實踐案例丨基於 Raft 協議的分散式資料庫系統應用
摘要:簡單介紹Raft協議的原理、以及存儲節點(Pinetree)如何應用 Raft實現複製的一些工程實踐經驗。
1、引言
在華為分散式資料庫的工程實踐過程中,我們實現了一個計算存儲分離、 底層存儲基於Raft協議進行複製的分散式資料庫系統原型。下面是它的架構圖。
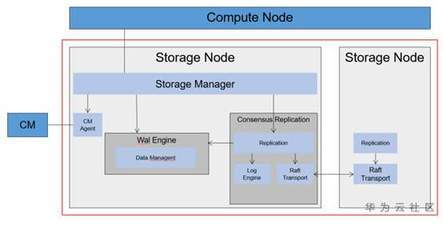
計算節點生成日誌經過封裝後通過網路下發到存儲節點,在Raft層達成一致後日誌被應用到狀態機wal Engine,完成日誌的回放和數據的存儲管理。
下面簡單介紹一下Raft的原理、以及存儲節點(Pinetree)如何應用 Raft實現複製的一些工程實踐經驗。
2、Raft的原理
2.1 Raft的基本原理
Raft 演算法一切以領導者為準,實現一系列值的共識和各節點日誌的一致。下面重點介紹一下Raft協議的Leader選舉、log複製 和 成員變更。
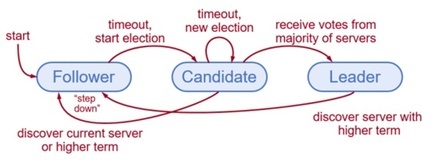
Raft的選舉機制:
協議為每個節點定義了三個狀態:Leader、Candidate、Follower,將時間定義為Term,每個Term有一個ID。Term類似邏輯時鐘,在每個Term都會有Leader被選舉出來。
Leader負責處理所有的寫請求、發起日誌複製、定時心跳,每個Term期間最多只能有一個Leader,可能會存在選舉失敗的場景,那麼這個Term內是沒有Leader。
Follower 處於被動狀態,負責處理Leader發過來的RPC請求,並且做出回應。
Candidate 是用來選舉一個新的Leader,當Follower超時,就會進入Candidate狀態。
初始狀態,所有的節點都處於Follower狀態,節點超時後,遞增current Term進入Candidate,該節點發送廣播消息RequestVote RPC給其他Follower請求投票。當收到多數節點的投票後,該節點從Candidate進入Leader。Follower在收到投票請求後,會首先比較Term,然後再比較日誌index,如果都滿足則更新本地Current Term然後回應RequestVote RPC為其投票。每個Term期間,follower只能投一次票。
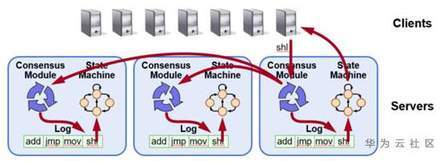
Raft的日誌同步機制:
當Leader被選舉出來後,就可以接受寫請求。每個寫請求即代表了用戶需要複製的指令或Command。Raft協議會給寫請求包裝上Term和Index,由此組成了Raft的Log entry. Leader把Log entry append到日誌中,然後給其它的節點發AppendEntries RPC請求。當Leader確定一個Log entry被大多數節點已經寫入日誌當中,就apply這條Log entry到狀態機中然後返回結果給客戶端。
Raft成員變更機制:
成員變更就意味著集群節點數的增加或減少以及替換。Raft協議定義時考慮了成員變更的場景,從而避免由於集群變化引起的系統不可用。Raft是利用上面的Log Entry和一致性協議來實現該功能。成員的變更也是由Leader發起的,Leader會在本地生成一個新的Log entry,同時將Log entry推送到其他的Follower節點。
Follower節點收到Log entry後更新本地日誌,並且應用該log中的配置關係。多數節點應用後,Leader就會提交這條變更log entry。還要考慮新就配置的更替所帶來的問題。更詳細的不再贅述。
2.2 Raft的開源實現
Raft的實現有coreos的etcd/raft、kudu、consul、logcabin、cockroach等。
Etcd 、LogCabin 、Consul 實現的是單個Raft環,無法做到彈性伸縮。而kudu和cockroach實現了多個raft環。kudu的consensus 模組實現了副本的數據複製一致性,kudu將數據分片稱之為Tablet, 是kudu table的水平分表,TabletPeer就是在Raft環裡面的一個節點. 一個Tablet相當於一個Raft環,一個Tablet對應一個Raft Consensus,這些對應Raft裡面的一個環,Consensus Round相當於同步的消息,一個環之間會有多個Consensus Round做同步。而cockroach則是基於etcd/raft實現的多Raft環,它維護了多個Raft實例,被稱之為multiraft。
因為Etcd的Raft是目前功能較全的Raft實現之一,最早應用於生產環境,並且做到了很好的模組化。其中Raft內核部分實現了Raft大部分協議,而對外則提供了storage和transport所用的interface,對於使用者可以單獨實現靈活性較高,用戶還可以自主實現 snapshot、wal ,Raft非常便於移植和應用,因此存儲節點Pinetree採用了開源的Etcd中的Raft實現來構建我們的原型系統,也便於後期向Multiraft演進。。
3、工程實踐
3.1 實現Raft的存儲介面和網路傳輸
Raft存儲部分指的是raft- log的存儲,是對日誌條目進行持久化的存儲,通過benchmark測試發現,raft-log引擎性能是影響整體ops的主要瓶頸,為了更靈活的支援底層存儲引擎的快速替換,增加可插拔的存儲引擎框架,我們對底層存儲引擎進行解耦。Pinetree封裝了第三方獨立存儲介面來適配etcd raft的log存儲介面;
通訊部分即Raft Transport、snapShot傳輸等,採用GRPC+Protobuf來實現,心跳、日誌傳輸AppendEntries RPC、選舉RequestVote RPC等應用場景將GRPC設置為簡單式,snapShot設置為流式的形式。
3.2 選舉問題
Raft可以實現自我選舉。但是在實踐中發現缺點也很明顯,Raft自主選主可能存在如下的問題:
1、不可控:可能隨意選擇一個滿足Raft條件的節點
2、網路閃斷導致Leader變動
3、節點忙導致的Leader變動
4、破壞性的節點
為了防止存儲節點Leader在不同的AZ或者節點間進行切換,Pinetree採用的方案是由集群管理模組來指定 Leader。Pinetree中將electionTimeout設置為無窮大,關閉Follower可能觸發的自動選舉過程,一切選舉過程由集群管理的建議選主模組來控制。
3.3 讀一致性模型
在 Raft 集群中,一般會有 default、consistent、stale 三種一致性模型,如何實現讀操作關乎一致性的實現。一般的做法是將一致性的選擇權交給用戶,讓用戶根據實際業務特點,按需選擇,靈活使用。
Consistent具有最高的讀一致性,但是實現上要求所有的讀請求都要走一遍Raft 內核並且將會與寫操作串列,會給集群造成一定的壓力。stale具有很好的性能優勢,但是讀操作可能會落到數據有延遲的節點上。在Pinetree的設計中,集群管理負責維護存儲節點的資訊,管理所有節點的Raft主副本的狀態,一方面可以對讀請求進行負載均衡,另一方面可以根據AZ親和性、副本上的數據是否有最新的log 來路由讀請求。這樣在性能和一致性之間進行了最大的tradeoff。
3.4 日誌問題
Raft以Leader為中心進行複製需要考慮幾個問題:
1、性能問題,如果leader為慢節點會導致長尾
2、日誌的同步必須是有序提交
3、切換leader時有一段時間的不可用
問題3我們通過集群管理來最大程度的防止Leader的切換。
對於問題2,因為Pinetree的日誌類似innodb的redo log ,採用LSN來編號的,所以應用到Pinetree存儲層的的日誌必須要保序,不能出現跳過日誌段或日誌空洞的情況。這就要求發給Raft的日誌要做保序處理。計算層產生的wal log都對應一個LSN,LSN代表的是日誌在文件中的偏移量,具有單調遞增且不連續的特點。因此要求Wal log產生的順序和apply到pinetree storage的順序要保證一致。為了滿足這一需求,我們在計算層和Raft層中間增加一個適配層,維護一個隊列負責進行排序,同時為了應對計算層主備的切換,對消息增加Term以保證日誌不會亂序。Raft指令還可能會被重複提交和執行,所以存儲層要考慮冪等性的問題。因為Pinetree storage的日誌用LSN進行編號,所以可以進行重複apply。
3.5 如何解決假主問題
計算節點需要獲取某些元數據資訊,每次都必須從Leader中讀取數據防止出現備機延遲。在網路隔離的情況下,老的leader不會主動退出,會出現雙主的情況,這個假主可能永遠不知道自己其實已經不是真正的Raft主節點,導致真Leader和假Leader同時存在並提供讀服務,這在無延遲系統是不允許的。
如果每次讀請求都走一遍Raft協議可以識別出假主,但是將會嚴重的影響系統的性能。
Pinetree是通過租約(lease)的方式,讓一個Pinetree主節點在提供服務之前,保守地檢查自身在這一時刻是否擁有lease,再決定自身能不能提供讀服務。因此,就算訪問了一個Pinetree假主,假主也因為沒有lease而不能提供服務。
3.6 性能問題
涉及到性能Pinetree考慮和優化的地方:
1 如果使用 Raft 演算法 保證強一致性,那麼讀寫操作都應該在領導者節點上進行。這樣的話,讀的性能相當於單機,不是很理想, 優化實現了基於leader+lease的方式來提供讀服務即能保證一致性又不影響性能。
2 優化raft參數 :in-flight的數目;transport queue的數量
3 最大限度的非同步化,例如:指令在raft達成一致完成持久化後傳遞給狀態機存入消息隊列立即返回,後續對消息進行非同步並行解析。
4 最大限度的進行Batch和Cache。例如:把一個事務內的寫操作快取到客戶端,在事務提交時,再把所有的寫打包成一個batch與事務commit請求一起發送給服務端
#DevRun開發者沙龍# 9月15日20:00-21:00,特邀華為雲資料庫解決方案專家Sugar,為您打造專場直播「端到端安全可信,華為雲資料庫解決方案最佳實踐」!華為雲資料庫服務,聚焦互聯網、車企、金融、遊戲、ISV、地圖等行業痛點,滿足企業用戶多樣性計算需求。提供端到端安全可信的解決方案,幫助企業應用全面雲化和智慧化。歡迎點擊直播(//live.vhall.com/206537223)圍觀,社區互動(//bbs.huaweicloud.com/forum/thread-76193-1-1.html)有禮!
