常見激活函數的介紹和總結
1、激活函數的概念
神經網路中的每個神經元節點接受上一層神經元的輸出值作為本神經元的輸入值,並將輸入值傳遞給下一層,輸入層神經元節點會將輸入屬性值直接傳遞給下一層(隱層或輸出層)。在多層神經網路中,上層節點的輸出和下層節點的輸入之間具有一個函數關係,這個函數稱為激活函數Activation Function(又稱激勵函數)。
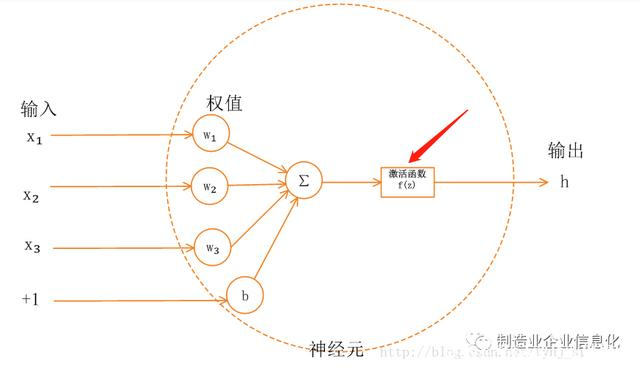
2、激活函數的本質和作用
激活函數是來向神經網路中引入非線性因素的,通過激活函數,神經網路就可以擬合各種曲線。如果不用激勵函數,每一層輸出都是上層輸入的線性函數,無論神經網路有多少層,輸出都是輸入的線性組合。如果使用的話,激活函數給神經元引入了非線性因素,使得神經網路可以任意逼近任何非線性函數,這樣神經網路就可以應用到眾多的非線性模型中。
為了解釋激活函數如何引入非線性因素,接下來讓我們以神經網路分割平面空間作為例子。
(1)無激活函數的神經網路
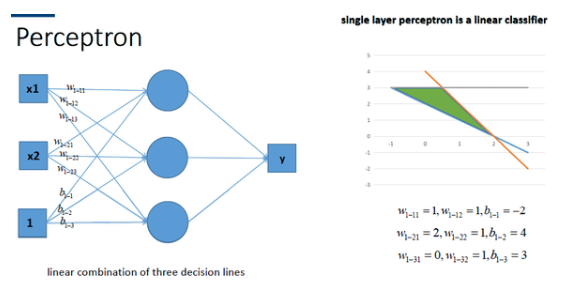
神經網路最簡單的結構就是單輸出的單層感知機,單層感知機只有輸入層和輸出層,分別代表了神經感受器和神經中樞。下圖是一個只有2個輸入單元和1個輸出單元的簡單單層感知機。圖中x1、w2代表神經網路的輸入神經元受到的刺激,w1、w2代表輸入神經元和輸出神經元間連接的緊密程度,b代表輸出神經元的興奮閾值,y為輸出神經元的輸出。我們使用該單層感知機划出一條線將平面分割開,如圖所示:

同理,我們也可以將多個感知機(注意,不是多層感知機)進行組合獲得更強的平面分類能力,如圖所示:
再看看包含一個隱層的多層感知機的情況,如圖所示:
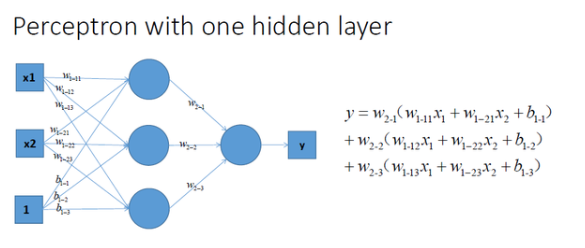
通過對比可以發現,上面三種沒有激勵函數的神經網路的輸出是都線性方程,其都是在用複雜的線性組合來試圖逼近曲線。
(2)帶激活函數的神經網路
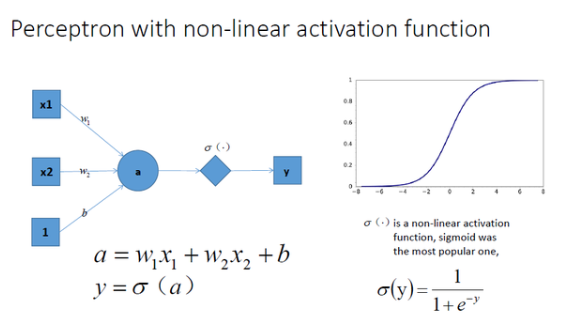
讓我們在神經網路每一層神經元做完線性變換以後,加上一個非線性激勵函數對線性變換的結果進行轉換,結果顯而易見,輸出立馬變成一個不折不扣的非線性函數了,如圖所示:
拓展到多層神經網路的情況, 和剛剛一樣的結構, 加上非線性激勵函數之後, 輸出就變成了一個複雜的非線性函數了,如圖所示:
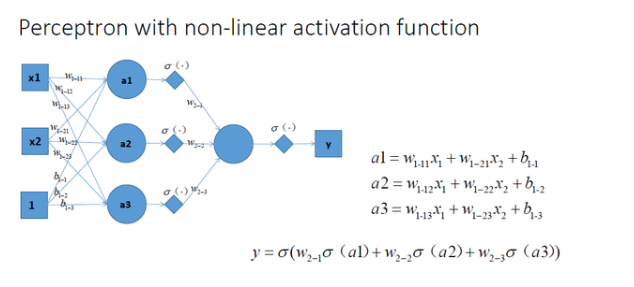
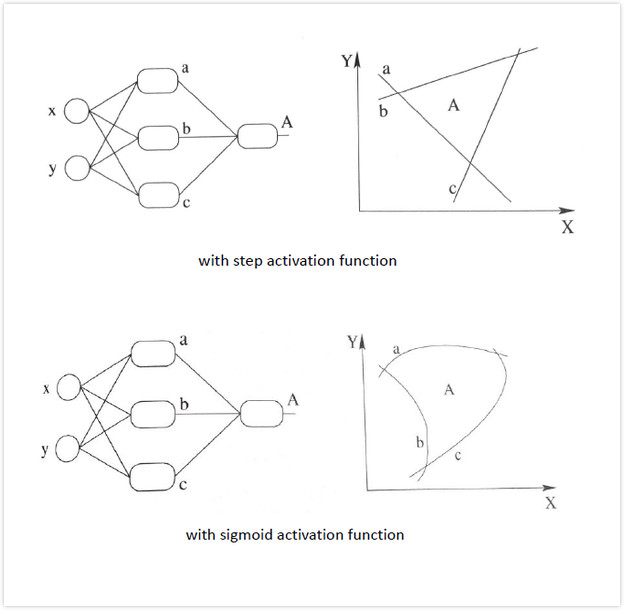
總結:加入非線性激勵函數後,神經網路就有可能學習到平滑的曲線來分割平面,而不是用複雜的線性組合逼近平滑曲線來分割平面,使神經網路的表示能力更強了,能夠更好的擬合目標函數。 這就是為什麼我們要有非線性的激活函數的原因。如下圖所示說明加入非線性激活函數後的差異,上圖為用線性組合逼近平滑曲線來分割平面,下圖為平滑的曲線來分割平面:
3、幾種常見的激活函數
3.1 sigmoid函數
公式:

曲線:

Sigmoid函數也叫 Logistic 函數,用於隱層神經元輸出,取值範圍為(0,1)。它可以將一個實數映射到(0,1)的區間,可以用來做二分類。在特徵相差比較複雜或是相差不是特別大時效果比較好。
Sigmoid函數在歷史上曾經非常的常用,輸出值範圍為[0,1]之間的實數。但是現在它已經不太受歡迎,實際中很少使用。原因是sigmoid存在3個問題:
1)sigmoid函數飽和使梯度消失(Sigmoidsaturate and kill gradients)。我們從導函數影像中可以看出sigmoid的導數都是小於0.25的,那麼在進行反向傳播的時候,梯度相乘結果會慢慢的趨近於0。這樣,幾乎就沒有梯度訊號通過神經元傳遞到前面層的梯度更新中,因此這時前面層的權值幾乎沒有更新,這就叫梯度消失。除此之外,為了防止飽和,必須對於權重矩陣的初始化特別留意。如果初始化權重過大,可能很多神經元得到一個比較小的梯度,致使神經元不能很好的更新權重提前飽和,神經網路就幾乎不學習。
2)sigmoid函數輸出不是「零為中心」(zero-centered)。一個多層的sigmoid神經網路,如果你的輸入x都是正數,那麼在反向傳播中w的梯度傳播到網路的某一處時,權值的變化是要麼全正要麼全負。
如上圖所示:當梯度從上層傳播下來,w的梯度都是用x乘以f的梯度,因此如果神經元輸出的梯度是正的,那麼所有w的梯度就會是正的,反之亦然。在這個例子中,我們會得到兩種權值,權值範圍分別位於圖8中一三象限。當輸入一個值時,w的梯度要麼都是正的要麼都是負的,當我們想要輸入一三象限區域以外的點時,我們將會得到這種並不理想的曲折路線(zig zag path),圖中紅色曲折路線。假設最優化的一個w矩陣是在圖8中的第四象限,那麼要將w優化到最優狀態,就必須走「之字形」路線,因為你的w要麼只能往下走(負數),要麼只能往右走(正的)。優化的時候效率十分低下,模型擬合的過程就會十分緩慢。 3)指數函數的計算是比較消耗計算資源的。其解析式中含有冪運算,電腦求解時相對來講比較耗時。對於規模比較大的深度網路,這會較大地增加訓練時間。
3.2 Tanh函數
tanh函數跟sigmoid還是很像的,實際上,tanh是sigmoid的變形,如公式5所示。tanh的具體公式如下:
$f(x)=tanh(x)\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}$
$tanh(x)=2sigmoid(2x)-1$
tanh函數及其導數的幾何影像如下圖:
tanh讀作Hyperbolic Tangent,它解決了Sigmoid函數的不是zero-centered輸出問題,tanh是「零為中心」的。因此,實際應用中,tanh會比sigmoid更好一些。但是在飽和神經元的情況下,tanh還是沒有解決梯度消失問題。
優點:tanh解決了sigmoid的輸出非「零為中心」的問題
缺點:(1)依然有sigmoid函數過飽和的問題。(2)依然進行的是指數運算。
3.3 ReLU
近年來,ReLU函數變得越來越受歡迎。全稱是Rectified Linear Unit,中文名字:修正線性單元。ReLU是Krizhevsky、Hinton等人在2012年《ImageNet Classification with Deep Convolutional Neural Networks》論文中提出的一種線性且不飽和的激活函數。它的數學表達式如7所示
![]()
函數影像如下圖所示:
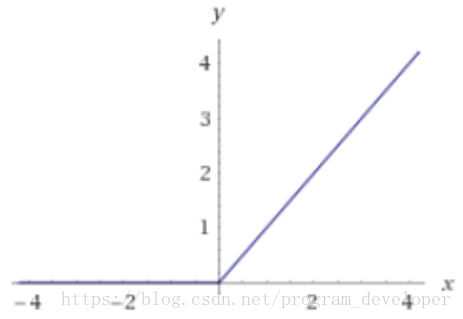
優點:(1)ReLU解決了梯度消失的問題,至少x在正區間內,神經元不會飽和;(2)由於ReLU線性、非飽和的形式,在SGD中能夠快速收斂;(3)算速度要快很多。ReLU函數只有線性關係,不需要指數計算,不管在前向傳播還是反向傳播,計算速度都比sigmoid和tanh快。
缺點:(1)ReLU的輸出不是「零為中心」(Notzero-centered output)。(2)隨著訓練的進行,可能會出現神經元死亡,權重無法更新的情況。這種神經元的死亡是不可逆轉的死亡。
總結:訓練神經網路的時候,一旦學習率沒有設置好,第一次更新權重的時候,輸入是負值,那麼這個含有ReLU的神經節點就會死亡,再也不會被激活。因為:ReLU的導數在x>0的時候是1,在x<=0的時候是0。如果x<=0,那麼ReLU的輸出是0,那麼反向傳播中梯度也是0,權重就不會被更新,導致神經元不再學習。也就是說,這個ReLU激活函數在訓練中將不可逆轉的死亡,導致了訓練數據多樣化的丟失。在實際訓練中,如果學習率設置的太高,可能會發現網路中40%的神經元都會死掉,且在整個訓練集中這些神經元都不會被激活。所以,設置一個合適的較小的學習率,會降低這種情況的發生。所以必須設置一個合理的學習率。為了解決神經元節點死亡的情況,有人提出了Leaky ReLU、P-ReLu、R-ReLU、ELU等激活函數。
引出的問題:神經網路中ReLU是線性還是非線性函數?為什麼relu這種「看似線性」(分段線性)的激活函數所形成的網路,居然能夠增加非線性的表達能力?
(1)relu是非線性激活函數。
(2)讓我們先明白什麼是線性網路?如果把線性網路看成一個大的矩陣M。那麼輸入樣本A和B,則會經過同樣的線性變換MA,MB(這裡A和B經歷的線性變換矩陣M是一樣的)
(3)的確對於單一的樣本A,經過由relu激活函數所構成神經網路,其過程確實可以等價是經過了一個線性變換M1,但是對於樣本B,在經過同樣的網路時,由於每個神經元是否激活(0或者Wx+b)與樣本A經過時情形不同了(不同樣本),因此B所經歷的線性變換M2並不等於M1。因此,relu構成的神經網路雖然對每個樣本都是線性變換,但是不同樣本之間經歷的線性變換M並不一樣,所以整個樣本空間在經過relu構成的網路時其實是經歷了非線性變換的。
3.3.1 Leaky ReLU
ReLU是將所有的負值設置為0,造成神經元節點死亡情況。相反,Leaky ReLU是給所有負值賦予一個非零的斜率。Leaky ReLU激活函數是在聲學模型(2013)中首次提出來的。它的數學表達式如公式8所示:
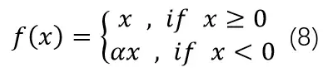
其影像如下圖:
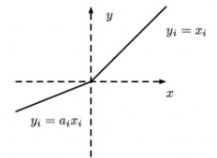
優點:
(1)神經元不會出現死亡的情況。
(2)對於所有的輸入,不管是大於等於0還是小於0,神經元不會飽和。
(3)由於Leaky ReLU線性、非飽和的形式,在SGD中能夠快速收斂。
(4)計算速度要快很多。Leaky ReLU函數只有線性關係,不需要指數計算,不管在前向傳播還是反向傳播,計算速度都比sigmoid和tanh快。
缺點:(1).Leaky ReLU函數中的α,需要通過先驗知識人工賦值。
總結:Leaky ReLU很好的解決了「dead ReLU」的問題。因為Leaky ReLU保留了x小於0時的梯度,在x小於0時,不會出現神經元死亡的問題。對於Leaky ReLU給出了一個很小的負數梯度值α,這個值是很小的常數。比如:0.01。這樣即修正了數據分布,又保留了一些負軸的值,使得負軸資訊不會全部丟失。但是這個α通常是通過先驗知識人工賦值的。
3.3.2 RReLU
RReLU的英文全稱是「Randomized Leaky ReLU」,中文名字叫「隨機修正線性單元」。RReLU是Leaky ReLU的隨機版本。它首次是在Kaggle的NDSB比賽中被提出來的,其影像和表達式如下圖所示:
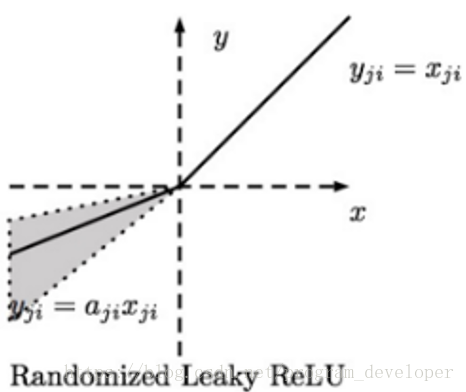

RReLU的核心思想是,在訓練過程中,α是從一個高斯分布U(l,u)中隨機出來的值,然後再在測試過程中進行修正。在測試階段,把訓練過程中所有的aji取個平均值。
特點:
(1)RReLU是Leaky ReLU的random版本,在訓練過程中,α是從一個高斯分布中隨機出來的,然後再測試過程中進行修正。
(2)數學形式與PReLU類似,但RReLU是一種非確定性激活函數,其參數是隨機的
3.3.3 ReLU、Leaky ReLU、PReLU和RReLU的比較
各自影像如下圖所示:

總結:
(1)PReLU中的α是根據數據變化的;
(2)Leaky ReLU中的α是固定的;
(3)RReLU中的α是一個在給定範圍內隨機抽取的值,這個值在測試環節就會固定下來。
3.4 ELU
ELU的英文全稱是「Exponential Linear Units」,中文全稱是「指數線性單元」。它試圖將激活函數的輸出平均值接近零,從而加快學習速度。同時,它還能通過正值的標識來避免梯度消失的問題。根據一些研究顯示,ELU分類精確度是高於ReLU的。公式如12式所示。
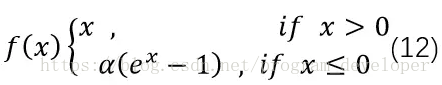
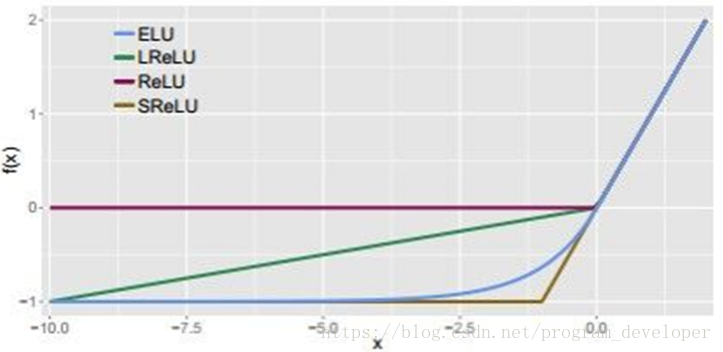
ELU與其他幾種激活函數的比較圖:
優點:
(1)ELU包含了ReLU的所有優點。
(2)神經元不會出現死亡的情況。
(3)ELU激活函數的輸出均值是接近於零的。
缺點:
(1)計算的時候是需要計算指數的,計算效率低的問題。
3.5 Maxout
Maxout 「Neuron」 是由Goodfellow等人在2013年提出的一種很有特點的神經元,它的激活函數、計算的變數、計算方式和普通的神經元完全不同,並有兩組權重。先得到兩個超平面,再進行最大值計算。激活函數是對ReLU和Leaky ReLU的一般化歸納,沒有ReLU函數的缺點,不會出現激活函數飽和神經元死亡的情況。Maxout出現在ICML2013上,作者Goodfellow將maxout和dropout結合,稱在MNIST,CIFAR-10,CIFAR-100,SVHN這4個數據集上都取得了start-of-art的識別率。Maxout公式如下所示:
$f_{i}(x)=max_{j\epsilon [1,k]}z_{ij}$
其中$z_{ij}=x^{T}W_{…ij}+b_{ij}$,假設w是2維的,那麼我們可以得出公式如下:
$f(x)=max(w_{1}^{T}x+b_{1},w_{2}^{T}x+b_{2})$
分析上式可以注意到,ReLU和Leaky ReLU都是它的一個變形。比如的時候,就是ReLU。Maxout的擬合能力非常強,它可以擬合任意的凸函數。Goodfellow在論文中從數學的角度上也證明了這個結論,只需要2個Maxout節點就可以擬合任意的凸函數,前提是「隱含層」節點的個數足夠多。
優點:
(1)Maxout具有ReLU的所有優點,線性、不飽和性。
(2)同時沒有ReLU的一些缺點。如:神經元的死亡。
缺點:
(1)從這個激活函數的公式14中可以看出,每個neuron將有兩組w,那麼參數就增加了一倍。這就導致了整體參數的數量激增。
3.6 softmax函數
Softmax – 用於多分類神經網路輸出,公式 為:


為什麼要取指數,第一個原因是要模擬 max 的行為,所以要讓大的更大。第二個原因是需要一個可導的函數。
4、 sigmoid ,ReLU, softmax 的比較
Sigmoid 和 ReLU 比較:
sigmoid 的梯度消失問題,ReLU 的導數就不存在這樣的問題,它的導數表達式如下:


對比sigmoid類函數主要變化是:
1)單側抑制
2)相對寬闊的興奮邊界
3)稀疏激活性。
Sigmoid 和 Softmax 區別:
softmax is a generalization of logistic function that 「squashes」(maps) a K-dimensional vector z of arbitrary real values to a K-dimensional vector σ(z) of real values in the range (0, 1) that add up to 1。sigmoid將一個real value映射到(0,1)的區間,用來做二分類。而 softmax 把一個 k 維的real value向量(a1,a2,a3,a4….)映射成一個(b1,b2,b3,b4….)其中 bi 是一個 0~1 的常數,輸出神經元之和為 1.0,所以相當於概率值,然後可以根據 bi 的概率大小來進行多分類的任務。二分類問題時 sigmoid 和 softmax 是一樣的,求的都是 cross entropy loss,而 softmax 可以用於多分類問題
softmax是sigmoid的擴展,因為,當類別數 k=2 時,softmax 回歸退化為 logistic 回歸。具體地說,當 k=2 時,softmax 回歸的假設函數為:



另一個類別概率的為:

這與 logistic回歸是一致的。
softmax建模使用的分布是多項式分布,而logistic則基於伯努利分布。多個logistic回歸通過疊加也同樣可以實現多分類的效果,但是 softmax回歸進行的多分類,類與類之間是互斥的,即一個輸入只能被歸為一類;多個logistic回歸進行多分類,輸出的類別並不是互斥的,即”蘋果”這個詞語既屬於”水果”類也屬於”3C”類別。
5、如何選擇合適的激活函數
如何選擇合適的激活函數,目前還不存在定論,在實踐過程中更多還是需要結合實際情況,考慮不同激活函數的優缺點綜合使用。
(1)通常來說,不能把各種激活函數串起來在一個網路中使用。
(2)如果使用ReLU,那麼一定要小心設置學習率(learning rate),並且要注意不要讓網路中出現很多死亡神經元。如果死亡神經元過多的問題不好解決,可以試試Leaky ReLU、PReLU、或者Maxout。
(3)盡量不要使用sigmoid激活函數,可以試試tanh,不過tanh的效果會比不上ReLU和Maxout。
參考:
//www.cnblogs.com/XDU-Lakers/p/10557496.html
//baijiahao.baidu.com/s?id=1665988111893224009&wfr=spider&for=pc
//www.jianshu.com/p/22d9720dbf1a


