大數據架構的簡單概括
- 2019 年 10 月 3 日
- 筆記
一、大數據的發展史
2004年
Google前後發表三篇論文,也就是傳說中的「三駕馬車」
- 分頁式文件系統GFS
- 大數據分散式計算框架MapReduce
- NoSQL資料庫系統BigTable
2006年
Doug Cutting啟動了一個赫赫有名的項目Hadoop,主要包括Hadoop分散式文件系統HDFS和大數據計算引擎MapReduce,分別實現了GFS和MapReduce其中兩篇論文
2007年
HBase誕生,實現了Big Table最後一篇論文
2008年
出現 了Pig、Hive,支援使用SQL語法來進行大數據計算,極大的降低了Hadoopr的使用難度,數據分析師和工程師可以無門檻地舒不舒服和大數據進行數據分析和處理
2012年
Haddop將執行引擎和資源調度分離出來,成立了Yarn資源調度系統,這年Spark也開始嶄露頭角,逐步替代MapReduce在企業應用中的地位
…
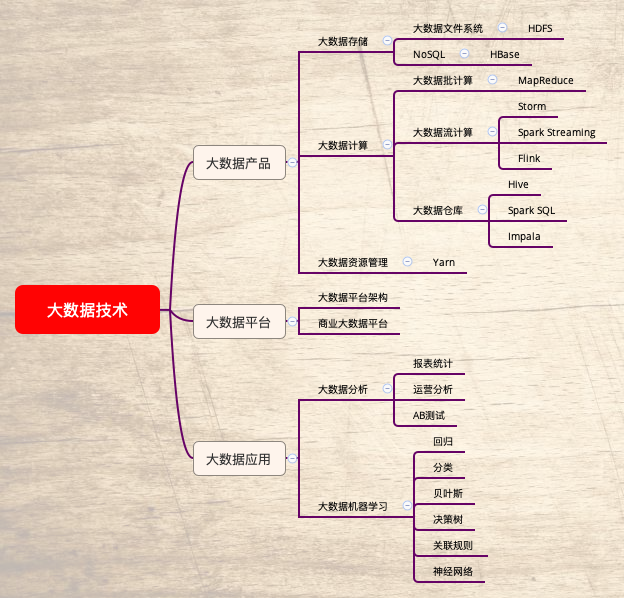
二、大數據架構
1. 數據分析與數據倉庫
Hive、Spark SQL
2. 數據挖掘與機器學習
Mahout、MLib、TensorFlow
3. 批處理
MapReduce、Spark
4.NoSQL系統
HBase、Cassandra
5. 大數據存儲
HDFS
三、大數據計算原理
- 在待處理的數據存儲在伺服器集群的所有伺服器上,主要使用HDFS系統,將文件分成很多塊(Block),以塊為單位存儲在集群的伺服器上
- 大數據引擎根據集群里的不同伺服器的計算能力,在每台伺服器上啟動若干分散式任務執行進程,這些進程會等待給它們分配執行任務
- 使用大數據計算框架支援的編程模型進行編程,比如Hadoop的MapReduce編程模型,或Spark的RDD編程模型,編寫應用程式,例如python或java程式
- 用Haddop或Spark的啟動命令執行這個應用程式,執行引擎會解析程式要處理的數據輸入路徑,根據輸入數據量的大小,將數據分片,每個片分配給一個任務執行進程去處理
- 任務執行進收到任務後檢查是否有任務對應的程式包,沒有就去下載,下載後載入程式
- 載入程式後,任務根據分配的數據片的文件地址和數據在文件內的偏移量讀取數據,並把數據輸入給應用程式相應的方法去執行,從而實現分散式伺服器集群中並行處理的計算目標
總結:大數據是龐大的,程式要比數據小得多,將數據輸入給程式是不划算的,那麼就反其道行之,將程式發到數據所在的地方進行計算,也就是所謂的移動計算比移動數據更划算
三、大數據應用
相應技術
數據分析、數據挖掘、機器學習
應用領域
醫療、教育、社交媒體、金融、新零售、交通
四、大數據平台集成
1.自建大數據平台
- 數據採集
將應用程式產生的數據和日誌等同步到大數據系統中,由於數據源不同,這裡的數據同步系統實際上是多個相關係統的組合。資料庫同步通常用Sqoop,日誌同步可以選擇Flume,打點採集的數據經過格式化轉換後通過kafka等消息隊列進行傳遞
不同的數據源產生的數據品質可能差別很大,資料庫中的數據也許可以直接導入大數據系統就可以使用了,而日誌和爬蟲產生的數據就需要進行大量的清洗、轉化處理才能有效使用 - 數據處理
這部分是大數據存儲與計算的核心,數據同步系統導入的數據存儲在HDFS
MapReduce、Hive、Spark等計算任務讀取HDFS上的數據進行計算,再將計算結果寫入HDFS
MapReduce、Hive、Spark等計算處理被稱為離線計算,HDFS存儲的數據被稱為離線數據
另外一些數據規模比較大,但是要求處理的時間卻比較短,稱為大數據流式計算,通過用Storm、Spark Streaming等流式大數據引擎來完成 - 數據輸出與展示
大數據產生的數據還是寫入到HDFS中,但應用程式不可能到HDFS中讀取數據,所以必需要將HDFS的數據導出到資料庫中。數據同步導出相對比較容易,計算產生的數據都比較規範,稍作處理就可以用Sqoop之類的系統導出到資料庫
這時,應用程式就可以直接訪問資料庫中的數據,實時展示給用戶,比如展示給用戶關聯推薦的商品
除了給用戶訪問提供數據,大數據還需要給運營和決策層提供各種統計報告,這些數據也寫入資料庫,被相應 的後台系統訪問。
2. 商業大數據平台
- CDH
包含數據集成、大數據存儲、統一服務、過程分析與計算 - 雲計算廠商
阿里雲、華為雲都有相應的產品,可以自己去搜索一下
五、金字塔方式總結