正則表達式斷言精講 Java語法實現
斷言
本文目的是講解正則表達式之斷言用法。目前互聯網上有很多博文對斷言講解的並不透徹,如果您剛開始學習斷言,相信此博文會對您有幫助。
本文謝絕轉載,此文屬原創文章,如有雷同,不勝榮幸。
//cloud.tencent.com/developer/article/1149481
//www.aqee.net/post/regular-expression-to-match-string-not-containing-a-word.html
1.2.3.1 情景導入
假設,我要獲得一個字元串裡面所有以空格開頭的英文詞語。
//檢測由空格開始的辭彙
Pattern pattern4 = Pattern.compile("\\s(?i)\\w+");
Matcher matcher3 = pattern4.matcher(" hello world");
while (matcher3.find()) {
String group = matcher3.group();
//可以用下面這種方法去除空格
System.out.println("group.trim() = " + group.trim());
// group.trim() = hello
// group.trim() = world
}
在使用上面的程式碼過程中存在一些問題,我獲得的單詞默認是前頭帶空格的,縱然我可以通過String類的trim來解決這些問題,可是這樣用起來會很麻煩,有沒有一種正則表達式的規則可以檢測那些開頭帶空格的辭彙但是適配到的辭彙不帶空格呢?答案是有的,那就是斷言
什麼是斷言
在使用正則表達式時,有時我們需要捕獲的內容前後必須是特定內容,但又不捕獲這些特定內容的時候,零寬斷言就起到作用了。
斷言全稱為零寬斷言
斷言的語法規則
(?=X)X, via zero-width positive lookahead 零寬前行正向斷言 (?!X)X, via zero-width negative lookahead 零寬前行負向斷言 (?<=X)X, via zero-width positive lookbehind 零寬後行正向斷言 (?<!X)X, via zero-width negative lookbehind 零寬後行負向斷言
零寬斷言為什麼叫零寬斷言
理解這一點至關重要,拿零寬前行正向斷言來舉例
零寬
零寬的含義為斷言部分不佔據寬度,舉個例子12(?=la)匹配12la匹配到的是12,含義是la前面的12。12la匹配12la匹配到的是12la,含義為匹配value為12la的字元串。不知道通過這個例子你能否看懂零寬的意義,不懂也沒關係,看完接下來幾章就會懂了。
前行
前行的含義我可以確定我說的是正確的,現在互聯網上好多人對前行的理解是錯誤的,雖然按照他們的解釋是可以解釋的通大多數情況,但是我們還是要抱著實事求是的態度,還原前行真正的含義,參考網站:正則表達式零寬斷言詳解(?=,?<=,?!,?<!),Regular expression to match a line that doesn’t contain a word。
在正則表達式中,每個字元串都是有定位的,所謂定位,就是確定字元串中每個字元位置的數字,這個只可意會,我給您看幾張圖,通過圖片,或許可以理解
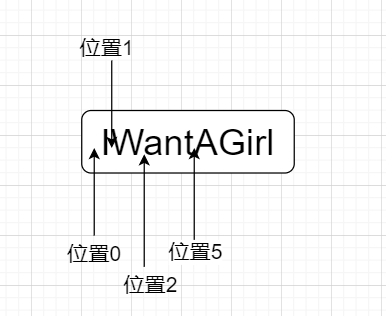
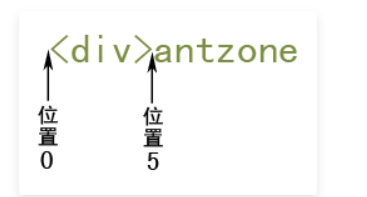
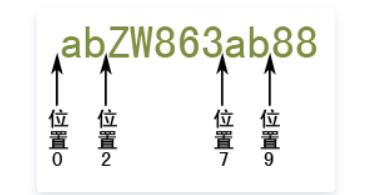
看到沒有,字元串每一個字元間隔就是一個個位置點,字元串第一個字元前為位置0,字元串第一個字元和第二個字元之間為位置1,字元串第一個字元位於位置0和位置1之間,以此類推……
前行的意義為位置之前,後行的意義為位置之後
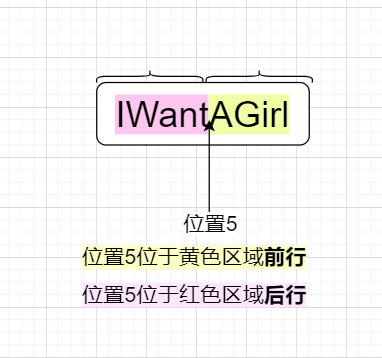
如上圖,位置5位於紅色區域後行,位置5位於黃色區域前行
那麼,在斷言中前行和後行代表著什麼呢?
比如說正則表達式12(?=la)在匹配字元串qwew12bb12la的時候,他會先,匹配到從左往右第一個12,如下圖所示👇
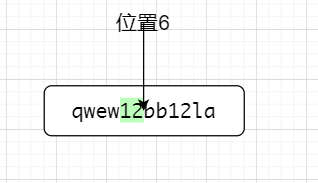
因為(?=x)是前行匹配,這個時候12是佔位置的,位置點走到了第一個12的後面,即位置6,👆。因為是零寬,(?=la)不佔位置,接下來以位置6為前行,匹配位置6的後面,位置6的後面不是la,故不匹配位置6前面的12,接下來位置轉到了第二個12後面,如下圖所示👇
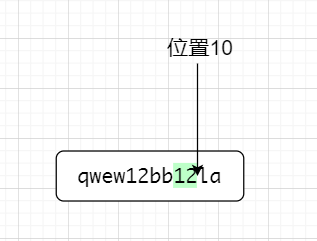
因為是前行匹配,位置10作為前行,匹配後面的字元,後面是la符合要求,因為零寬,匹配到的最終字元不包括零寬,如下圖所示

不懂也沒關係,看完接下來幾章就會懂了。
負向
所謂負向,不符合為負向,如(?<!x)就是負向,該斷言匹配的是不符合x標準的字元串作為目標字元串的後行
再來熟悉一下幾個斷言
(?=X)X, via zero-width positive lookahead 零寬前行正向斷言 (?!X)X, via zero-width negative lookahead 零寬前行負向斷言 (?<=X)X, via zero-width positive lookbehind 零寬後行正向斷言 (?<!X)X, via zero-width negative lookbehind 零寬後行負向斷言
斷言DEMO
-
後行正向斷言,該斷言匹配前面是aa的字元
//後行正向斷言 Pattern compile = Pattern.compile("(?<=aa)\\w+"); Matcher matcher = compile.matcher(" aadfds fdgs daafs"); while (matcher.find()) { System.out.println(matcher.group());//dfds }👆運行結果為👇
dfds fs -
後行負向斷言,該斷言匹配的是前面不是$的數字
Pattern compile1 = Pattern.compile("(?<!\\$|\\d)\\d+"); Matcher matcher1 = compile1.matcher("$14 23");//23 while (matcher1.find()) { System.out.println("matcher1.group() = " + matcher1.group()); }👆運行結果為👇
matcher1.group() = 23我來解釋一下,正則表達式
(?<!\\$|\\d)\\d+,斷言的意思是不匹配前面為$或數字的數字。模擬一下匹配的過程,也許會更加明白是怎麼一回事兒,先說一下”$14 23″,位置我就不在圖中標了,自己數一下吧👇
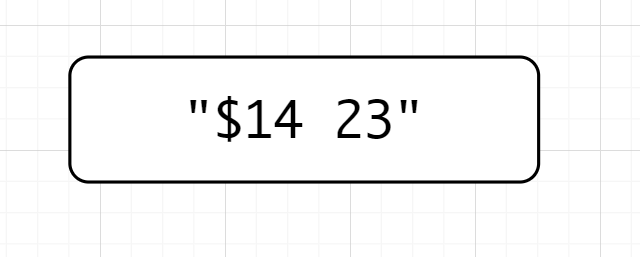
(?<!\\$|\\d)\\d+先匹配數字,匹配到了1,位置是1,因為斷言是不佔寬度的。因為是後行,檢測到左邊是\(,不符合斷言要求,就來到了位置2(1和4之間),位置二前面是數字不符合要求,類推,位置來到了2的前面,前面是空格,既不是數字也不是\),符合要求,故匹配23 -
先行正向斷言
Matcher matcher2 = Pattern.compile("(?i)windows(?=2000|xp|10)").matcher("windowsXp"); while (matcher2.find()) { System.out.println("matcher2.group() = " + matcher2.group()); }運行結果是👇
matcher2.group() = windows我來稍微解釋一下,
"(?i)windows(?=2000|xp|10)"(?i)表明不區分大小寫,Windows表明適配windows,(?=2000|xp|10)表明是零寬先行正向斷言。我說一下匹配的過程,首先匹配windows,位置來到了windows後,零寬先行,後面是xp適配成功。 -
先行負向斷言
Matcher matcher3 = Pattern.compile("(?i)Linux(?!12.3)").matcher("linux12."); while (matcher3.find()) { System.out.println("matcher3.group() = " + matcher3.group()); }運行結果是👇
matcher3.group() = linux這個就不解釋了,自行理解吧
以上四個demo是最最基礎的demo,在很多教程上對斷言的講解止步於此(實際上,很短教程連最基本的匹配過程都沒講,只講了匹配的結果,這個要出大問題的),務須掌握好上面的四個demo。
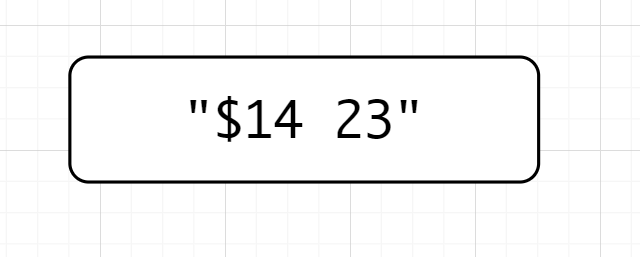
斷言的基礎應用和實際用處
放一張思維導圖
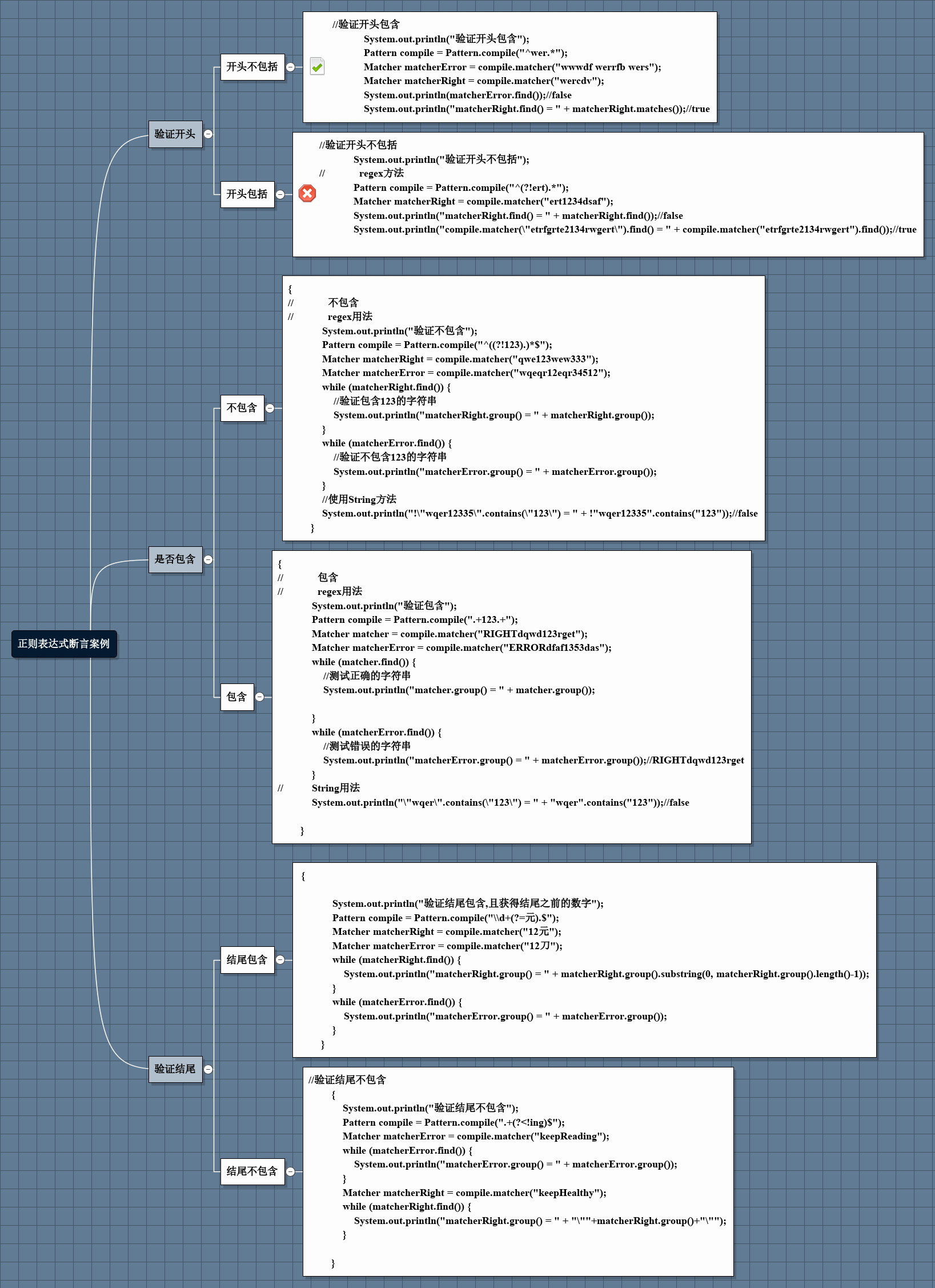
這個我先說一下結論,在實際應用開發中,在應用諸如驗證開頭或結尾(只要求一行的開頭或結尾)的實踐中,大概有兩種,一種是零寬,一種是非零寬。所謂零寬即匹配的數據不包括斷言,非零寬反之,在某些情況下需要藉助String方法的subString()方法。
一般情況下,使用斷言,主要是用它零寬的屬性,驗證開頭包含,結尾包含時一般不用斷言,分組就能解決問題,當開頭不包含或結尾不包含等問題時,使用斷言是很好的辦法。
演示三個👇
驗證不包含
/*
不包含
*/
{
// 不包含
// regex用法
System.out.println("驗證不包含");
Pattern compile = Pattern.compile("^((?!123).)*$");
Matcher matcherRight = compile.matcher("qwe123wew333");
Matcher matcherError = compile.matcher("wqeqr12eqr34512");
while (matcherRight.find()) {
//驗證包含123的字元串
System.out.println("matcherRight.group() = " + matcherRight.group());
}
while (matcherError.find()) {
//驗證不包含123的字元串
System.out.println("matcherError.group() = " + matcherError.group());//matcherError.group() = wqeqr12eqr34512
}
//使用String方法
System.out.println("!\"wqer12335\".contains(\"123\") = " + !"wqer12335".contains("123"));//!"wqer12335".contains("123") = false
}
運行結果如下👇
驗證不包含
matcherError.group() = wqeqr12eqr34512
!"wqer12335".contains("123") = false
解析:正則表達式里字元串”不包含”匹配技巧 | 外刊IT評論
驗證開頭包含
一行字元串,驗證開頭是否包含某字元串,若包含則輸出匹配到的數據,此方法會包括斷言。也就是說假如驗證「123erre」的開頭是否是123,匹配到的數據為123erre而不是erre。驗證開頭包含且匹配數據不包括斷言請看下一章
{
System.out.println("驗證開頭包含");
Pattern compile = Pattern.compile("^(?=wer).*");
Matcher matcherError = compile.matcher("wwwdf werrfb wers");
Matcher matcherRight = compile.matcher("wercdv");
System.out.println(matcherError.find());//false
// System.out.println("matcherRight.find() = " + matcherRight.find());//true
while (matcherRight.find()) {
System.out.println("matcherRight.group() = " + matcherRight.group());//wercdv
}
}
結果如下👇
驗證開頭包含
false
matcherRight.group() = wercdv
解析:
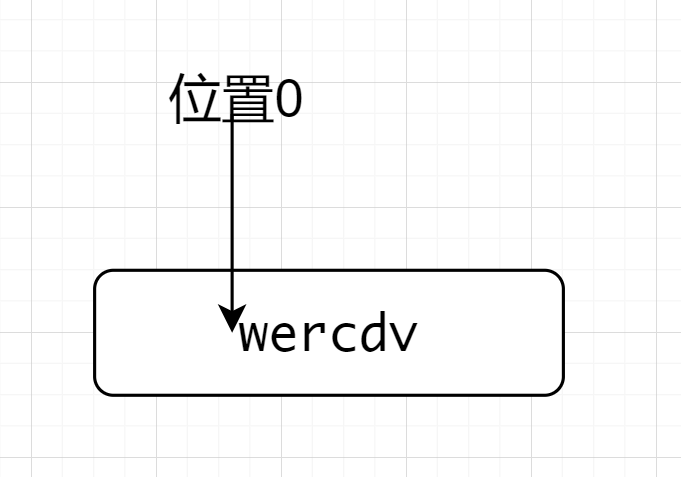
^(?=wer).*匹配wercdv的時候,先因為^來到了位置0,位置0後面是符合.*的,遂開始匹配斷言,注意這時候位置依然在位置0,因為是先行斷言,位置0後面是wer符合斷言要求,故匹配到了wercdv
驗證開頭包含且匹配到的數據不包括斷言
假如說要匹配開頭是wer的字元串,字元串是wercdv,匹配到的是cdv而不是wercdv
{
System.out.println("驗證開頭包含,匹配到的數據不包括斷言");
Pattern compile = Pattern.compile("^wer(?<=wer)(.*)");
Matcher matcherError = compile.matcher("wwwdf werrfb wers");
Matcher matcherRight = compile.matcher("wercdv");
System.out.println(matcherError.find());//false
while (matcherRight.find()) {
System.out.println("matcherRight.start() = " + matcherRight.start());//0
System.out.println("matcherRight.end() = " + matcherRight.end());//6
System.out.println("matcherRight.group() = " + matcherRight.group(1));//cdv
}
}
結果如下👇
驗證開頭包含,匹配到的數據不包括斷言
false
matcherRight.start() = 0
matcherRight.end() = 6
matcherRight.group() = cdv
解析:
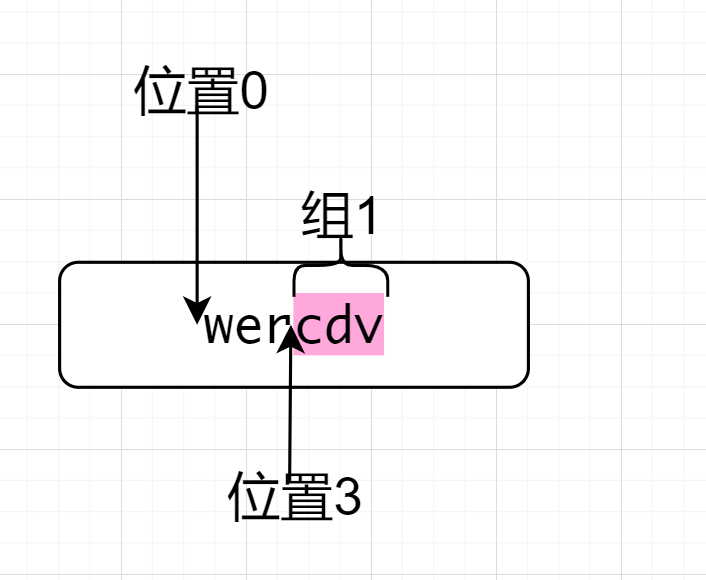
^wer(?<=wer)(.*)因為^所以先來到了位置0,然後匹配wer,來到了位置3,位置3後面符合.*的要求,因為後行匹配,前面是wer,符合要求,在取出的過程中,有一個分組,選取的是.*故最終取出cdv
驗證結尾包含,且匹配到的數據不包括斷言
舉個例子,匹配以「元」結尾的辭彙,且匹配到的數據不包括「元」,譬如「12元」,匹配到的數據是12。
//驗證結尾包含
{
System.out.println("驗證結尾包含,且獲得結尾之前的數字");
Pattern compile = Pattern.compile("(\\d+)(?=元).$");
Matcher matcherRight = compile.matcher("12元");
Matcher matcherError = compile.matcher("12刀");
while (matcherRight.find()) {
System.out.println("matcherRight.group(1) = " + matcherRight.group(1));//12
}
while (matcherError.find()) {
System.out.println("matcherError.group() = " + matcherError.group());
}
}
運行結果是👇
驗證結尾包含,且獲得結尾之前的數字
matcherRight.group(1) = 12
解析:
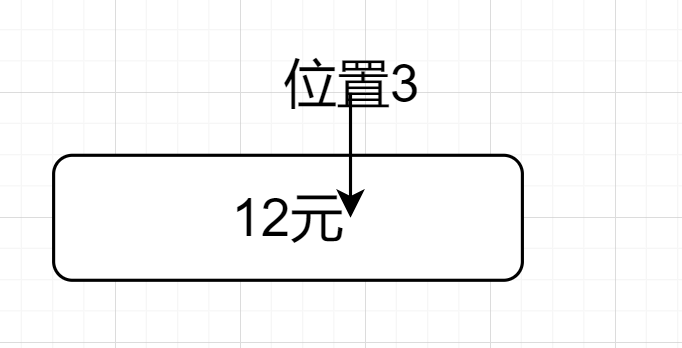
(\\d+)(?=元).$因為$先來到位置3,如圖所示👇
然後因為(\\d+)(?=元).$的.,位置向前一步,來到了位置2,然後前行斷言,位置2的後面是元,前面是數字元合要求,如下圖所示👇
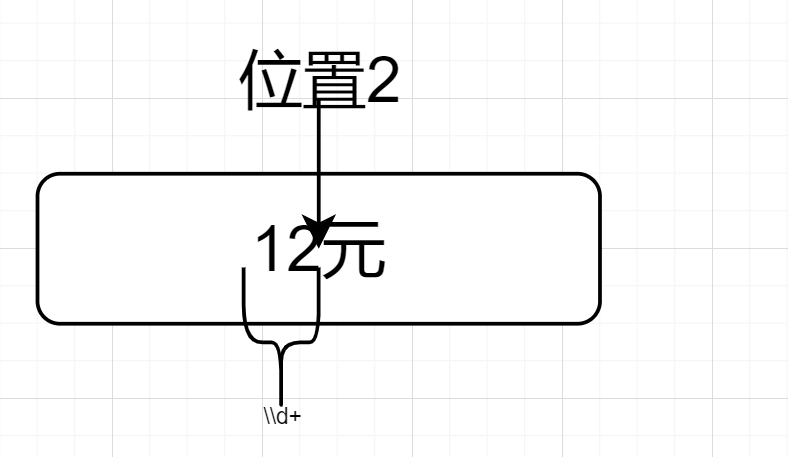
匹配到了「12元」,因為輸出組①,故最終輸出12。
斷言基礎應用總體程式碼
程式碼文件👇,運行結果寫在了注釋裡面
/**
* 基礎正則表達式實例
*/
@Test
public void testRegexOne() {
System.out.println(
"{\"name\": \"正則表達式相關斷言有關的demo\",\n" +
" " +
"\"個數\": 2" +
"}");
/*
包含
*/
{
// 包含
// regex用法
System.out.println("驗證包含");
Pattern compile = Pattern.compile(".+123.+");
Matcher matcher = compile.matcher("RIGHTdqwd123rget");
Matcher matcherError = compile.matcher("ERRORdfaf1353das");
while (matcher.find()) {
//測試正確的字元串
System.out.println("matcher.group() = " + matcher.group());
}
while (matcherError.find()) {
//測試錯誤的字元串
System.out.println("matcherError.group() = " + matcherError.group());//RIGHTdqwd123rget
}
// String用法
System.out.println("\"wqer\".contains(\"123\") = " + "wqer".contains("123"));//false
}
/*
不包含
*/
{
// 不包含
// regex用法
System.out.println("驗證不包含");
Pattern compile = Pattern.compile("^((?!123).)*$");
Matcher matcherRight = compile.matcher("qwe123wew333");
Matcher matcherError = compile.matcher("wqeqr12eqr34512");
while (matcherRight.find()) {
//驗證包含123的字元串
System.out.println("matcherRight.group() = " + matcherRight.group());
}
while (matcherError.find()) {
//驗證不包含123的字元串
System.out.println("matcherError.group() = " + matcherError.group());//matcherError.group() = wqeqr12eqr34512
}
//使用String方法
System.out.println("!\"wqer12335\".contains(\"123\") = " + !"wqer12335".contains("123"));//!"wqer12335".contains("123") = false
}
/*
驗證開頭
*/
//驗證開頭不包含
{
//驗證開頭不包括
System.out.println("驗證開頭不包括");
// regex方法
Pattern compile = Pattern.compile("^(?!ert).*");
Matcher matcherRight = compile.matcher("ert1234dsaf");
// System.out.println("matcherRight.find() = " + matcherRight.find());//false
while (matcherRight.find()) {
System.out.println("matcherRight.group() = " + matcherRight.group());
}
// System.out.println("compile.matcher(\"etrfgrte2134rwgert\").find() = " + compile.matcher("etrfgrte2134rwgert").find());//true
Matcher matcherError = compile.matcher("etrfgrte2134rwgert");
while (matcherError.find()) {
System.out.println("matcherError.group() = " + matcherError.group());//etrfgrte2134rwgert
}
}
{
System.out.println("驗證開頭包含");
Pattern compile = Pattern.compile("^(?=wer).*");
Matcher matcherError = compile.matcher("wwwdf werrfb wers");
Matcher matcherRight = compile.matcher("wercdv");
System.out.println(matcherError.find());//false
// System.out.println("matcherRight.find() = " + matcherRight.find());//true
while (matcherRight.find()) {
System.out.println("matcherRight.group() = " + matcherRight.group());//wercdv
}
}
//驗證開頭包含
{
System.out.println("驗證開頭包含,匹配到的數據不包括斷言");
Pattern compile = Pattern.compile("^wer(?<=wer)(.*)");
Matcher matcherError = compile.matcher("wwwdf werrfb wers");
Matcher matcherRight = compile.matcher("wercdv");
System.out.println(matcherError.find());//false
while (matcherRight.find()) {
System.out.println("matcherRight.start() = " + matcherRight.start());//0
System.out.println("matcherRight.end() = " + matcherRight.end());//6
System.out.println("matcherRight.group() = " + matcherRight.group(1));//cdv
}
}
//驗證結尾不包含
{
System.out.println("驗證結尾不包含");
Pattern compile = Pattern.compile(".+(?<!ing)$");
Matcher matcherError = compile.matcher("keepReading");
while (matcherError.find()) {
System.out.println("matcherError.group() = " + matcherError.group());
}
Matcher matcherRight = compile.matcher("keepHealthy");
while (matcherRight.find()) {
System.out.println("matcherRight.group() = " + "\""+matcherRight.group()+"\"");//"keepHealthy"
}
}
//驗證結尾包含
{
System.out.println("驗證結尾包含,且獲得結尾之前的數字");
Pattern compile = Pattern.compile("(\\d+)(?=元).$");
Matcher matcherRight = compile.matcher("12元");
Matcher matcherError = compile.matcher("12刀");
while (matcherRight.find()) {
System.out.println("matcherRight.group(1) = " + matcherRight.group(1));//12
}
while (matcherError.find()) {
System.out.println("matcherError.group() = " + matcherError.group());
}
}
}
不按套路出牌,幫你徹底理解斷言
一般情況下,使用斷言,主要是用它零寬的屬性,向驗證開頭包含,結尾包含時一般不用斷言,分組就能解決問題,當開頭不包含或結尾不包含等問題時,使用斷言是很好的辦法。
@Test
public void testOther(){
System.out.println("不按套路來,幫您徹底理解斷言");
Pattern compile = Pattern.compile("(?=re)\\w+");
Matcher matcher = compile.matcher("reading a book");
System.out.println("不按套路來的零寬先行正向斷言");
while (matcher.find()) {
System.out.println("matcher.group() = " + matcher.group());//matcher.group() = reading
}
System.out.println("不按套路來的零寬後行正向斷言");
Pattern compile1 = Pattern.compile("\\w+(?i)(?<=re)");
Matcher matcher1 = compile1.matcher("i want toReading a book");
while (matcher1.find()) {
System.out.println("matcher1.group() = " + matcher1.group());//matcher1.group() = toRe
}
System.out.println("不按套路來的零寬先行負向斷言");
Pattern compile2 = Pattern.compile("(?i)ing(?!re)\\w+");
Matcher matcher2 = compile2.matcher("i am LovingReading a book and HatingBuy a book");
while (matcher2.find()) {
System.out.println("matcher2.group() = " + matcher2.group());//matcher2.group() = ingBuy
}
System.out.println("不按套路來的零寬後行負向斷言");
Pattern compile3 = Pattern.compile("(?i)\\w+(?<!re)a");
Matcher matcher3 = compile3.matcher("llrea lla");
while (matcher3.find()) {
System.out.println("matcher3.group() = " + matcher3.group());//matcher3.group() = lla
}
}
絕大多數網站在講解斷言問題的時候總是去引用斷言demo一章裡面那四個例子,這會給人造成一種「前行斷言適配結尾,後行斷言適配開頭」的錯覺,事實上並不是這個樣子,重要的是要具體問題具體分析。如同上面的程式碼,不按所謂常理出牌,有助於正則表達式之理解。
上面取了四個例子,皆不按套路來,為方便理解,選一個細講
System.out.println("不按套路來的零寬後行負向斷言");
Pattern compile3 = Pattern.compile("(?i)\\w+(?<!re)a");
Matcher matcher3 = compile3.matcher("llrea lla");
while (matcher3.find()) {
System.out.println("matcher3.group() = " + matcher3.group());//matcher3.group() = lla
}
運行結果👇
不按套路來的零寬後行負向斷言
matcher3.group() = lla
(?i)\\w+(?<!re)a的本意是不區分大小寫地去適配結尾是a且a的前面不是re的字元。(?!)是不區分大小寫的意思。正則發揮作用時,先找到a,位置來到a的前面,因為後行斷言,位置的前面不能是re。因為\\w+,a的前面需要是字母或數字。綜合看來,意思是a的前面是除re之外的字母或數字。
如果真的不理解,就死記下面的實例
-
不包含a
Pattern compile = Pattern.compile("^((?!a).)*$"); Matcher matcher = compile.matcher("ssdas"); System.out.println("matcher.find() = " + matcher.find());//matcher.find() = false -
開頭不包含a
Pattern compile1 = Pattern.compile("^(?!a).*"); Matcher matcher1 = compile1.matcher("basa"); System.out.println("matcher1.find() = " + matcher1.find());//matcher1.find() = true -
結尾不包含a
Pattern compile2 = Pattern.compile("\\w*(?<!a)$"); Matcher matcher2 = compile2.matcher("qwerdsa"); System.out.println("matcher2.find() = " + matcher2.find());//matcher2.find() = false -
包含a且不包含b
Pattern compile3 = Pattern.compile("^((?!b).)*a((?!b).)*$"); Matcher matcher3 = compile3.matcher("qwbera"); System.out.println("matcher3.find() = " + matcher3.find());//matcher3.find() = false -
處於a和b之間
Pattern compile4 = Pattern.compile("^.(?<=a)(.*)(?=b).$"); Matcher matcher4 = compile4.matcher("asdbdb"); System.out.println("matcher4.find() = " + matcher4.find());//matcher4.find() = true System.out.println("matcher4.group() = " + matcher4.group(1));//matcher4.group() = sdbd -
適配字元串中所有不以b結尾的數字
Pattern compile5 = Pattern.compile("\\d+(?!b|\\d+)"); Matcher matcher5 = compile5.matcher("1b 123b 123 45"); System.out.println("matcher5.find() = " + matcher5.find());//matcher5.find() = true System.out.println("matcher5.group() = " + matcher5.group());//matcher5.group() = 123 matcher5.find(); System.out.println("matcher5.group() = " + matcher5.group());//matcher5.group() = 45 -
適配字元串中所有以a開頭的數字
Pattern compile6 = Pattern.compile("(?<=a)\\d+"); Matcher matcher6 = compile6.matcher("123 123 a231 a34 45a a23"); while (matcher6.find()) { System.out.println("matcher6.group() = " + matcher6.group()); //matcher6.group() = 231 //matcher6.group() = 34 //matcher6.group() = 23 }
在某些時候亦可以用\b來實現某些可以用斷言實現的正則表達,舉個例子👇
獲取所有以b結尾的數字
Pattern compile7 = Pattern.compile("(\\d+)b\\b");
Matcher matcher7 = compile7.matcher("1b 123b 123 45");
while (matcher7.find()) {
System.out.println("matcher7.group() = " + matcher7.group(1));
// matcher7.group() = 1
// matcher7.group() = 123
}


