Mapreduce学习(一)
MapReduce 介绍
简单介绍:
MapReduce思想在生活中处处可见。或多或少都曾接触过这种思想。MapReduce的思想核心
是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。
- Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的
- 前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
- Reduce负责“合”,即对map阶段的结果进行全局汇总。
- MapReduce运行在yarn集群
- 1. ResourceManager
- 2. NodeManager
这两个阶段合起来正是MapReduce思想的体现。
MapReduce 设计构思
MapReduce是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自
带默认组件整合成一个完整的分布式运算程序,并发运行在Hadoop集群上。
MapReduce设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统层面的处理细节。
为程序员提供一个抽象和高层的编程接口和框架。程序员仅需要关心其应用层的具体计算问
题,仅需编写少量的处理应用本身计算问题的程序代码。如何具体完成这个并行计算任务所
相关的诸多系统层细节被隐藏起来,交给计算框架去处理:
Map和Reduce为程序员提供了一个清晰的操作接口抽象描述。MapReduce中定义了如下的Map
和Reduce两个抽象的编程接口,由用户去编程实现.Map和Reduce,MapReduce处理的数据类型
是<key,value>键值对。
Map: (k1; v1) → [(k2; v2)]
Reduce: (k2; [v2]) → [(k3; v3)]
一个完整的mapreduce程序在分布式运行时有三类实例进程:
1. MRAppMaster 负责整个程序的过程调度及状态协调
2. MapTask 负责map阶段的整个数据处理流程
3. ReduceTask 负责reduce阶段的整个数据处理流程
MapReduce 编程规范
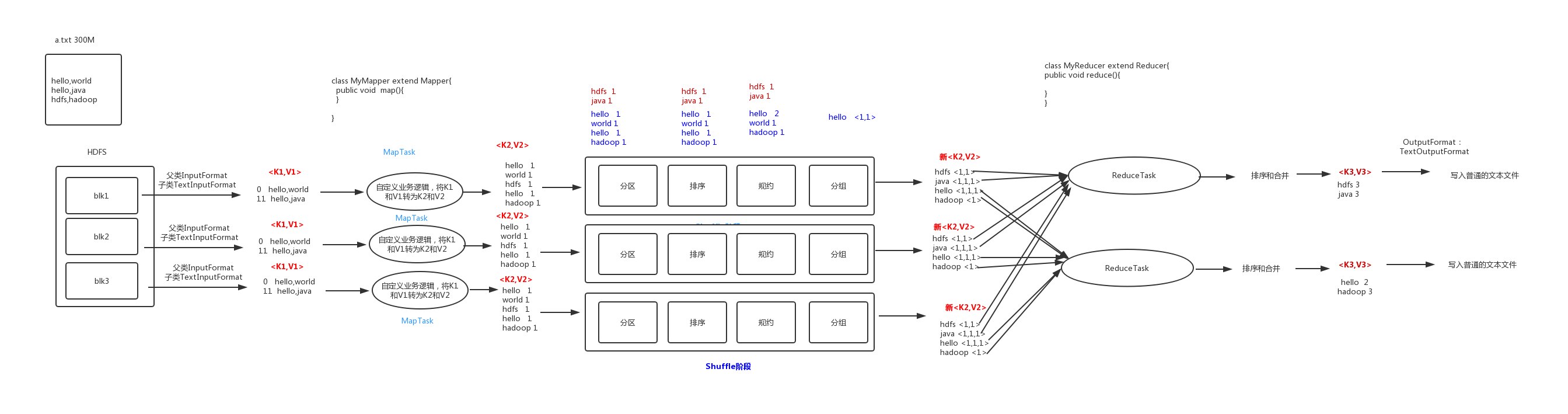
Map 阶段 2 个步骤
1. 设置 InputFormat 类, 将数据切分为 Key-Value(K1和V1) 对, 输入到第二步
2. 自定义 Map 逻辑, 将第一步的结果转换成另外的 Key-Value(K2和V2) 对, 输出结果
Shuffle 阶段 4 个步骤
3. 对输出的 Key-Value 对进行分区
4. 对不同分区的数据按照相同的 Key 排序
5. (可选) 对分组过的数据初步规约, 降低数据的网络拷贝
6. 对数据进行分组, 相同 Key 的 Value 放入一个集合中
Reduce 阶段 2 个步骤
7. 对多个 Map 任务的结果进行排序以及合并, 编写 Reduce 函数实现自己的逻辑, 对输入的
Key-Value 进行处理, 转为新的 Key-Value(K3和V3)输出
8. 设置 OutputFormat 处理并保存 Reduce 输出的 Key-Value 数据
WordCount单词统计实战
代码编写
数据准备:在Hadoop101客户端上写一个文件上传到hadoop

WordCountMapper
package cn.itcast.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable>{
//map方法就是将k1和v1转为k2和v2
/*
参数:
key:K1 行偏移量
value: v1 每一行的文本数据
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text text = new Text();
LongWritable longWritable = new LongWritable();
//1.将一行的文本数据进行拆分
String[] split = value.toString().split(",");
//2.遍历数组,组装K2和V2
for (String word:split){
//3.将K2和V2写入上下文
text.set(word);
longWritable.set(1);
context.write(text,longWritable);
}
}
}
WordCountReduce
package cn.itcast.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.awt.*;
import java.io.IOException;
public class WordCountReduce extends Reducer<Text,LongWritable,Text,LongWritable> {
//reduce将K2和V2转为K3和V3,将K3和V3写入上下文中
/*
参数:
key:新K2
values:结合 新V2
context:表示上下文对象
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//1.便利结合,将集合中的数字相加,得到V3
long count=0;
for (LongWritable value : values) {
count+=value.get();
}
//2.将K3和V3写入上下文中
context.write(key,new LongWritable(count));
}
}
JobMain
package cn.itcast.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class JobMain extends Configured implements Tool {
//该方法用于指定一个job任务
@Override
public int run(String[] strings) throws Exception {
//1.创建一个job任务对象
Job job = Job.getInstance(super.getConf(),"wordcount");
//2.配置job任务对象(八个步骤)
//打包jar路径主类
job.setJarByClass(JobMain.class);
//第一步:指定文件的读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://hadoop101:8020/wordcount"));
//本地测试元数据
//TextInputFormat.addInputPath(job,new Path("file:///E:\\mapreduce\\input"));
//第二步:指定map阶段的处理方式和数据类型
job.setMapperClass(WordCountMapper.class);
//设置Map阶段K2的类型
job.setMapOutputKeyClass(Text.class);
//设置Map阶段V2的类型
job.setMapOutputValueClass(LongWritable.class);
//第三,四,五,六采用默认方式
//第七步:指定reduce阶段的处理方式和数据类型
job.setReducerClass(WordCountReduce.class);
//设置K3的类型
job.setOutputKeyClass(Text.class);
//设置V3的类型
job.setOutputValueClass(LongWritable.class);
//第八步:设置输出类型
job.setOutputFormatClass(TextOutputFormat.class);
//设置输出的路径
Path path = new Path("hdfs://hadoop101:8020/wordcount_out");
TextOutputFormat.setOutputPath(job,path);
//本地测试输出
//TextOutputFormat.setOutputPath(job,new Path("file:///E:\\mapreduce\\output"));
//获取filesystem
FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop101:8020"), new Configuration());
//判断目录存在
boolean bl2=fileSystem.exists(path);
if(bl2){
fileSystem.delete(path,true);
}
//等待任务结束
boolean bl=job.waitForCompletion(true);
return bl?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//1.启动job任务
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
程序运行方式
①打包成jar包,然后上传到linux服务器,用命令来运行

hadoop jar 包名 程序主程序路径
②在程序里进行测试,首先得有本地的存储测试input的文件路径,然后定义一个输出路径(该路径必须不存在,否则会报错)
//本地测试元数据
TextInputFormat.addInputPath(job,newPath("file:///E:\\mapreduce\\input"));
//本地测试输出
TextOutputFormat.setOutputPath(job,new Path("file:///E:\\mapreduce\\output"));
程序运行结果

源数据文件内容(input):

运行输出结果(output):



