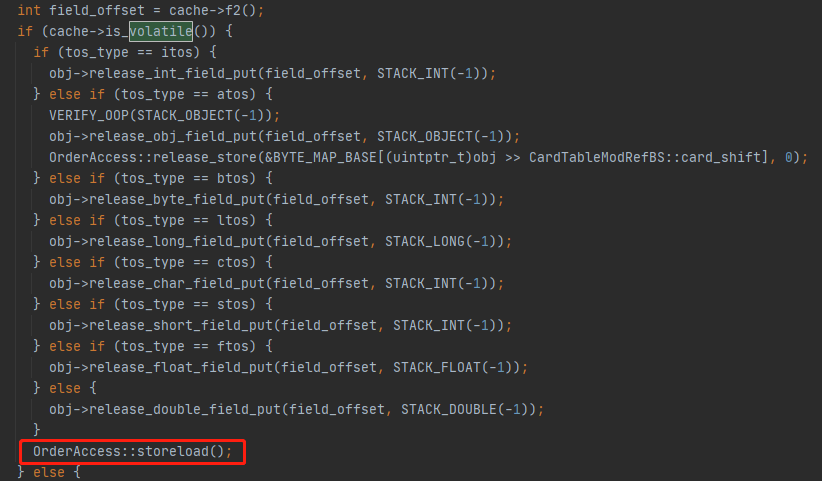
在JVM的位元組碼解釋器中,如果putstatic位元組碼或putfield位元組碼的變數是java層面的volatile關鍵字修飾的,就會在指令執行的最後插入一道 storeLoad 屏障,前文已經說過,在x86中
唯一可能重排的是 讀操作提前到 寫操作之前,這裡的storeLoad操作做的就是阻止重排
![]()
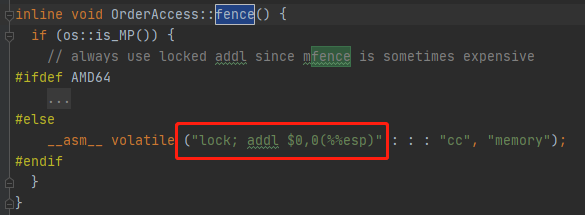
在os_cpu/linux_x86下的實現如下:
其實只是執行了一條帶lock前綴的空操作嵌入彙編指令(棧頂指針+0是空操作),實現的效果就是把StoreBuffer中的內容刷入到 共享存儲中
其實還有一層加強, __ asm __ 後面的volatile關鍵字 會阻止編譯器對本條指令前後的指令重排序優化,這保證了CPU得到的指令流是符合我們程式的語意的
在模板解釋器中:
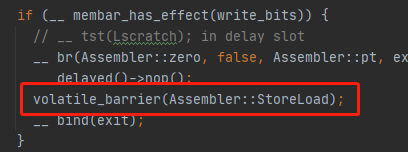

一開始我驚訝於此,這句話沒有為不同平台實現選擇不同的實現方法,而是簡單檢查如果不是需要 storeLoad 屏障就跳過。

其實作者註解已經說的很明白,現在大部分RISC的SPARC架構的CPU的實現都滿足TSO模型,所以只需要StoreLoad屏障而已
我在新南威爾斯大學的網站上找到了關於TSO的比較正宗的解釋:

下面的討論中,是否需要重排序是根據CPU最後的行為是否符合我們高級語言程式的語意順序決定的,如果相同則不需要,不相同則需要。
也就是單個核心中,寫操作之間是順序的,會按二進位指令流的寫入順序刷到共享存儲,不需要考慮重排的情況,所以不需要StoreStore屏障
遵循Store Forwarding,所以對於本核心,本核心的寫操作對後續的讀操作可見。這三點已經十分符合本文的x86-TSO模型。
有一點沒有呈現,就是單個CPU核心中,是否禁止讀延遲,也就是寫操作不能跨越到讀操作之前,根據上面的 只有StoreLoad 屏障有操作,其他屏障,包括LoadStore屏障無操作可以推斷
普通的TSO模型也是遵循禁止讀延遲原則的
6.2 Linux記憶體屏障宏定義 與 x86-TSO 模型的關係
Linux 的記憶體屏障宏定義
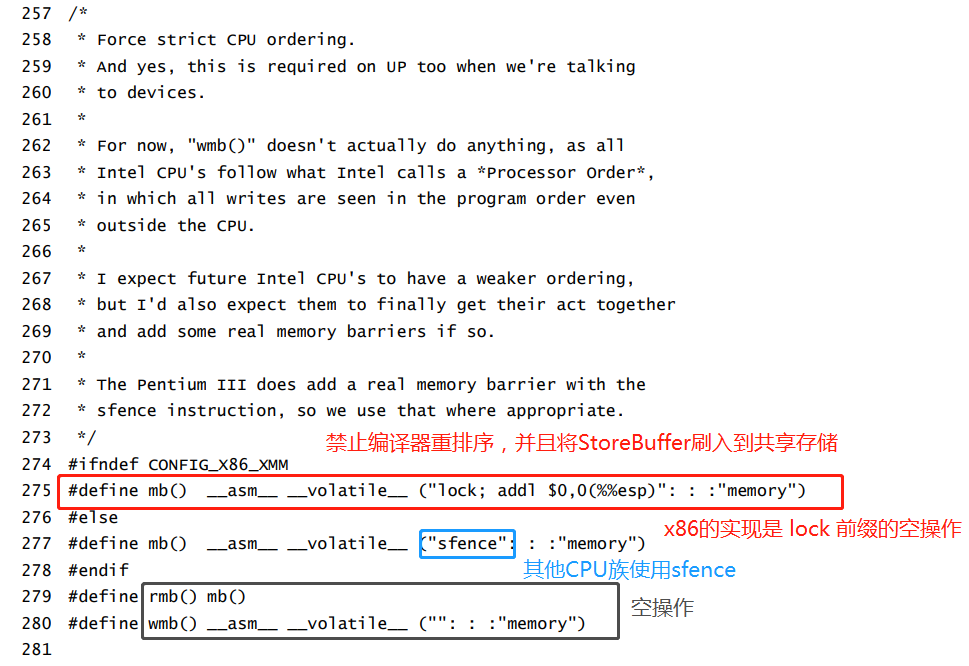
在Linux下定義的具有全功能的記憶體屏障,是有實際操作的,和JVM的storeLoad如出一轍
讀屏障是空操作,寫屏障只是簡單的禁止編譯器重排序,防止CPU接收的指令流被編譯器重排序。
只要編譯器能編譯出符合我們高級語言程式語意順序的二進位流給CPU,根據TSO模型的,CPU執行這些指令流的中的寫操作對外部呈現出來的(刷入共享存儲被所有CPU觀察到)就是FIFO順序
讀操作不涉及任何狀態變更,所以不需要記憶體屏障(也許只有在x86上才不需要,在其他有Invaild Queue的CPU結構中或許需要)
7.總結
本文總結:
x86-TSO模型的特點總結:
因為快取有MESI協議保證一致性,所以快取可以和主存合併抽象成共享存儲
x86-TSO的寫操作嚴格遵循FIFO
CPU流水線式地執行指令會使得CPU對接受到的指令流順序執行
x86-TSO中唯一重排的地方在於StoreBuffer,因為StoreBuffer的存在,核心的寫入操作被快取,無法馬上刷新到共享存儲中被其他核心觀察到,所以就有了 「 寫 」 比 「讀」 晚執行的直觀感受,也可以說是讀操作提前了,排到了寫操作前
阻止這種重排的方法是 使用帶 lock 前綴的指令或者XCHG指令,或MFENCE指令,將StoreBuffer中的內容刷入到共享存儲,以便被其他核心觀察到
8.本文參考文獻
參考文獻:
《Linux內核源程式碼情景分析》:毛德操
x86-TSO: A Rigorous and Usable Programmer』s Model for x86 Multiprocessors
Memory Barriers: a Hardware View for Software Hackers


