2020重新出發,NOSQL,MongoDB是什麼?
什麼是MongoDB ?
MongoDB 是一個開源的文檔資料庫,它基於 C++ 語言編寫,性能高,可用性強,能夠自動擴展。
MongoDB 是最流行的 NoSQL 資料庫之一,原生支援分散式集群架構,特別適合處理大數據,阿里巴巴、騰訊、頭條、Twitter、Google、Facebook 等一線互聯網公司都在使用 MongoDB 資料庫。
與 HBase 相比,MongoDB 可以存儲具有更加複雜的數據結構的數據,具有很強的數據描述能力。MongoDB 提供了豐富的操作功能,但是它沒有類似於 SQL 的操作語言,語法規則相對比較複雜。
MongoDB(來自英文單詞「Humongous」,中文含義為「龐大」)是可以應用於各種規模的企業、各個行業以及各類應用程式的開源資料庫。
MongoDB的優勢
MongoDB 使用廣泛
MongoDB 是目前 NoSQL 資料庫中使用最廣泛的資料庫之一,根據 DB-Engines 2020 年 9 月份發布的全球資料庫排名(見圖 1),前五名依次是 Oracle、MySQL、Microsoft SQL Server、PostgreSQL、MongoDB ,此排名順序已經持續很長時間,MongoDB 排名第五,9月份 MongoDB 的分數依然保持增長,而且還是整個排行榜中增長幅度最大的一個。

MongoDB 性能高
MongoDB 是一個開源文檔資料庫,是用 C++ 語言編寫的非關係型資料庫。其特點是高性能、高可用、可伸縮、易部署、易使用,存儲數據十分方便,主要特性有:面向集合存儲,易於存儲對象類型的數據,模式自由,支援動態查詢,支援完全索引,支援複製和故障恢復,使用高效的二進位數據存儲,文件存儲格式為 BSON ( 一種 JSON 的擴展)等。
MongoDB 提供高性能數據讀寫功能,並且性能還在不斷地提升。根據官方提供的 MongoDB 3.0 性能測試報告,在 YCSB 測試中,MongoDB 3.0 在多執行緒、批量插入場景下的處理速度比 MongoDB 2.6 快 7 倍。
關於讀寫與響應時間的具體測試結果參見圖 2。
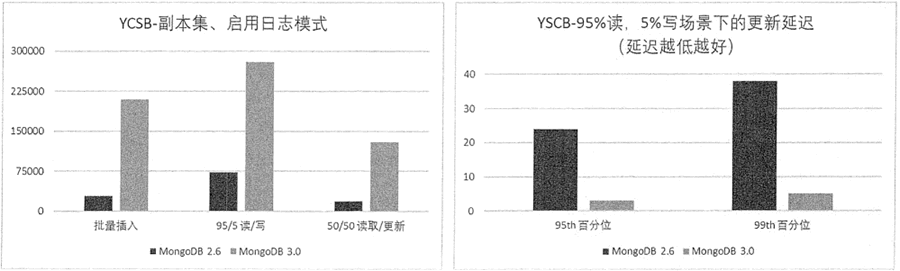
圖 2:MongoDB 2.6 與 3.0 讀寫性能與響應時間性能測試
MongoDB 支援分散式
在生產過程中,因機器故障導致系統宕機的問題不可避免;集中式系統在計算能力和存儲能力方面的瓶頸,也無法滿足當前的數據量爆髮式增長的需求。這兩個問題就是系統對高可用和可伸縮架構的需求,MongoDB 在原生上就可滿足這兩方面的需求。
MongoDB 的高可用性體現在對副本集 Replication 的支援上,可伸縮性體現在分片集群的部署方式上。
MongoDB 的 Replication 集提供自動故障轉移和數據冗餘服務,Replication 結構可以保證資料庫中的全部數據都會有多份備份,這與 HDFS 分散式文件系統的備份機制比較類似。採用副本集的集群中具有主(Master)、從(Slaver)、仲裁(Arbiter)三種角色。
主從關係(Master-Slaver) 負責數據的同步和讀寫分離;Arbiter 服務負責心跳(Heartbeat)監控,Master 宕機時可將 Slaver 切換到 Mas 血狀態,繼續提供數據的服務,完成了數據的高可用需求。
當需要存儲大量的數據時,主從伺服器都需要存儲全部數據,可能會出現寫性能問題。同時, Replication 主要解決的是讀數據高可用方面的問題,在對資料庫查詢時也只限制在一台伺服器上, 並不能支援一次查詢多台資料庫伺服器,並沒有滿足資料庫讀寫操作的分散式需求。
MongoDB 提供水平可伸縮性功能的是分片(Shard)。分片與在 HDFS 分散式文件系統中上傳文件會將文件切成 128MB(Hadoop2.x 默認配置)相似,通過將數據切成數片(Sharding)寫入不同的分片節點,完成分散式寫的操作。同時,MongoDB 在讀取時提供了分散式讀的操作,這個功能與 HDFS 的分散式讀寫十分類似。
MongoDB 便於開發
MongoDB 對開發者十分友好,便於使用。支援豐富的查詢語言、數據聚合、文本搜索和地理空間查詢,用戶可以創建豐富的索引來提升查詢速度,MongoDB 被稱為最像關係資料庫的非關係資料庫。
MongoDB 允許用戶在服務端執行腳本,可以用 Javascript 編寫某個函數,直接在服務端執行,也可以把函數的定義存儲在服務端,使用時直接調用即可。MongoDB 支援各種程式語言,包括 Ruby、Python、Java、C++、PHP、C# 等。
Robomongo(MongoDB可視化工具)簡介
Robomongo 是一個介面友好且免費的 MongoDB 可視化工具,可在 Robomongo 官網下載此軟體,其安裝過程十分簡單,安裝好的介面如下圖所示。
在 MongoDB Connections 窗口單擊滑鼠右鍵添加 MongoDB 資料庫,設置如下圖所示。
連接成功後,MongoDB 中所有資料庫以及集合均顯示在左側導航欄,如圖下所示。
從上圖中可以看到 Robomango 提供可視化的介面將資料庫中的文檔顯示出來,在集合上單擊滑鼠右鍵可以顯示提供的集合操作。
使用 Robomango,初學者能更容易理解 MongoDB 資料庫的概念。
MongoDB的文檔數據模型
傳統的文檔資料庫(Document Storage)概念的提岀要追溯到 1989 年,Lotus 提出的 Notes 產品被稱為文檔資料庫,這種文檔資料庫常用於管理文檔,如 Word、建立工作流任務等。
文檔資料庫區別於傳統的其他資料庫,它可用來管理文檔,尤其擅長處理各種非結構化的文檔數據。在傳統的資料庫中,資訊被分割成離散的數據段,而在文檔資料庫中,文檔是處理資訊的基本單位。
傳統的文檔資料庫與 20 世紀 50 ~ 60 年代管理數據的文件系統不同,文檔資料庫仍屬於資料庫範疇。
首先,文件系統中的文件基本上對應於某個應用程式。當不同的應用程式所需要的數據部分相同時,也必須建立各自的文件,而不能共享數據,而文檔資料庫可以共享相同的數據。因此,文件系統比文檔資料庫數據冗餘度更大,更浪費存儲空間,且更難於管理維護。
其次,文件系統中的文件是為某一特定應用服務的,因此,要想對現有的數據再增加一些新的應用是很困難的,系統難以擴展,數據和程式缺乏獨立性。而文檔資料庫具有數據的物理獨立性和邏輯獨立性,數據和程式分離。
NoSQL 中的文檔資料庫
NoSQL 中的文檔資料庫(以下文檔資料庫均指 NoSQL 中的文檔資料庫)與傳統的文檔資料庫不是同一種產品,NoSQL 中的文檔資料庫(MongoDB)有自己特定的數據存儲結構及操作要求。
在傳統資料庫的發展過程中,基本都是出現一種數據模型,再依據數據模型,開發出相關的資料庫,例如,層次資料庫是建立在層次數據模型的基礎上,關係資料庫是建立在關係數據模型的基礎上的。NoSQL 中文檔資料庫的出現也是建立在文檔數據模型的基礎上的。
NoSQL 中的文檔資料庫與傳統的關係資料庫均建立在對磁碟讀寫的基礎上,實現對數據的各種操作。文檔資料庫的設計思路是儘可能地提升數據的讀寫性能,為此選擇性地保留了部分關係型資料庫的約束,通過減少讀寫過程的規則約束,提升了讀寫性能。
MongoDB 文檔數據模型
傳統的關係型資料庫需要對錶結構進行預先定義和嚴格的要求,而這樣的嚴格要求,導致了處理數據的過程更加煩瑣,甚至降低了執行效率。
在數據量達到一定規模的情況下,傳統關係型資料庫反應遲鈍,想解決這個問題就需要反其道而行之,儘可能去掉傳統關係型資料庫的各種規範約束,甚至事先無須定義數據存儲結構。
文檔存儲支援對結構化數據的訪問,與關係模型不同的是,文檔存儲沒有強制的架構。文檔存儲以封包鍵值對的方式進行存儲,文檔存儲模型支援嵌套結構。
- 例如,文檔存儲模型支援 XML 和 JSON 文檔,欄位的「值」可以嵌套存儲其他文檔,也可存儲數組等複雜數據類型。
MongoDB 存儲的數據類型為 BSON,BSON 與 JSON 比較相似,文檔存儲模型也支援數組和鍵值對。
MongoDB 的文檔數據模型如圖下所示,MongoDB 的存儲邏輯結構為文檔,文檔中採用鍵值對結構,文檔中的 _id 為主鍵,默認創建主鍵索引。從 MongoDB 的邏輯結構可以看出,MongoDB 的相關操作大多通過指定鍵完成對值的操作。
文檔資料庫無須事先定義數據存儲結構,這與鍵值資料庫和列族資料庫類似,只需在存儲時採用指定的文檔結構即可。從上圖可以看出,一個{}中包含了若干個鍵值對,大括弧中的內容就被稱為一條文檔。
MongoDB的文檔存儲結構
MongoDB 文檔資料庫的存儲結構分為四個層次,從小到大依次是:鍵值對、文檔(document)、集合(collection)、資料庫(database)。
圖 1 描述了 MongoDB 的存儲與 MySQL 存儲的對應關係,可以看出,MongoDB中的文檔、集合、資料庫對應於關係資料庫中的行數據、表、資料庫。

圖 1:MongoDB 存儲與 Mysql 存儲的對比
鍵值對
文檔資料庫存儲結構的基本單位是鍵值對,具體包含數據和類型。鍵值對的數據包含鍵和值,鍵的格式一般為字元串,值的格式可以包含字元串、數值、數組、文檔等類型。
按照鍵值對的複雜程度,可以將鍵值對分為基本鍵值對和嵌套鍵值對。
- 圖 2 中的鍵值對中的鍵為字元串,值為基本類型,這種鍵值對就稱為基本鍵值。
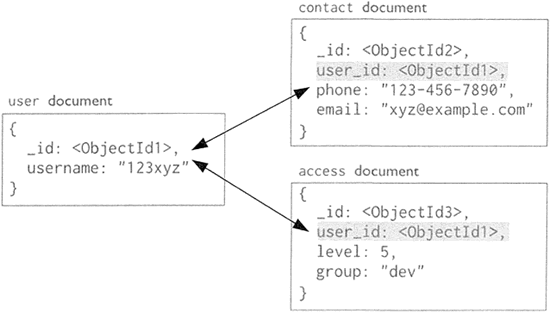
- 嵌套鍵值對類型如圖 3 所示,從圖中可以看岀, contact 的鍵對應的值為一個文檔,文檔中又包含了相關的鍵值對,這種類型的鍵值對稱為嵌套鍵值對。
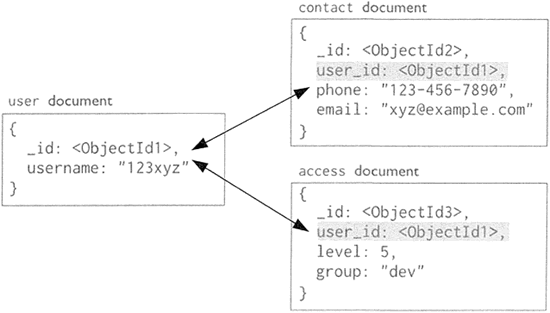
圖 2:MongoDB 文檔數據模型

圖 3:嵌套鍵值對
鍵(Key)起唯一索引的作用,確保一個鍵值結構里數據記錄的唯一性,同時也具有資訊記錄的作用。例如,country:”China”,用:實現了對一條地址的分割記錄,「country」起到了 「China」的唯一地址作用,另外,「country」作為鍵的內容說明了所對應內容的一些資訊。
值(Value)是鍵所對應的數據,其內容通過鍵來獲取,可存儲任何類型的數據,甚至可以為空。
鍵和值的組成就構成了鍵值對(Key-Value Pair)。它們之間的關係是一一對應的,如定義了 「country:China」鍵值對,”country」就只能對應「China」,而不能對應「USA」。
文檔中鍵的命名規則如下。
- UTF-8 格式字元串。
- 不用有
\0的字元串,習慣上不用.和$。 - 以開頭的多為保留鍵,自定義時一般不以開頭。
- 文檔鍵值對是有序的,MongoDB 中嚴格區分大小寫。
文檔
文檔是 MongoDB 的核心概念,是數據的基本單元,與關係資料庫中的行十分類似,但是比行要複雜。文檔是一組有序的鍵值對集合。文檔的數據結構與 JSON 基本相同,所有存儲在集合中的數據都是 BSON 格式。
BSON 是一種類 JSON 的二進位存儲格式,是 Binary JSON 的簡稱。 一個簡單的文檔例子如下:
{"country" : "China", "city": "BeiJing"}
MongoDB 中的數據具有靈活的架構,集合不強制要求文檔結構。但數據建模的不同可能會影響程式性能和資料庫容量。文檔之間的關係是數據建模需要考慮的重要因素。文檔與文檔之間 的關係包括嵌入和引用兩種。
下面舉一個關於顧客 patron 和地址 address 之間的例子,來說明在某些情況下,嵌入優於引用。
{
_id: "joe",
name: "Joe Bookreader"
}
{
patron_id: "joe",
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "2345"
}
關係資料庫的數據模型在設計時,將 patron 和 address 分到兩個表中,在查詢時進行關聯, 這就是引用的使用方式。如果在實際查詢中,需要頻繁地通過 _id 獲得 address 資訊,那麼就需要頻繁地通過關聯引用來返回查詢結果。在這種情況下,一個更合適的數據模型就是嵌入。
將 address 資訊嵌入 patron 資訊中,這樣通過一次查詢就可獲得完整的 patron 和 address 資訊,如下所示:
{
_id: "joe",
name: "Joe Bookreader",
address: {
street: "123 Fake Street",
city: "Faketon」,
state: nMAnz
zip: T2345」
}
}
如果具有多個 address,可以將其嵌入 patron 中,通過一次查詢就可獲得完整的 patron 和多個 address 資訊,如下所示:
{
_id: "joe",
name: "Joe Bookreader",
addresses:[
{
street: "123 Fake Streetn,
city: "Faketon",
state: "MA",
zip: "12345"
},
{
street: "l Some Other Street",
city: "Boston",
state: "MA",
zip: "12345"
}
]
}
但在某種情況下,引用比嵌入更有優勢。下面舉一個圖書出版商與圖書資訊的例子,程式碼如下:
{
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolfn"],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher: {
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
}
{
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher: {
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
}
從上邊例子可以看出,嵌入式的關係導致出版商的資訊重複發布,這時可採用引用的方式描述集合之間的關係。使用引用時,關係的增長速度決定了引用的存儲位置。如果每個出版商的圖書數量很少且增長有限,那麼將圖書資訊存儲在出版商文檔中是可行的。
通過 books 存儲每本圖書的 id 資訊,就可以查詢到指定圖書出版商的指定圖書資訊,但如果圖書出版商的圖書數量很多, 則此數據模型將導致可變的、不斷增長的數組 books,如下所示:
{
name: "O'Reilly Media",
founded: 1980,
location: "CA",
books: [123456789, 234567890, …]
}
{
_id: 123456789,
title: "MongoDE: The Definitive Guide",
author: ["Kristina Chodorow", "Mike Dirolf"],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English"
}
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English"
}
為了避免可變的、不斷增長的數組,可以將出版商引用存放到圖書文檔中,如下所示:
{
_id: "oreilly",
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
{
_id: 123456789,
title: "MongoDB: The Definitive Guiden,
author: [ "Kristina Chodorow", "Mike Dirolf"],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher_id: "oreilly"
}
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher_id: "oreilly"
}
集合
MongoDB 將文檔存儲在集合中,一個集合是一些文檔構成的對象。如果說 MongoDB 中的文檔類似於關係型資料庫中的「行」,那麼集合就如同「表」。
集合存在於資料庫中,沒有固定的結構,這意味著用戶對集合可以插入不同格式和類型的數據。但通常情況下插入集合的數據都會有一定的關聯性,即一個集合中的文檔應該具有相關性。
集合的結構如圖 4 所示。

圖 4:文檔資料庫中的一個集合
資料庫
在 MongoDB 中,資料庫由集合組成。一個 MongoDB 實例可承載多個資料庫,互相之間彼此獨立,在開發過程中,通常將一個應用的所有數據存儲到同一個資料庫中,MongoDB 將不同資料庫存放在不同文件中。
資料庫結構示例如圖 5 所示。
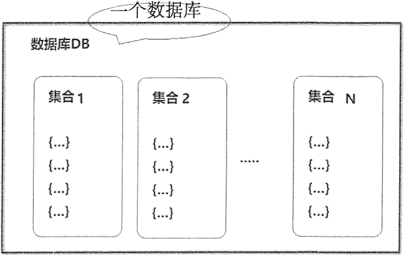
圖 5:一個名為 DB 的資料庫的結構
BSON對JSON做了哪些改進?
我們說,MongoDB 存儲的數據格式與 JSON 十分類似,MongoDB 所採用的數據格式被稱為 BSON,是一種基於 JSON 的二進位序列化格式,用於 MongoDB 存儲文檔並進行遠程過程調用。
JSON 是一種網路常用的數據格式,具有自描述性。JSON 的數據表示方式易於解析,但支援的數據類型有限。BSON 目前主要用於 MongoDB 中,選擇 JSON 進行改造的原因主要是 JSON 的通用性及 JSON 的 schemaless 的特性。
BSON 改進的主要特性有下面三點。
更快的遍歷速度
BSON 對 JSON 的一個主要的改進是,在 BSON 元素的頭部有一個區域用來存儲元素的長度, 當遍歷時,如果想跳過某個文檔進行讀取,就可以先讀取存儲在 BSON 元素頭部的元素的長度, 直接 seek 到指定的點上就完成了文檔的跳過。
在 JSON 中,要跳過一個文檔進行數據讀取,需要在對此文檔進行掃描的同時匹配數據結構才可以完成跳過操作。
操作更簡易
如果要修改 JSON 中的一個值,如將 9 修改為 10,這實際是將一個字元變成了兩個,會導致其後面的所有內容都向後移一位。
在 BSON 中,可以指定這個列為整型,那麼,當將 9 修正為 10 時,只是在整型範圍內將數字進行修改,數據總長不會變化。
需要注意的是:如果數字從整型增大到長整型,還是會導致數據總長增加。
支援更多的數據類型
BSON 在 JSON 的基礎上增加了很多額外的類型,BSON 增加了「byte array」數據類型。這使得二進位的存儲不再需要先進行 base64 轉換再存為 JSON,減少了計算開銷。
BSON 支援的數據類型如表所示。
| 類型 | 描述示例 |
|---|---|
| NULL | 表示空值或者不存在的欄位,{“x” : null} |
| Boolean | 布爾型有 true 和 false,{“x” : true} |
| Number | 數值:客戶端默認使用 64 位浮點型數值。{“x” : 3.14} 或 {“x” : 3}。對於整型值,包括 NumberInt(4 位元組符號整數)或 NumberLong(8 位元組符號整數),用戶可以指定數值類型,{“x” : NumberInt(“3”)} |
| String | 字元串:BSON 字元串是 UTF-8,{“x” : “中文”} |
| Regular Expression | 正則表達式:語法與 JavaScript 的正則表達式相同,{“x” : /[cba]/} |
| Array | 數組:使用「[]」表示,{“x” : [“a”, “b”, “c”]} |
| Object | 內嵌文檔:文檔的值是嵌套文檔,{“a” : {“b” : 3}} |
| ObjectId | 對象 id:對象 id 是一個 12 位元組的字元串,是文檔的唯一標識,{“x” : objectId()} |
| BinaryData | 二進位數據:二進位數據是一個任意位元組的字元串。它不能直接在 Shell 中使用。如果要將非 UTF-8 字元保存到資料庫中,二進位數據是唯一的方式 |
| JavaScript | 程式碼:查詢和文檔中可以包括任何 JavaScript 程式碼,{“x” : function(){/…/}} |
| Data | 日期:{“x” : new Date()} |
| Timestamp | 時間戳:var a = new Timestamp() |


