Mapreduce學習(一)
MapReduce 介紹
簡單介紹:
MapReduce思想在生活中處處可見。或多或少都曾接觸過這種思想。MapReduce的思想核心
是「分而治之」,適用於大量複雜的任務處理場景(大規模數據處理場景)。
- Map負責「分」,即把複雜的任務分解為若干個「簡單的任務」來並行處理。可以進行拆分的
- 前提是這些小任務可以並行計算,彼此間幾乎沒有依賴關係。
- Reduce負責「合」,即對map階段的結果進行全局匯總。
- MapReduce運行在yarn集群
- 1. ResourceManager
- 2. NodeManager
這兩個階段合起來正是MapReduce思想的體現。
MapReduce 設計構思
MapReduce是一個分散式運算程式的編程框架,核心功能是將用戶編寫的業務邏輯程式碼和自
帶默認組件整合成一個完整的分散式運算程式,並發運行在Hadoop集群上。
MapReduce設計並提供了統一的計算框架,為程式設計師隱藏了絕大多數系統層面的處理細節。
為程式設計師提供一個抽象和高層的編程介面和框架。程式設計師僅需要關心其應用層的具體計算問
題,僅需編寫少量的處理應用本身計算問題的程式程式碼。如何具體完成這個並行計算任務所
相關的諸多系統層細節被隱藏起來,交給計算框架去處理:
Map和Reduce為程式設計師提供了一個清晰的操作介面抽象描述。MapReduce中定義了如下的Map
和Reduce兩個抽象的編程介面,由用戶去編程實現.Map和Reduce,MapReduce處理的數據類型
是<key,value>鍵值對。
Map: (k1; v1) → [(k2; v2)]
Reduce: (k2; [v2]) → [(k3; v3)]
一個完整的mapreduce程式在分散式運行時有三類實例進程:
1. MRAppMaster 負責整個程式的過程調度及狀態協調
2. MapTask 負責map階段的整個數據處理流程
3. ReduceTask 負責reduce階段的整個數據處理流程
MapReduce 編程規範
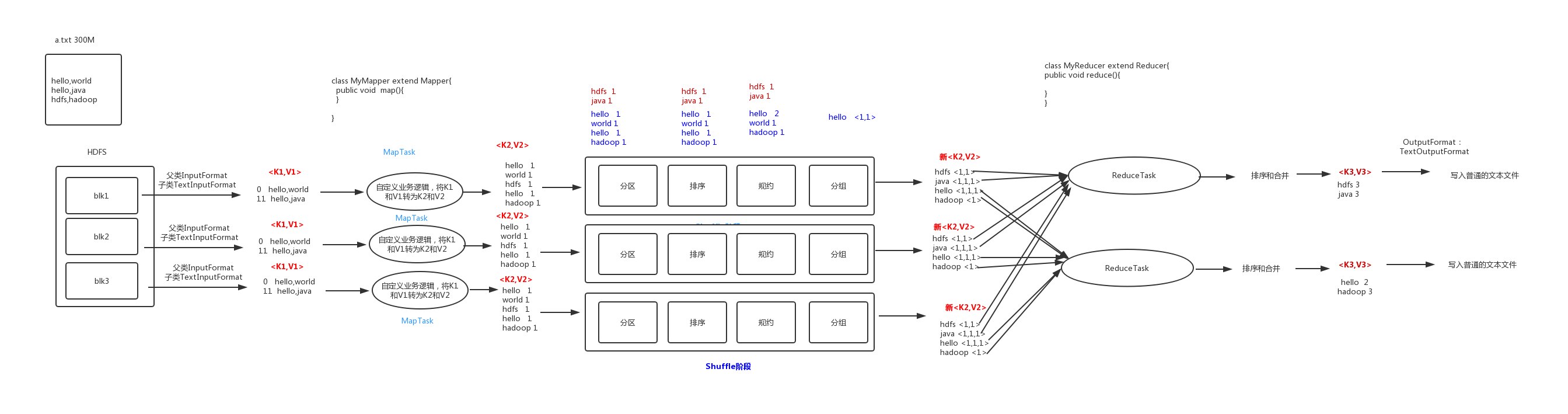
Map 階段 2 個步驟
1. 設置 InputFormat 類, 將數據切分為 Key-Value(K1和V1) 對, 輸入到第二步
2. 自定義 Map 邏輯, 將第一步的結果轉換成另外的 Key-Value(K2和V2) 對, 輸出結果
Shuffle 階段 4 個步驟
3. 對輸出的 Key-Value 對進行分區
4. 對不同分區的數據按照相同的 Key 排序
5. (可選) 對分組過的數據初步規約, 降低數據的網路拷貝
6. 對數據進行分組, 相同 Key 的 Value 放入一個集合中
Reduce 階段 2 個步驟
7. 對多個 Map 任務的結果進行排序以及合併, 編寫 Reduce 函數實現自己的邏輯, 對輸入的
Key-Value 進行處理, 轉為新的 Key-Value(K3和V3)輸出
8. 設置 OutputFormat 處理並保存 Reduce 輸出的 Key-Value 數據
WordCount單詞統計實戰
程式碼編寫
數據準備:在Hadoop101客戶端上寫一個文件上傳到hadoop

WordCountMapper
package cn.itcast.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable>{
//map方法就是將k1和v1轉為k2和v2
/*
參數:
key:K1 行偏移量
value: v1 每一行的文本數據
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text text = new Text();
LongWritable longWritable = new LongWritable();
//1.將一行的文本數據進行拆分
String[] split = value.toString().split(",");
//2.遍曆數組,組裝K2和V2
for (String word:split){
//3.將K2和V2寫入上下文
text.set(word);
longWritable.set(1);
context.write(text,longWritable);
}
}
}
WordCountReduce
package cn.itcast.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.awt.*;
import java.io.IOException;
public class WordCountReduce extends Reducer<Text,LongWritable,Text,LongWritable> {
//reduce將K2和V2轉為K3和V3,將K3和V3寫入上下文中
/*
參數:
key:新K2
values:結合 新V2
context:表示上下文對象
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//1.便利結合,將集合中的數字相加,得到V3
long count=0;
for (LongWritable value : values) {
count+=value.get();
}
//2.將K3和V3寫入上下文中
context.write(key,new LongWritable(count));
}
}
JobMain
package cn.itcast.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class JobMain extends Configured implements Tool {
//該方法用於指定一個job任務
@Override
public int run(String[] strings) throws Exception {
//1.創建一個job任務對象
Job job = Job.getInstance(super.getConf(),"wordcount");
//2.配置job任務對象(八個步驟)
//打包jar路徑主類
job.setJarByClass(JobMain.class);
//第一步:指定文件的讀取方式和讀取路徑
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://hadoop101:8020/wordcount"));
//本地測試元數據
//TextInputFormat.addInputPath(job,new Path("file:///E:\\mapreduce\\input"));
//第二步:指定map階段的處理方式和數據類型
job.setMapperClass(WordCountMapper.class);
//設置Map階段K2的類型
job.setMapOutputKeyClass(Text.class);
//設置Map階段V2的類型
job.setMapOutputValueClass(LongWritable.class);
//第三,四,五,六採用默認方式
//第七步:指定reduce階段的處理方式和數據類型
job.setReducerClass(WordCountReduce.class);
//設置K3的類型
job.setOutputKeyClass(Text.class);
//設置V3的類型
job.setOutputValueClass(LongWritable.class);
//第八步:設置輸出類型
job.setOutputFormatClass(TextOutputFormat.class);
//設置輸出的路徑
Path path = new Path("hdfs://hadoop101:8020/wordcount_out");
TextOutputFormat.setOutputPath(job,path);
//本地測試輸出
//TextOutputFormat.setOutputPath(job,new Path("file:///E:\\mapreduce\\output"));
//獲取filesystem
FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop101:8020"), new Configuration());
//判斷目錄存在
boolean bl2=fileSystem.exists(path);
if(bl2){
fileSystem.delete(path,true);
}
//等待任務結束
boolean bl=job.waitForCompletion(true);
return bl?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//1.啟動job任務
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
程式運行方式
①打包成jar包,然後上傳到linux伺服器,用命令來運行

hadoop jar 包名 程式主程式路徑
②在程式里進行測試,首先得有本地的存儲測試input的文件路徑,然後定義一個輸出路徑(該路徑必須不存在,否則會報錯)
//本地測試元數據
TextInputFormat.addInputPath(job,newPath("file:///E:\\mapreduce\\input"));
//本地測試輸出
TextOutputFormat.setOutputPath(job,new Path("file:///E:\\mapreduce\\output"));
程式運行結果

源數據文件內容(input):

運行輸出結果(output):



