使用Wasserstein GAN生成小狗影像
一.前期學習經過
GAN(Generative Adversarial Nets)是生成對抗網路的簡稱,由生成器和判別器組成,在訓練過程中通過生成器和判別器的相互對抗,來相互的促進、提高。最近一段時間對GAN進行了學習,並使用GAN做了一次實踐,在這裡做一篇筆記記錄一下。
最初我參照JensLee大神的講解,使用keras構造了一個DCGAN(深度卷積生成對抗網路)模型,來對數據集中的256張小狗影像進行學習,都是一些類似這樣的狗狗照片:
他的方法是通過隨機生成的維度為1000的向量,生成大小為64*64的狗狗圖。但經過較長時間的訓練,設置了多種超參數進行調試,仍感覺效果不理想,總是在訓練到一定程度之後,生成器的loss就不再改變,成為一個固定值,生成的圖片也看不出狗的樣子。
後續經過查閱資料,了解到DCGAN模型損失函數的定義會使生成器和判別器優化目標相背離,判別器訓練的越好,生成器的梯度消失現象越嚴重,在之前DCGAN的實驗中,生成器的loss長時間不變動就是梯度消失引起的。而Wasserstein GAN(簡稱WGAN)對其進行了改進,修改了生成器和判別器的損失函數,避免了當判別器訓練程度較好時,生成器的梯度消失問題,並參照這篇部落格,構建了WGAN網路對小狗影像數據集進行學習。鄭華濱大佬的這篇文章對WGAN的原理進行了細緻的講解,想要深入對模型原理進行挖掘的小夥伴可以去深入學習一下,本文重點講實踐應用。
二.模型實現
這裡的程式碼是在TensorFlow框架(版本1.14.0)上實現的,python語言(版本3.6.4)
1.對TensorFlow的卷積、反卷積、全連接等操作進行封裝,使其變數名稱規整且方便調用。
1 def conv2d(name, tensor,ksize, out_dim, stddev=0.01, stride=2, padding='SAME'): 2 with tf.variable_scope(name): 3 w = tf.get_variable('w', [ksize, ksize, tensor.get_shape()[-1],out_dim], dtype=tf.float32, 4 initializer=tf.random_normal_initializer(stddev=stddev)) 5 var = tf.nn.conv2d(tensor,w,[1,stride, stride,1],padding=padding) 6 b = tf.get_variable('b', [out_dim], 'float32',initializer=tf.constant_initializer(0.01)) 7 return tf.nn.bias_add(var, b) 8 9 def deconv2d(name, tensor, ksize, outshape, stddev=0.01, stride=2, padding='SAME'): 10 with tf.variable_scope(name): 11 w = tf.get_variable('w', [ksize, ksize, outshape[-1], tensor.get_shape()[-1]], dtype=tf.float32, 12 initializer=tf.random_normal_initializer(stddev=stddev)) 13 var = tf.nn.conv2d_transpose(tensor, w, outshape, strides=[1, stride, stride, 1], padding=padding) 14 b = tf.get_variable('b', [outshape[-1]], 'float32', initializer=tf.constant_initializer(0.01)) 15 return tf.nn.bias_add(var, b) 16 17 def fully_connected(name,value, output_shape): 18 with tf.variable_scope(name, reuse=None) as scope: 19 shape = value.get_shape().as_list() 20 w = tf.get_variable('w', [shape[1], output_shape], dtype=tf.float32, 21 initializer=tf.random_normal_initializer(stddev=0.01)) 22 b = tf.get_variable('b', [output_shape], dtype=tf.float32, initializer=tf.constant_initializer(0.0)) 23 return tf.matmul(value, w) + b 24 25 def relu(name, tensor): 26 return tf.nn.relu(tensor, name) 27 28 def lrelu(name,x, leak=0.2): 29 return tf.maximum(x, leak * x, name=name)
在卷積函數(conv2d)和反卷積函數(deconv2d)中,變數’w’就是指卷積核,他們的維度分布時有差異的,卷積函數中,卷積核的維度為[卷積核高,卷積核寬,輸入通道維度,輸出通道維度],而反卷積操作中的卷積核則將最後兩個維度順序調換,變為[卷積核高,卷積核寬,輸出通道維度,輸入通道維度]。反卷積是卷積操作的逆過程,通俗上可理解為:已知卷積結果矩陣(維度y*y),和卷積核(維度k*k),獲得卷積前的原始矩陣(維度x*x)這麼一個過程。而不論是卷積操作還是反卷積操作,都需要對輸出的維度進行計算,並作為函數的參數(即out_dim和outshape變數)輸入到函數中。經過個人總結,卷積(反卷積)操作輸出維度的計算公式如下(公式為個人總結,如有錯誤歡迎指出):
正向卷積維度計算:
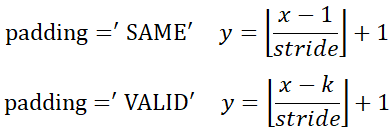
其中,’⌊⌋’是向下取整符號,y是卷積後邊長,x是卷積前邊長,k指的是卷積核寬/高,stride指步長。
反向卷積維度計算:
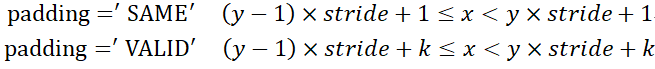
其中,y是反卷積前的邊長,x是反卷積後的邊長,k指的是卷積核寬/高,stride指步長。
relu()和lrelu()函數是兩個激活函數,lrelu()其中LeakyRelu激活函數的實現,它能夠減輕RELU的稀疏性。
2.對判別器進行構建。
1 def Discriminator(name,inputs,reuse): 2 with tf.variable_scope(name, reuse=reuse): 3 output = tf.reshape(inputs, [-1, pic_height_width, pic_height_width, inputs.shape[-1]]) 4 output1 = conv2d('d_conv_1', output, ksize=5, out_dim=DEPTH) #32*32 5 output2 = lrelu('d_lrelu_1', output1) 6 7 output3 = conv2d('d_conv_2', output2, ksize=5, padding="VALID",stride=1,out_dim=DEPTH) #28*28 8 output4 = lrelu('d_lrelu_2', output3) 9 10 output5 = conv2d('d_conv_3', output4, ksize=5, out_dim=2*DEPTH) #14*14 11 output6 = lrelu('d_lrelu_3', output5) 12 13 output7 = conv2d('d_conv_4', output6, ksize=5, out_dim=4*DEPTH) #7*7 14 output8 = lrelu('d_lrelu_4', output7) 15 16 output9 = conv2d('d_conv_5', output8, ksize=5, out_dim=6*DEPTH) #4*4 17 output10 = lrelu('d_lrelu_5', output9) 18 19 output11 = conv2d('d_conv_6', output10, ksize=5, out_dim=8*DEPTH) #2*2 20 output12 = lrelu('d_lrelu_6', output11) 21 22 chanel = output12.get_shape().as_list() 23 output13 = tf.reshape(output12, [batch_size, chanel[1]*chanel[2]*chanel[3]]) 24 output0 = fully_connected('d_fc', output13, 1) 25 return output0
判別器的作用是輸入一個固定大小的影像,經過多層卷積、激活函數、全連接計算後,得到一個值,根據這個值可以判定該輸入影像是否是狗。
首先是命名空間問題,函數參數name即規定了生成器的命名空間,下面所有新生成的變數都在這個命名空間之內,另外每一步卷積、激活函數、全連接操作都需要手動賦命名空間,這些命名不能重複,如變數output1的命名空間為‘d_conv_1’,變數output5的命名空間為‘d_conv_3’,不重複的命名也方便後續對模型進行保存載入。先將輸入影像inputs形變為[-1,64, 64, 3]的tensor,其中第一個維度-1是指任意數量,即任意數量的圖片,每張圖片長寬各64個像素,有3個通道(RGB),形變後的output維度為[batch_size,64,64,3]。接下來開始卷積操作得到變數output1,由於默認的stride=2、padding=”SAME”,根據上面的正向卷積維度計算公式,得到卷積後的影像大小為32*32,而通道數則由一個全局變數DEPTH來確定,這樣計算每一層的輸出維度,卷積核大小都是5*5,只有在output3這一行填充方式和步長進行了調整,以將其從32*32的影像卷積成28*28。最後將維度為[batch_size,2,2,8*DEPTH]的變數形變為[batch_size,2*2*8*DEPTH]的變數,在進行全連接操作(矩陣乘法),得到變數output0(維度為[batch_size,1]),即對輸入中batch_size個影像的判別結果。
一般的判別器會在全連接層後方加一個sigmoid激活函數,將數值歸併到[0,1]之間,以直觀的顯示該圖片是狗的概率,但WGAN使用Wasserstein距離來計算損失,因此需要去掉sigmoid激活函數。
3.對生成器進行構建。
1 def generator(name, reuse=False): 2 with tf.variable_scope(name, reuse=reuse): 3 noise = tf.random_normal([batch_size, 128])#.astype('float32') 4 5 noise = tf.reshape(noise, [batch_size, 128], 'noise') 6 output = fully_connected('g_fc_1', noise, 2*2*8*DEPTH) 7 output = tf.reshape(output, [batch_size, 2, 2, 8*DEPTH], 'g_conv') 8 9 output = deconv2d('g_deconv_1', output, ksize=5, outshape=[batch_size, 4, 4, 6*DEPTH]) 10 output = tf.nn.relu(output) 11 # output = tf.reshape(output, [batch_size, 4, 4, 6*DEPTH]) 12 13 output = deconv2d('g_deconv_2', output, ksize=5, outshape=[batch_size, 7, 7, 4* DEPTH]) 14 output = tf.nn.relu(output) 15 16 output = deconv2d('g_deconv_3', output, ksize=5, outshape=[batch_size, 14, 14, 2*DEPTH]) 17 output = tf.nn.relu(output) 18 19 output = deconv2d('g_deconv_4', output, ksize=5, outshape=[batch_size, 28, 28, DEPTH]) 20 output = tf.nn.relu(output) 21 22 output = deconv2d('g_deconv_5', output, ksize=5, outshape=[batch_size, 32, 32, DEPTH],stride=1, padding='VALID') 23 output = tf.nn.relu(output) 24 25 output = deconv2d('g_deconv_6', output, ksize=5, outshape=[batch_size, OUTPUT_SIZE, OUTPUT_SIZE, 3]) 26 # output = tf.nn.relu(output) 27 output = tf.nn.sigmoid(output) 28 return tf.reshape(output,[-1,OUTPUT_SIZE,OUTPUT_SIZE,3])
生成器的作用是隨機產生一個隨機值向量,並通過形變、反卷積等操作,將其轉變為[64,64,3]的影像。
首先生成隨機值向量noise,其維度為[batch_size,128],接下來的步驟和判別器完全相反,先通過全連接層,將其轉換為[batch_size, 2*2*8*DEPTH]的變數,並形變為[batch_size, 2, 2, 8*DEPTH],之後,通過不斷的反卷積操作,將變數維度變為[batch_size, 4, 4, 6*DEPTH]→[batch_size, 7, 7, 4* DEPTH]→[batch_size, 14, 14, 2*DEPTH]→[batch_size, 28, 28, DEPTH]→[batch_size, 32, 32, DEPTH]→[batch_size, 64, 64, 3],與卷積層不同之處在於,每一步反卷積操作的輸出維度,需要手動規定,具體計算方法參加上方的反向卷積維度計算公式。最終得到的output變數即batch_size張生成的影像。
4.數據預處理。
1 def load_data(path): 2 X_train = [] 3 img_list = glob.glob(path + '/*.jpg') 4 for img in img_list: 5 _img = cv2.imread(img) 6 _img = cv2.resize(_img, (pic_height_width, pic_height_width)) 7 X_train.append(_img) 8 print('訓練集影像數目:',len(X_train)) 9 # print(X_train[0],type(X_train[0]),X_train[0].shape) 10 return np.array(X_train, dtype=np.uint8) 11 12 def normalization(input_matirx): 13 input_shape = input_matirx.shape 14 total_dim = 1 15 for i in range(len(input_shape)): 16 total_dim = total_dim*input_shape[i] 17 big_vector = input_matirx.reshape(total_dim,) 18 out_vector = [] 19 for i in range(len(big_vector)): 20 out_vector.append(big_vector[i]/256) # 0~256值歸一化 21 out_vector = np.array(out_vector) 22 out_matrix = out_vector.reshape(input_shape) 23 return out_matrix 24 25 def denormalization(input_matirx): 26 input_shape = input_matirx.shape 27 total_dim = 1 28 for i in range(len(input_shape)): 29 total_dim = total_dim*input_shape[i] 30 big_vector = input_matirx.reshape(total_dim,) 31 out_vector = [] 32 for i in range(len(big_vector)): 33 out_vector.append(big_vector[i]*256) # 0~256值還原 34 out_vector = np.array(out_vector) 35 out_matrix = out_vector.reshape(input_shape) 36 return out_matrix
這些函數主要用於載入原始影像,並根據我們WGAN模型的要求,對原始影像進行預處理。load_data()函數用來載入數據文件夾中的所有狗狗影像,並將載入的影像縮放到64*64像素的大小。normalization()函數和denormalization()函數用來對影像數據進行歸一化和反歸一化,每個像素在單個通道中的取值在[0~256]之間,我們需要將其歸一化到[0,1]範圍內,否則在模型訓練過程中loss會出現較大波動;在使用生成器得到生成結果之後,每個像素內的數值都在[0,1]之間,需要將其反歸一化到[0~256]。
5.模型訓練。
1 def train(): 2 with tf.variable_scope(tf.get_variable_scope()): 3 real_data = tf.placeholder(tf.float32, shape=[batch_size,pic_height_width,pic_height_width,3]) 4 with tf.variable_scope(tf.get_variable_scope()): 5 fake_data = generator('gen',reuse=False) 6 disc_real = Discriminator('dis_r',real_data,reuse=False) 7 disc_fake = Discriminator('dis_r',fake_data,reuse=True) 8 """獲取變數列表,d_vars為判別器參數,g_vars為生成器的參數""" 9 t_vars = tf.trainable_variables() 10 d_vars = [var for var in t_vars if 'd_' in var.name] 11 g_vars = [var for var in t_vars if 'g_' in var.name] 12 '''計算損失''' 13 gen_cost = -tf.reduce_mean(disc_fake) 14 disc_cost = tf.reduce_mean(disc_fake) - tf.reduce_mean(disc_real) 15 16 alpha = tf.random_uniform( 17 shape=[batch_size, 1],minval=0.,maxval=1.) 18 differences = fake_data - real_data 19 interpolates = real_data + (alpha * differences) 20 gradients = tf.gradients(Discriminator('dis_r',interpolates,reuse=True), [interpolates])[0] 21 slopes = tf.sqrt(tf.reduce_sum(tf.square(gradients), reduction_indices=[1])) 22 gradient_penalty = tf.reduce_mean((slopes - 1.) ** 2) 23 disc_cost += LAMBDA * gradient_penalty 24 """定義優化器optimizer""" 25 with tf.variable_scope(tf.get_variable_scope(), reuse=None): 26 gen_train_op = tf.train.RMSPropOptimizer( 27 learning_rate=1e-4,decay=0.9).minimize(gen_cost,var_list=g_vars) 28 disc_train_op = tf.train.RMSPropOptimizer( 29 learning_rate=1e-4,decay=0.9).minimize(disc_cost,var_list=d_vars) 30 saver = tf.train.Saver() 31 sess = tf.InteractiveSession() 32 coord = tf.train.Coordinator() 33 threads = tf.train.start_queue_runners(sess=sess, coord=coord) 34 """初始化參數""" 35 init = tf.global_variables_initializer() 36 sess.run(init) 37 '''獲得數據''' 38 dog_data = load_data(data_path) 39 dog_data = normalization(dog_data) 40 for epoch in range (1, EPOCH): 41 for iters in range(IDXS): 42 if(iters%4==3): 43 img = dog_data[(iters%4)*batch_size:] 44 else: 45 img = dog_data[(iters%4)*batch_size:((iters+1)%4)*batch_size] 46 for x in range(1): # TODO 在對一批數據展開訓練時,訓練幾次生成器 47 _, g_loss = sess.run([gen_train_op, gen_cost]) 48 for x in range(0,3): # TODO 訓練一次生成器,訓練幾次判別器... 49 _, d_loss = sess.run([disc_train_op, disc_cost], feed_dict={real_data: img}) 50 print("[%4d:%4d/%4d] d_loss: %.8f, g_loss: %.8f"%(epoch, iters, IDXS, d_loss, g_loss)) 51 52 with tf.variable_scope(tf.get_variable_scope()): 53 samples = generator('gen', reuse=True) 54 samples = tf.reshape(samples, shape=[batch_size,pic_height_width,pic_height_width,3]) 55 samples=sess.run(samples) 56 samples = denormalization(samples) # 還原0~256 RGB 通道數值 57 save_images(samples, [8,8], os.getcwd()+'/img/'+'sample_%d_epoch.png' % (epoch)) 58 59 if epoch%10==9: 60 checkpoint_path = os.path.join(os.getcwd(), 61 './models/WGAN/my_wgan-gp.ckpt') 62 saver.save(sess, checkpoint_path, global_step=epoch) 63 print('********* model saved *********') 64 coord.request_stop() 65 coord.join(threads) 66 sess.close()
這一部分程式碼中,在34行”初始化參數”之前,還都屬於計算圖繪製階段,包括定義佔位符,定義損失函數,定義優化器等。需要注意的是獲取變數列表這一步,需要對計算圖中的所有變數進行篩選,根據命名空間,將所有生成器所包含的參數存入g_vars,將所有判別器所包含的參數存入d_vars。在定義生成器優化器的時候,指定var_list=g_vars;在定義判別器優化器的時候,指定var_list=d_vars。
在訓練的過程中,兩個全局變數控制訓練的程度,EPOCH即訓練的輪次數目,IDXS則為每輪訓練中訓練多少個批次。第46行,48行的for循環用來控制對生成器、判別器的訓練程度,本例中訓練程度為1:3,即訓練1次生成器,訓練3次判別器,這個比例可以自己設定,WGAN模型其實對這個比例不是特別敏感。
根據上述構建好的WGAN模型,設置EPOCH=200,IDXS=1000,在自己的電能上訓練了24個小時,觀察每一輪次的影像生成結果,可以看出生成器不斷的進化,從一片混沌到初具狗的形狀。下方4幅影像分別是訓練第1輪,第5輪,第50輪,第200輪的生成器模型的輸出效果,每張影像中包含64個小圖,可以看出狗的外形逐步顯現出來。




這次實驗的程式碼在github上進行了保存://github.com/NosenLiu/Dog-Generator-by-TensorFlow 除了這個WGAN模型的訓練程式碼外,還有對進行模型、載入、再訓練的相關內容。有興趣的朋友可以關注(star☆)一下。
三.總結感悟
通過這次實踐,對WGAN模型有了一定程度的理解,尤其是對生成器的訓練是十分到位的,比較容易出效果。但是由於它的判別器最後一層沒有sigmoid函數,單獨應用這個判別器對一個影像進行計算,根據計算結果,很難直接的得到這張圖片中是狗圖的概率。另外由於沒有使用目標識別來對數據集進行預處理,WGAN會認為數據集中照片中的所有內容都是狗,這也就導致了後面生成的部分照片中有較大區域的綠色,應該是生成器將數據集中的草地認作了狗的一部分。
參考
//blog.csdn.net/LEE18254290736/article/details/97371930
//zhuanlan.zhihu.com/p/25071913
//blog.csdn.net/xg123321123/article/details/78034859


