Apache Tika實戰
- 2020 年 8 月 30 日
- 筆記
- Apache Tika, FAST2020
Apache Tika實戰
Tika 簡介
Apache Tika 是一個內容分析工具包,可以檢測上千種文件類型,並提取它們的元數據和文本。tika在設計上十分精巧,單一的介面使它易於使用,在搜索引擎索引,內容分析,翻譯等諸多方面得到了廣泛使用。
Apache Tika曾經是Apache Lucene的一個子項目,現已成為Apache頂級項目。
Tika的特點
- 支援上千種不同的文件類型
- 提供了多種實用工具,如tika-app, tika-server等
- 除了Java,還提供了其他程式語言的調用,如Julia,Python
- 擴展性很好,支援自定義文件類型和解析器
Tika的組成
tika的核心是一個類庫,提供了文件類型檢測,內容語言檢測等功能,並有一個完整的解析器框架,通過這個框架集成了許多Java平台上流行的文件分析工具,如針對壓縮格式,使用了commons-compress,針對微軟Office文檔,使用了Apache POI,針對Adobe PDF格式,採用了Apache PDFbox
tika-core && tika-parsers
tika-core是tika的核心,提供了文件類型檢測,語言檢測,以及解析器框架。
tika-core並不包含具體的解析器,而是提供了一個api,實際的解析器實現放在tika-parsers中。
tika-parsers具有非常的傳遞依賴,使用時應該注意和項目已有依賴的衝突問題
tika-app
tika-app包含了tika核心類庫和它的相關依賴,提供了命令行工具和圖形用戶介面,可以在腳本中使用,並支援管道。
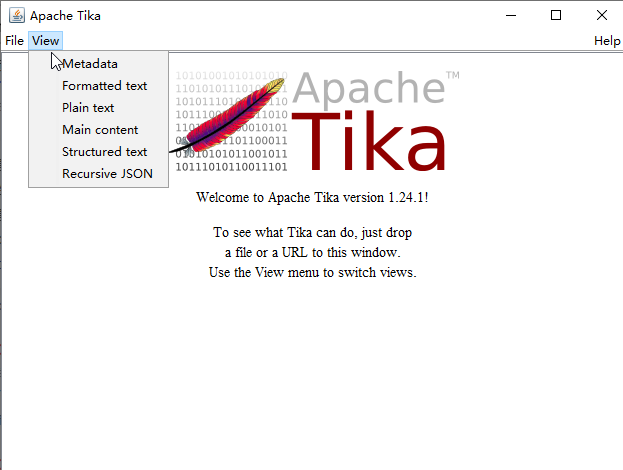
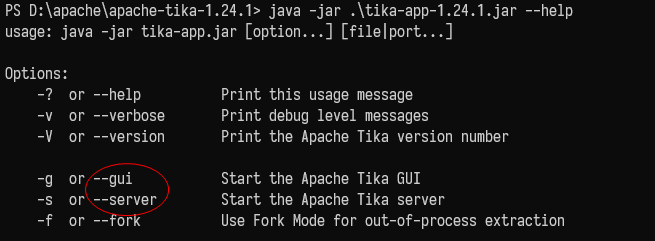
tika-server
一個restful服務,方便和現有應用系統集成
$ curl -X PUT --data-binary @GeoSPARQL.pdf //localhost:9998/tika --header "Content-type: application/pdf"
$ curl -T price.xls //localhost:9998/tika --header "Accept: text/html"
tika-bundle
一個OSGi bundle,方便和基於OSGi的應用系統集成
OSGi: 開放服務網關協議,支援模組的動態載入,熱拔插,可以在不停機的情況下,讓應用程式載入新的模組,並提供新的服務
tika-eval
一個命令行工具,可以批量解析文件,然後把結果保存到資料庫,支援多種類型的資料庫,如h2,mysql……
默認資料庫為h2,使用其他類型的資料庫需要在啟動時將相關的依賴放到classpath下
感覺是為Lucene準備的,提取文件內容後,保存到資料庫,然後再由索引器進行索引,最後對外提供搜索服務
tika設計&實現
tika的核心功能是文件內容分析,這裡分析主要有兩個含義,一是提取文件的元數據(Metadata),包括文件類型,版本,作者,編輯工具,壓縮演算法等;二是解析文件得到文本內容(Text),這裡的文本是指在相應的閱覽軟體中打開文件時看到的內容。
為了實現上述目標,tika設計了一個擴展性極強的框架,主要包括文件類型檢測和內容解析兩個部分。首先判斷文件類型(Detector),再根據文件類型選用適當的解析器(Parser),解析結果保存在Metadata和ContentHandler中,我們可以通過自定義ContentHandler來得到想要的資訊。
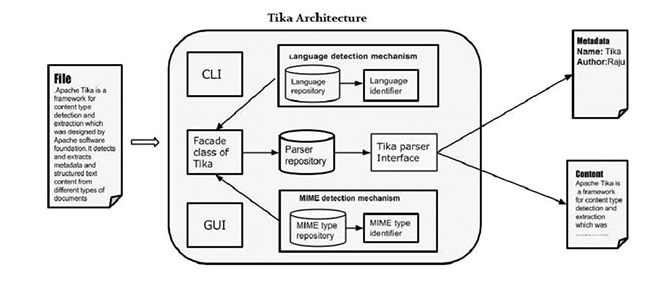
文件類型檢測
文件類型檢測是處理文件的第一個步驟,在大部分情況下,我們可以根據文件名簡單判斷出文件的類型,這樣處理的效率很高,但是結果並不精準(因為文件名可以輕鬆偽造),因此Tika設計了一個檢測器介面,並採用了幾種更加完備的策略來檢測文件類型。
//org.apache.tika.detect.Detector
MediaType detect(InputStream stream, Metadata metadata) throws IOException;
文件類型檢測機制
- 文件名檢測 – 簡單地根據文件後綴名判斷文件類型。
- 魔術字檢測 – 有些文件格式會將文件最開始的幾個位元組設置會特定的模式,通過這些特殊的位元組模式,可以判斷文件類型。
- 容器格式檢測 – 有些文件格式是一種容器格式,這一類文件無法通過魔術字判斷出文件類型,需要對容器內的數據做更多的分析,如微軟Office文檔(.docx, .xlsx, .pptx)這些文檔實際上都是zip壓縮文件,魔術字是一樣的。
容器格式檢測耗時比較長,最壞的情況下需要讀取整個文件
文件類型的檢測順序
容器格式檢測(OLE2ContainerDetector, ZipContainerDetector……)=>
魔術字檢測(MimeTypes)=>
文件名檢測(MimeTypes)
MimeTypes底層實際使用了NameDetector和MagicDetector
解析器
Parser是tika的核心概念,它隱藏了不同文件格式和解析庫的複雜性,為客戶端程式提供了一個簡單而強大的機制,用來從各種各樣的文檔中提取元數據和結構化文本內容。tika提供了很多解析器,用來對各種各種的文件類型進行處理,如針對微軟Office文檔的OfficeParser,針對Adobe PDF文檔的PDFParser,針對壓縮文件的CompressorParser,針對歸檔文件的PackageParser,還有一些特殊的Parser,如TesseractOCRParser,用來對圖片進行OCR內容提取
如果伺服器安裝了tesseract,那麼TesseractOCRParser就會被啟用,在實時分析系統中,TesseractOCRParser的性能是不可接受的,建議手動禁用掉
void parse(InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) throws IOException, SAXException, TikaException;
介面說明
| 參數 | 說明 |
|---|---|
| InputStream | 待解析的文檔,以位元組流形式傳入,可以避免tika佔用太多記憶體 |
| ContentHandler | 內容處理器,用來收集結果,Tika會將解析結果包裝成XHTML SAX event進行分發,通過ContentHandler處理這些event就可以得到文本內容和其他有用的資訊 |
| Metadata | 元數據,既是輸入也是輸出,可以將文件名或者可能的文件類型傳入,tika解析時可以根據這些資訊判斷文件類型,再調用相應的解析器進行處理;另外,tika也會將一些額外的資訊保存到Metadata中,如文件修改日期,作者,編輯工具等 |
| ParseContext | 解析上下文,用來控制解析過程,比如是否提取Office文檔裡面的宏等 |
擴展機制
- 定義Mimetype(可選,如果需要處理一些特殊文件,它們的文件類型tika目前並不支援,就需要自定義Mimetype)
- 實現Parser,可以針對tika已有的文件類型編寫自己的解析器,也可以創建支援新的文件類型的解析器
- 註冊Parser,通過SPI機制可以輕鬆地將自己的解析器放進tika的解析器庫里(CompositeParser)
- 在類路徑下創建文件 – META-INF/services/org.apache.tika.parser.Parser
- 文件內容就是自定義的Parser的全路徑類名
其他tika組件(如類型檢測器,翻譯器,語言檢測器等)也使用該機制進行擴展
注意事項
配置
tika在啟動時可以載入一個配置文件,通過這個文件可以對tika-core的各個組件進行配置,可以配置Parser,Detector,Mimetype, ServiceLoader……
<?xml version="1.0" encoding="UTF-8"?>
<properties>
<detector class="org.apache.tika.detect.DefaultDetector">
<detector-exclude class="org.apache.tika.parser.pkg.ZipContainerDetector"/>
<detector-exclude class="org.apache.tika.parser.microsoft.POIFSContainerDetector"/>
</detector>
<parsers>
<!-- Default Parser for most things, except for 2 mime types, and never use the Executable Parser -->
<parser class="org.apache.tika.parser.DefaultParser">
<mime-exclude>image/jpeg</mime-exclude>
<mime-exclude>application/pdf</mime-exclude>
<parser-exclude class="org.apache.tika.parser.executable.ExecutableParser"/>
</parser>
<!-- Use a different parser for PDF -->
<parser class="org.apache.tika.parser.EmptyParser">
<mime>application/pdf</mime>
</parser>
</parsers>
</properties>
安全問題
tika設計了一個擴展性很好的解析器框架,但是具體的解析任務交給了外部的各種開源工具,因此也帶來了很多安全問題,在實際使用中推薦使用最新版本的類庫。
!!! 另外,tika有執行緒死鎖的問題,可能導致伺服器CPU資源耗盡,建議在容器(如docker)里運行,或者使用tika-server
影像,音頻,影片
tika可以從影像,音頻,影片文件中提取元數據,但是幾乎無法提取出任何有價值的文本內容,在大多數場景下建議禁用這些類型的Parser
針對影像,可以使用TesseractOCRParser進行OCR操作,這需要伺服器安裝了tesseract,OCR的效率很低,普通文件的解析一般在幾十毫秒左右,OCR的耗時約為幾秒鐘;而且OCR的結果依賴於演算法模型的訓練,需要整理出合適,足夠的樣本,工作量比較多。
解析時間跟文件大小和伺服器性能有關係,數據來自對8M以下互聯網文件的解析
文件修復
tika可以在解析時對文件進行一定程度的修復
比如,ZipSalvager可以對基於ZipContainer格式的文件進行修復
為了將解析耗時控制在一定範圍內,不得不對大文件進行截斷
提取其他資訊
tika的解析邏輯默認只會保留元數據(Metadata)和文本(Text),如果對其他資訊感興趣,就需要對ContentHandler進行訂製
tika提供了很多有用的ContentHandler,
比如ToXMLContentHandler將以XML形式輸出文件的文本內容,
WriteLimitContentHandler可以在解析得到一定字元數的結果後,中斷解析過程(拋出異常),
LinkContentHandler可以收集文件內容中的超鏈接,
PhoneContentHandler可以收集文件內容中的電話號碼。
提取壓縮文件里的文件名
默認配置下,tika解析壓縮文件(.gz, .bzip2等)和歸檔文件(.zip, .tar, .7z等)時,文件名會和文件內容雜糅在一起,如果需要區分開,可以自定義一個ContentHandler對class="embedded"的XHTML SAX event進行處理
Tika對壓縮文件內文件名的提取實現不完整,遇到特殊情況建議手動處理,重寫Parser
提取圖片
某些文件(主要是容器文件格式)內部可能含有其他內嵌文件,如壓縮文件,Word文檔,PDF文檔等,tika可以遞歸處理壓縮文件內部的子文件,但是除此之外沒有提供別的處理方法。
如果想要提取微軟Office文檔或者PDF文檔內的圖片,建議在tika的解析器框架下自己實現Parser,將圖片寫入的邏輯加上;或者直接使用具體的解析庫額外處理(比如使用Apache POI可以很方便的提取微軟Office文檔里的圖片)
tika的局限性
tika支援上千種文件類型,並且提供了統一的介面,非常容易上手;但是有些文件格式非常複雜,可能會出現支援不完善的情況,如對壓縮文件的解析依賴commons-compress,但是commons-compress對壓縮文件的支援就不完整,所以tika在處理某些文件時無法得到有用資訊
tika的性能
tika的解析器本質上是一個適配器,底層使用了很多第三方開源工具來實現具體的內容解析,因此tika的解析效率也跟這些工具有關
對某個具體文件來說,解析耗時主要跟文件大小,文件格式的複雜程度,壓縮演算法,伺服器性能等關係較大
實時系統中最好限制一下文件大小,推薦在離線環境中使用
簡單使用
tika是一個工具集,包括類庫,cli,gui,rest服務等,如何使用需要根據具體場景進行選擇。以下給出了tika作為類庫使用時的一些demo,更多的例子可以參考//tika.apache.org/1.24.1/examples.html
- 引入依賴
pom.xml
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers</artifactId>
<version>1.24.1</version>
</dependency>
//Parsing using the Tika Facade
public String parseToStringExample() throws IOException, SAXException, TikaException {
Tika tika = new Tika();
try (InputStream stream = ParsingExample.class.getResourceAsStream("test.doc")) {
return tika.parseToString(stream);
}
}
//Parsing using the Auto-Detect Parser
public String parseExample() throws IOException, SAXException, TikaException {
AutoDetectParser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
try (InputStream stream = ParsingExample.class.getResourceAsStream("test.doc")) {
parser.parse(stream, handler, metadata);
return handler.toString();
}
}
//Picking different output formats
public String parseToPlainText() throws IOException, SAXException, TikaException {
BodyContentHandler handler = new BodyContentHandler();
AutoDetectParser parser = new AutoDetectParser();
Metadata metadata = new Metadata();
try (InputStream stream = ContentHandlerExample.class.getResourceAsStream("test.doc")) {
parser.parse(stream, handler, metadata);
return handler.toString();
}
}
參考
- 白寧超 – Tika常見格式文件抽取內容並做預處理
- Tika官方文檔


