Linux內核之 記憶體管理
前面幾篇介紹了進程的一些知識,從這篇開始介紹記憶體、文件、IO等知識,發現更不好寫哈哈。但還是有必要記錄下自己的所學所思。供後續翻閱,同時寫作也是一個鞏固的過程。
這些知識以前有文檔涉及過,但是角度不同,這個系列站的角度更底層,基本都是從Linux內核出發,會更深入。所以當你都讀完,然後再次審視這些功能的實現和設計時,我相信你會有種豁然開朗的感覺。
1、頁
內核把物理頁作為記憶體管理的基本單元。
儘管處理器的最小處理單位是字(或者位元組),但是MMU(記憶體管理單元,管理記憶體並把虛擬地址轉換為物理地址的硬體)通常以頁為單位進行處理。所以從虛擬記憶體看,頁也是最小單元。
體系不同,支援的頁大小不同。大多數32位體系結構支援4KB的頁,而64位體系結構一般會支援8KB的頁。
內核用struct page結構體表示系統中的每個頁,包含很多項比如頁的狀態(有沒有臟,有沒有被鎖定)、引用計數(-1表示沒有使用)等等。
page結構和物理頁相關,和虛擬記憶體無關。所以它的描述是短暫的,僅僅記錄當前的使用狀況,當然也不會描述其中的數據。
內核用這個結構來管理系統中所有的頁,所以內核知道哪些頁是空閑的,如果在使用中擁有者又是誰。
這個擁有者有四種:用戶空間進程、動態分配記憶體的內核數據、靜態內核程式碼以及頁高速快取。
2、區
有些頁是有特定用途的。比如記憶體中有些頁是專門用於DMA的。
內核使用區的概念將具有相似特性的頁進行分組。區是一種邏輯上的分組的概念,而沒有物理上的意義。
區的實際使用和分布是與體系結構相關的。在x86體系結構中主要分為3個區:ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM。
ZONE_DMA區中的頁用來進行DMA(直接記憶體訪問)時使用。
ZONE_HIGHMEM是高端記憶體,其中的頁不能永久的映射到內核地址空間,也就是說,沒有虛擬地址。
剩餘的記憶體就屬於ZONE_NORMAL區,叫低端記憶體。
不是所有體系都定義全部區,有些體系結構,比如x86-64可以映射和處理64位的記憶體空間,所以它沒有ZONE_HIGHMEM區,所有的物理記憶體都都處於ZONE_DMA和ZONE_NORMAL區。
每個區都用結構體struct zone表示。
3、介面
獲得頁
獲得頁使用的介面是alloc_pages函數與__get_free_page函數。後者也是調用了前者,只不過在獲得了struct page結構體後使用page_address函數獲得了虛擬地址。
我們在使用這些介面獲取頁的時候可能會面對一個問題,我們獲得的這些頁若是給用戶態用,雖然這些頁中的數據都是隨機產生的垃圾數據,不過,雖然概率很低,但是也有可能會包含某些敏感資訊。所以,更謹慎些,我們可以將獲得的頁都填充為0。這會用到get_zeroed_page函數。而這個函數又用到了__get_free_pages函數。
所以這三個函數最終都是使用了alloc_pages函數。
釋放頁
當我們不再需要某些頁時可以使用下面的函數釋放它們:
__free_pages(struct page *page, unsigned int order)
free_pages(unsigned long addr, unsigned int order)
free_page(unsigned long addr)
以上這些介面都是以頁為單位進行記憶體分配與釋放的。
kmalloc與vmalloc
在實際中內核需要的記憶體不一定是整個頁,可能只是以位元組為單位的一片區域。這兩個函數就是實現這樣的目的。
不同之處在於,kmalloc分配的是虛擬地址連續,物理地址也連續的一片區域,vmalloc分配的是虛擬地址連續,物理地址不一定連續的一片區域。
對應的釋放記憶體的函數是kfree與vfree。
4、slab層
以頁為最小單位分配記憶體對於內核管理系統中的物理記憶體來說的確比較方便,但內核自身最常使用的記憶體卻往往是很小的記憶體塊——比如存放文件描述符、進程描述符、虛擬記憶體區域描述符等行為所需的記憶體都遠不及一頁,一個整頁中可以聚集多個這些小塊記憶體。
為了滿足內核對這種小記憶體塊的需要,Linux系統採用了一種被稱為slab分配器(也稱作slab層)的技術。slab分配器的實現相當複雜,但原理不難,其核心思想就是「存儲池」的運用。記憶體片段(小塊記憶體)被看作對象,當被使用完後,並不直接釋放而是被快取到「存儲池」里,留做下次使用,這無疑避免了頻繁創建與銷毀對象所帶來的額外負載。
slab分配器扮演了通用數據結構快取層的角色。
slab層把不同的對象劃分為所謂高速快取組,其中每個高速快取組都存放不同類型的對象,每種對象對應一個高速快取。
常見的高速快取組有:進程描述符(task_struct結構體),索引節點對象(struct inode),目錄項對象(struct dentry),通用頁對象等等。
這些高速快取又被劃分為slab。slab由一個或多個物理連續的頁組成,一般僅僅由一頁組成。每個高速快取可以由多個slab(頁)組成。
每個高速快取都使用struct kmem_cache結構表示,這個結構包含三個鏈表:slabs_full、slabs_partial和slabs_empty,均放在kmem_list3結構體內。這些鏈表的每個元素為slab描述符即struct slab結構體。
每個高速快取需要創建新的slab即新的頁,還是通過上面提到的__get_free_page()來實現的。通過最終調用free_pages()釋放記憶體頁。
一個高速快取的創建和銷毀使用kmem_cache_create與kmem_cache_destroy。
高速快取中的對象的分配和釋放使用kmem_cache_alloc與kmem_cache_free。
從上看出,slab層仍然是建立在頁的基礎之上,可以總結為slab層將 空閑頁 分解成 眾多相同長度的小塊記憶體 以供 同類型的數據結構 使用。
5、進程地址空間
以上我們講述了內核如何管理記憶體,內核記憶體分配機制包括了頁分配器和slab分配器。內核除了管理本身的記憶體外,也必須管理用戶空間中進程的記憶體。
我們稱這個記憶體為進程地址空間,也就是系統中每個用戶空間進程所看到的記憶體。Linux系統採用虛擬記憶體技術,所有進程以虛擬方式共享記憶體。Linux中主要採用分頁機制而不是分段機制。
5.1 地址空間布局
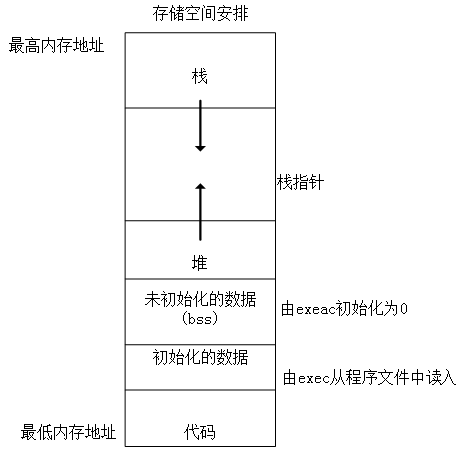
進程記憶體區域可以包含各種記憶體對象,從下往上依次為:
(1)可執行文件程式碼的記憶體映射,稱為程式碼段。只讀可執行。
(2)可執行文件的已初始化全局變數的記憶體映射,稱為數據段。後續都是可讀寫。
(3)包含未初始化的全局變數,就是bass段的零頁的記憶體映射。
(4)堆區,動態記憶體分配區域;包括任何匿名的記憶體映射,比如malloc分配的記憶體。
(5)棧區,用於進程用戶空間棧的零頁記憶體映射,這裡不要和進程內核棧混淆,進程的內核棧獨立存在並由內核維護,因為內核管理著所有進程。所以內核管理著內核棧,內核棧管理著進程。
(6)其他可能存在的:記憶體映射文件;共享記憶體段;C庫或者動態鏈接庫等共享庫的程式碼段、數據段和bss也會被載入進程的地址空間。
5.2 記憶體描述符
內核使用記憶體描述符mm_struct結構體表示進程的地址空間,該結構體包含了和進程地址空間有關的全部資訊。
1 struct mm_struct { 2 struct vm_area_struct *mmap; /* list of memory areas */ 3 struct rb_root mm_rb; /* red-black tree of VMAs */ 4 struct vm_area_struct *mmap_cache; /* last used memory area */ 5 unsigned long free_area_cache; /* 1st address space hole */ 6 pgd_t *pgd; /* page global directory */ 7 atomic_t mm_users; /* address space users */ 8 atomic_t mm_count; /* primary usage counter */ 9 int map_count; /* number of memory areas */ 10 struct rw_semaphore mmap_sem; /* memory area semaphore */ 11 spinlock_t page_table_lock; /* page table lock */ 12 struct list_head mmlist; /* list of all mm_structs */ 13 unsigned long start_code; /* start address of code */ 14 unsigned long end_code; /* final address of code */ 15 unsigned long start_data; /* start address of data */ 16 unsigned long end_data; /* final address of data */ 17 unsigned long start_brk; /* start address of heap */ 18 unsigned long brk; /* final address of heap */ 19 unsigned long start_stack; /* start address of stack */ 20 unsigned long arg_start; /* start of arguments */ 21 unsigned long arg_end; /* end of arguments */ 22 unsigned long env_start; /* start of environment */ 23 unsigned long env_end; /* end of environment */ 24 unsigned long rss; /* pages allocated */ 25 unsigned long total_vm; /* total number of pages */ 26 unsigned long locked_vm; /* number of locked pages */ 27 unsigned long def_flags; /* default access flags */ 28 unsigned long cpu_vm_mask; /* lazy TLB switch mask */ 29 unsigned long swap_address; /* last scanned address */ 30 unsigned dumpable:1; /* can this mm core dump? */ 31 int used_hugetlb; /* used hugetlb pages? */ 32 mm_context_t context; /* arch-specific data */ 33 int core_waiters; /* thread core dump waiters */ 34 struct completion *core_startup_done; /* core start completion */ 35 struct completion core_done; /* core end completion */ 36 rwlock_t ioctx_list_lock; /* AIO I/O list lock */ 37 struct kioctx *ioctx_list; /* AIO I/O list */ 38 struct kioctx default_kioctx; /* AIO default I/O context */ 39 };
mmap和mm_rb描述的對象是一樣的:該地址空間中全部記憶體區域(all memory areas)。
mmap是以鏈表的形式存放,而mm_rb是以紅黑樹存放,前者有利於遍歷所有數據,而後者有利於快速搜索定位到某個地址。所有的mm_struct結構體都通過自身的mmlist域連接在一個雙向鏈表中,該鏈表的首元素是init_mm記憶體描述符,它代表init進程的地址空間。
再往下看,可以看到地址空間幾個區(堆棧)對應的變數的定義。
我們再回顧下在內核進程管理中,進程描述符task_struct是在內核空間中快取,也就是我們上面描述的slab層。
而task_struct中有個mm域指向的就是該進程使用的記憶體描述符,再通過current->mm便可以指向當前進程的記憶體描述符。fork函數利用copy_mm()函數就實現了複製父進程的記憶體描述符,而子進程中的mm_struct結構體實際是通過文件kernel/fork.c中的allocate_mm()宏從mm_cachep slab快取中分配得到的。通常,每個進程都有唯一的mm_struct結構體。
因為進程描述符和進程的記憶體描述符都是處於slab層,所以它們元素的分配和釋放都由slab分配器來管理。
5.3 虛擬記憶體區域
記憶體區域由vm_area_struct結構體描述,見上面的mmap域,記憶體區域在內核中也經常被稱作虛擬記憶體區域(Virtual Memory Area,VMA)。
它描述了指定地址空間內連續區間上的一個獨立記憶體範圍。
內核將每個記憶體區域作為一個單獨的記憶體對象管理,每個記憶體區域都擁有一致的屬性。結構體如下:
1 struct vm_area_struct { 2 struct mm_struct *vm_mm; /* associated mm_struct */ 3 unsigned long vm_start; /* VMA start, inclusive */ 4 unsigned long vm_end; /* VMA end , exclusive */ 5 struct vm_area_struct *vm_next; /* list of VMA's */ 6 pgprot_t vm_page_prot; /* access permissions */ 7 unsigned long vm_flags; /* flags */ 8 struct rb_node vm_rb; /* VMA's node in the tree */ 9 union { /* links to address_space->i_mmap or i_mmap_nonlinear */ 10 struct { 11 struct list_head list; 12 void *parent; 13 struct vm_area_struct *head; 14 } vm_set; 15 struct prio_tree_node prio_tree_node; 16 } shared; 17 struct list_head anon_vma_node; /* anon_vma entry */ 18 struct anon_vma *anon_vma; /* anonymous VMA object */ 19 struct vm_operations_struct *vm_ops; /* associated ops */ 20 unsigned long vm_pgoff; /* offset within file */ 21 struct file *vm_file; /* mapped file, if any */ 22 void *vm_private_data; /* private data */ 23 };
每個記憶體描述符都對應於地址進程空間中的唯一區間。vm_mm域指向和VMA相關的mm_struct結構體。
一個記憶體區域的地址範圍是[vm_start, vm_end),vm_next指向該進程的下一個記憶體區域。
兩個獨立的進程將同一個文件映射到各自的地址空間,它們分別都會有一個vm_area_struct結構體來標誌自己的記憶體區域;但是如果兩個執行緒共享一個地址空間,那麼它們也同時共享其中的所有vm_area_struct結構體。
在上面的vm_flags域中存放的是VMA標誌,標誌了記憶體區域所包含的頁面的行為和資訊。和物理頁訪問許可權不同,VMA標誌反映了內核處理頁面所需要遵循的行為準則,而不是硬體要求。而且vm_flags同時包含了記憶體區域中每個頁面的消息或者記憶體區域的整體資訊,而不是具體的獨立頁面。如下表所述:

開頭三個標誌表示程式碼在該記憶體區域的可讀、可寫和可執行許可權。
第四個標誌VM_SHARD說明了該區域包含的映射是否可以在多進程間共享,如果被設置了,表示共享映射;否則未被設置,表示私有映射。
其中很多狀態在實際使用中都非常有用。
5.4 mmap()和do_mmap():創建地址空間
內核使用do_mmap()函數創建一個新的線性地址空間。但如果創建的地址區間和一個已經存在的地址區間相鄰,並且它們具有相同的訪問許可權的話,那麼兩個區間將合併為一個。如果不能合併,那麼就確實需要創建一個新的vma了,但無論哪種情況,do_mmap()函數都會將一個地址區間加入到進程的地址空間中。這個函數定義在linux/mm.h中,如下
unsigned long do_mmap(struct file *file, unsigned long addr, unsigned long len, unsigned long prot,unsigned long flag, unsigned long offset)
這個函數中由file指定文件,具體映射的是文件中從偏移offset處開始,長度為len位元組的範圍內的數據,如果file參數是NULL並且offset參數也是0,那麼就代表這次映射沒有和文件相關,該情況被稱作匿名映射(file-backed mapping)。如果指定了文件和偏移量,那麼該映射被稱為文件映射(file-backed mapping)。
其中參數prot指定記憶體區域中頁面的訪問許可權:可讀、可寫、可執行。
flag參數指定了VMA標誌,這些標誌指定類型並改變映射的行為,請見上一小節。
如果系統調用do_mmap的參數中有無效參數,那麼它返回一個負值;否則,它會在虛擬記憶體中分配一個合適的新記憶體區域,如果有可能的話,將新區域和臨近區域進行合併,否則內核從vm_area_cachep長位元組(slab)快取中分配一個vm_area_struct結構體,並且使用vma_link()函數將新分配的記憶體區域添加到地址空間的記憶體區域鏈表和紅黑樹中,隨後還要更新記憶體描述符中的total_vm域,然後才返回新分配的地址區間的初始地址。
在用戶空間,我們可以通過mmap()系統調用獲取內核函數do_mmap()的功能。
5.5 munmap()和do_munmap():刪除地址空間
do_mummp()函數從特定的進程地址空間中刪除指定地址空間,該函數定義在文件linux/mm.h中,如下:
int do_munmap(struct mm_struct *mm, unsigned long start, size_t len)
第一個參數指定要刪除區域所在的地址空間,刪除從地址start開始,長度為len位元組的地址空間,如果成功,返回0,否則返回負的錯誤碼。
與之相對應的用戶空間系統調用是munmap,它是對do_mummp()函數的一個簡單封裝。
5.6 malloc()的實現
我們知道malloc()是C庫中實現的。C庫對記憶體分配的管理還有calloc()、realloc()、free()等函數。
事實上,malloc函數是以brk()或者mmap()系統調用實現的。
brk和sbrk主要的工作是實現虛擬記憶體到記憶體的映射。在Linux系統上,程式被載入記憶體時,內核為用戶進程地址空間建立了程式碼段、數據段和堆棧段,在數據段與堆棧段之間的空閑區域用於動態記憶體分配。我們回到記憶體結構mm_struct中的成員變數start_code和end_code是進程程式碼段的起始和終止地址,start_data和 end_data是進程數據段的起始和終止地址,start_stack是進程堆棧段起始地址,start_brk是進程動態記憶體分配起始地址(堆的起始地址),還有一個 brk(堆的當前最後地址),就是動態記憶體分配當前的終止地址。所以C庫的malloc()在Linux上的基本實現是通過內核的brk系統調用。brk()是一個非常簡單的系統調用,內核再執行sys_brk()函數進行記憶體分配,只是簡單地改變mm_struct結構的成員變數brk的值。而sbrk不是系統調用,是C庫函數。系統調用通常提供一種最小功能,而庫函數通常提供比較複雜的功能。
下面我們整理一下在進程空間堆中用brk()方式進行動態記憶體分配的流程:
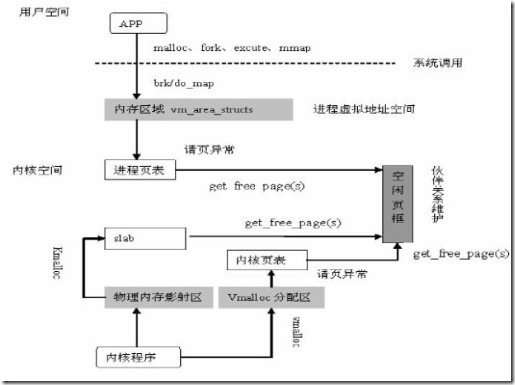
C庫函數malloc()調用Linux系統調用函數brk(),brk()執行系統調用陷入到內核,內核執行sys_brk()函數,sys_brk()函數調用do_brk()進行記憶體分配
malloc()———->brk()—–|—–>sys_brk()———–>do_brk()————>vma_merge()/kmem_cache_zalloc()
用戶空間——> | 內核空間
系統調用———->
mmap()系統調用也可以實現動態記憶體分配功能,即5.4節我們提到的匿名映射。
那什麼時候調用brk(),什麼時候調用mmap()呢?通過閾值M_MMAP_THRESHOLD來決定。該值默認128KB。可以通過mallopt()來進行修改設置。
所以當需要分配的記憶體大於該閾值,選擇mmap();否則小於等於該閾值,選擇brk()分配。
最後,mmap分配的記憶體在調用munmap後會立即返回給系統,而brk/sbrk而受M_TRIM_THRESHOLD的影響。該環境變數同樣通過mallopt()來設置,該值代表的意義是釋放記憶體的最少位元組數。
此時,str1和str2的記憶體只是簡單的標記為「未使用」,如果這兩處記憶體是相鄰的則會進行合併,這種演算法也稱為「夥伴記憶體演算法(buddy memory allocation scheme)」。這種演算法高速簡單,但同時也會生成碎片。包括內碎片(一次分配記憶體不夠整頁,最後一頁剩下的空間)和外碎片(多次或者反覆分配造成中間的空閑頁太小不夠後續的一次分配)。
從上可以看出,在一定條件下,假如釋放了str3的記憶體,堆的大小是可以緊縮的。
最後我們以一張圖結束今天的主題,記憶體分配流程圖:
參考資料:
《Linux內核設計與實現》原書第三版
//www.cnblogs.com/bizhu/archive/2012/10/09/2717303.html


