一個關於內聯優化和調用約定的Bug
- 2019 年 10 月 23 日
- 筆記
很久沒有更新部落格了(部落格園怎麼還不更新後台),前幾天在寫一個Linux 0.11的實驗 [1] 時遇到了一個奇葩的Bug,就在這簡單記錄一下調試過程吧。
現象
這個實驗要求在Linux 0.11中實現簡單的訊號量 [2],但在改動內核程式碼後運行測試程式總是報錯,例如:
/* pc_test.c */ #define __LIBRARY__ #include <stdio.h> #include <stdlib.h> #include <semaphore.h> #include <unistd.h> _syscall2(long, sem_open, const char *, name, unsigned int, value); _syscall1(int, sem_unlink, const char *, name); int main(void) { sem_t *mutex; if ((mutex = (sem_t *) sem_open("mutex", 1)) == (sem_t *)-1) { perror("opening mutex semaphore creating"); return EXIT_FAILURE; } sem_unlink("mutex"); return EXIT_SUCCESS; } 提示為段錯誤:

定位
在內核實現訊號量的核心程式碼 sem.c 中插樁調試,最終把發生段錯誤的位置定在尋找已存在訊號量的 find_sem 函數中:
/* 以下注釋部分是semaphore.h中我定義的鏈表結構體 #define MAXSEMNAME 128 struct sem_t { char m_name[MAXSEMNAME+1]; unsigned long m_value; struct sem_t * m_prev; struct sem_t * m_next; struct task_struct * m_wait; }; typedef struct sem_t sem_t; #define SEM_FAILED ((sem_t *)-1) */ // Data structure optimization is possible here sem_t _semHead={.m_name = "_semHead", .m_value = 0, .m_prev = NULL, .m_next = NULL, .m_wait = NULL}; sem_t *find_sem(const char* name) { sem_t *tmpSemP = &_semHead; while (tmpSemP->m_next != NULL) { if (strcmp((tmpSemP->m_name), name) == 0) { return tmpSemP; } tmpSemP = tmpSemP->m_next; } return tmpSemP; }由於該函數中存在 P->member 這樣的解引用操作,很大概率就是P的值出了問題,所以就在P對應的操作附近加上 printk ,判斷是否進一步定位Bug:
sem_t *find_sem(const char* name) { printk("Now we are in find_semn"); // DEBUG sem_t *tmpSemP = &_semHead; while (tmpSemP->m_next != NULL) { printk("find_sem: tmpSemp before strcmp: %pn", tmpSemP); if (strcmp((tmpSemP->m_name), name) == 0) { printk("find_sem: tmpSemp after strcmp: %pn", tmpSemP); // DEBUG printk("find_sem: return...nn"); // DEBUG return tmpSemP; } printk("find_sem: tmpSemp after strcmp: %pnn", tmpSemP); // DEBUG tmpSemP = tmpSemP->m_next; } printk("find_sem: return...nn"); // DEBUG return tmpSemP; }重新編譯內核,再次運行上面的 pc_test.c ,奇怪的事情發生了:
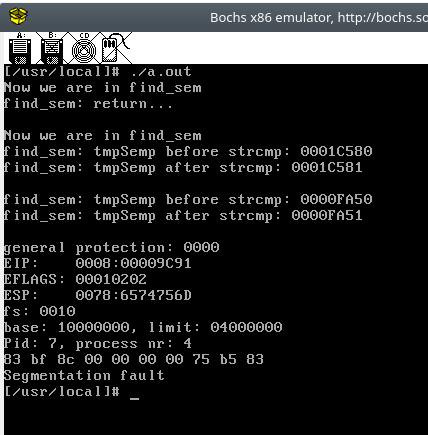
可以看到,第一次進入 find_sem 並沒有發生段錯誤,這是因為第一次調用 sem_open 的時候內核中還沒有訊號量,所以 tmpSemP->m_next != NULL 不成立,但是第二次和第三次進入 find_sem ,temSemP 的值卻在 strcmp(tmpSemP->m_name, name) 前後發生了改變。我們知道,C中的函數參數是「按值傳遞」的,如果編譯器真的把strcmp 按照C函數的規則編譯,那麼傳遞 m_name 的值, tmpSemP 的值是不可能改變的。所以現在的結論是, string.h 中定義的 strcmp 很可能出了問題。
復現
為了更好的分析和調試,我將 string.h , semaphore.h 和 sem.c 中的 find_sem 關鍵程式碼拿出來,精簡後在用戶態進行Bug復現:
/* test.c */ #include <stdio.h> // string.h inline int strcmp(const char * cs,const char * ct) { register int __res ; __asm__("cldn" "1:tlodsbnt" "scasbnt" "jne 2fnt" "testb %%al,%%alnt" "jne 1bnt" "xorl %%eax,%%eaxnt" "jmp 3fn" "2:tmovl $1,%%eaxnt" "jl 3fnt" "negl %%eaxn" "3:" :"=a" (__res):"D" (cs),"S" (ct)); return __res; } //semaphore.h typedef struct sem_t { char m_name[128]; struct sem_t *m_next; } sem_t; //sem.c int main(void) { sem_t _semRear={.m_name = "_semRear", .m_next = (sem_t *)0}; sem_t _semHead={.m_name = "_semHead", .m_next = &_semRear}; sem_t *tmpSemP = &_semHead; char name[] = "test"; while (tmpSemP->m_next != (sem_t *)0) { printf("1. tempSemP: %pn", tmpSemP); if(!strcmp((tmpSemP->m_name), name)) return 0; printf("2. tempSemP: %pn", tmpSemP); tmpSemP = tmpSemP->m_next; } return 0; }Bug復現:
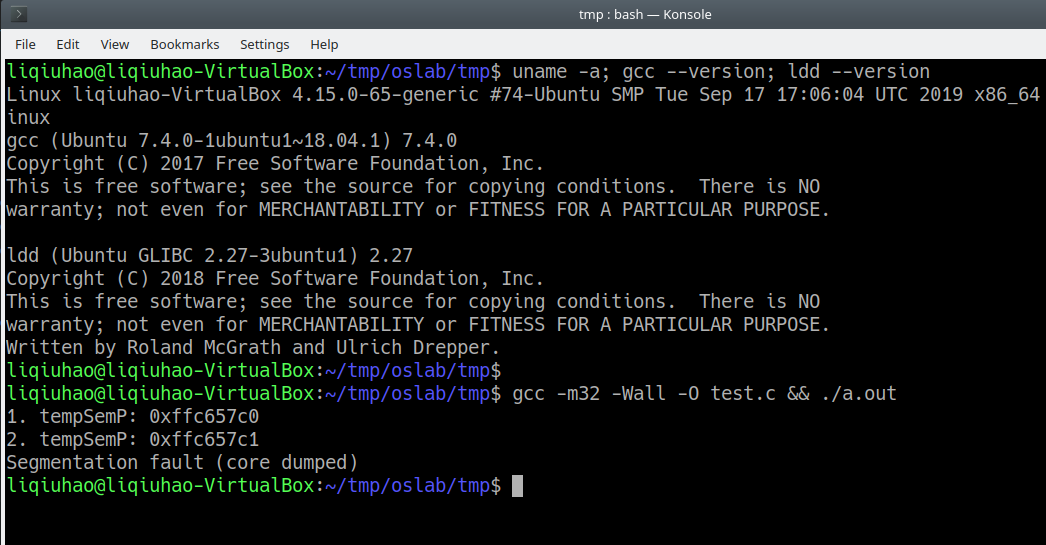
分析
我們首先分析一下 strcmp 的實現:
extern inline int strcmp(const char * cs,const char * ct) { register int __res ; // 暫存器變數 __asm__("cldn" // 清理方向位 "1:tlodsbnt" // 將ds:[esi]存入al,esi++ "scasbnt" // 比較al與es:[edi],edi++ "jne 2fnt" // 若不等,向下跳轉到2標誌 "testb %%al,%%alnt" // 測試al暫存器 "jne 1bnt" // 若al不為0,則向上跳轉到1標誌 "xorl %%eax,%%eaxnt" // 若al為零,則清空eax(返回值) "jmp 3fn" // 向下跳轉到3標誌返回 "2:tmovl $1,%%eaxnt" // eax置為1 "jl 3fnt" // 若上面的比較al更小,則這裡返回正值(1) "negl %%eaxnt" // 否則eax = -1 返回負值 "3:" :"=a" (__res):"D" (cs),"S" (ct)); // 規定edi暫存器接收cs參數的值,esi接收ct參數的值,最終將eax的值輸出到__res暫存器變數中 return __res; // 返回__res }如上,為了性能優化, strcmp 使用了內聯優化(函數和彙編),是程式碼還是編譯器的鍋呢?拖入IDA,靜態分析一下:

編譯器忠實的保留了內聯彙編的語句。通過 __printf_chk 的參數,我們知道進入控制流進入 strcmp 之前和之後編譯器都把 tempSemP 放在暫存器 edi 中,並且由於訊號量結構體的第一個成員就是 m_name :
//semaphore.h typedef struct sem_t { char m_name[128]; struct sem_t *m_next; } sem_t;而 m_name 又是一個數組名,所以 tmpSemP->m_name 和 tmpSemP 就值而言是相同的。由於內聯彙編規定使用 edi 作為第一個參數的輸入暫存器,所以編譯器為了優化,首先就將 tempSemP 放在暫存器 edi ,這樣後面進入 strcmp 的時候就不需要再次改變 edi 了 。
但是,內聯彙編的程式碼中明明有 scasb [3] ,其會在比較操作後更改 edi 的值,難道編譯器不知道嗎?通過查閱GCC文檔關於內聯彙編的說明 [4]:
asm asm-qualifiers ( AssemblerTemplate : OutputOperands [ : InputOperands [ : Clobbers ] ])6.47.2.6 Clobbers and Scratch Registers
While the compiler is aware of changes to entries listed in the output operands, the inline
asmcode may modify more than just the outputs. For example, calculations may require additional registers, or the processor may overwrite a register as a side effect of a particular assembler instruction. In order to inform the compiler of these changes, list them in the clobber list. Clobber list items are either register names or the special clobbers (listed below). Each clobber list item is a string constant enclosed in double quotes and separated by commas.Clobber descriptions may not in any way overlap with an input or output operand….
文檔說明了對於彙編語句中被修改但是不在 InputOperands中的暫存器,應該在 Clobbers 中寫出,不然編譯器不知道哪些暫存器(Bug這裡是 edi )被修改,也就可能在優化的過程中出錯了。
回到 strcmp 的程式碼,最後一行是:"=a" (__res):"D" (cs),"S" (ct)); ,而scasb 與 lodsb [5] 修改的又是 edi , esi 。根據上面文檔的說明, clobbers 不能與輸入輸出位置的操作數重複,所以如果這裡在 clobbers 的位置放上 edi , esi 就會報錯:

(這個程式設計師)為了編譯通過,在 clobbers 的位置便沒有放上 edi , esi ,大部分情況下都沒有問題,但是如果編譯器在優化的過程中依賴於 strcmp 不改變 edi , esi ,就可能出現Bug。
試驗
現在我們從理論上發現了Bug的成因,下面我們做個試驗驗證一下。由於該Bug是因為tmpSemP->m_name 和 tmpSemP 就值而言是相同,才導致 tmpSemP 變數中間存儲和 tmpSemP->m_name 傳參使用了相同的暫存器 edi ,我們可以改變結構體成員的排列,避免這種特定的優化方式,應該就會在測試程式中避免bug,例如:
typedef struct sem_t { struct sem_t * m_next; char m_name[128]; } sem_t;再次運行,報錯消失:
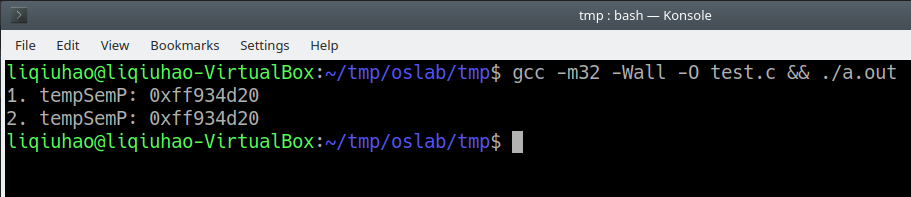
再次在IDA中觀察:

可見,這裡在調用第一個 __printf_chk 的時候 tempSemP 是放在 ecx 而非 edi 中,而第二個 __printf_chk 是使用之前放在 edx 中的 tempSemP 而非 edi ,確實避免了這種優化。
但是,一個新的問題出現了,根據x86調用約定(Calling Convention), ecx 和 edx 是 Caller-saved (volatile) registers [6] ,即調用者不能依賴被調用函數保證它們的值不變,那 GCC 為什麼就使用這兩個暫存器作為 strcmp 調用前後 tempSemP 的值呢?
其實,在 GCC 文檔中對於 inline function 提到了這麼一句 [7]:
This combination of
inlineandexternhas almost the effect of a macro. The way to use it is to put a function definition in a header file with these keywords, and put another copy of the definition (lackinginlineandextern) in a library file. The definition in the header file will cause most calls to the function to be inlined. If any uses of the function remain, they will refer to the single copy in the library.
也就是說,在使用 inline 和 extern 修飾的函數時,GCC將其幾乎(almost)和宏一樣處理,可能也就不在更具調用約定優化了。
解決
解決思路有兩種。
一是告知編譯器哪些暫存器不能依賴(volatile),或者直接使用非彙編的寫法,讓編譯器去安排。例如我們可以創建一個 string_fix.h ,在C上實現實現一個 strCmp :
#ifndef _STRING_FIX_H_ #define _STRING_FIX_H_ /* * This header file is for fixing bugs caused by inline assembly * in string.h. */ int strCmp(const char* s1, const char* s2) { while(*s1 && (*s1 == *s2)) { s1++; s2++; } return *(const unsigned char*)s1 - *(const unsigned char*)s2; } #endif 二是手動在原來的內聯彙編中保存被修改的暫存器,例如:
extern inline int strcmp(const char * cs,const char * ct) { register int __res ; __asm__("push %%edintpush %%esint" "cldnt" "1:tlodsbnt" "scasbnt" "jne 2fnt" "testb %%al,%%alnt" "jne 1bnt" "xorl %%eax,%%eaxnt" "jmp 3fn" "2:tmovl $1,%%eaxnt" "jl 3fnt" "negl %%eaxnt" "3:nt" "pop %%esintpop %%edin" :"=a" (__res):"D" (cs),"S" (ct)); return __res; }測試及後續不再展示。
後記
這真的是Linus Torvalds [8] 寫的程式碼嗎?我試著在網上找到了一份看似權威的程式碼 [9],結果其中的 strcmp 如下:
extern inline int strcmp(const char * cs,const char * ct) { register int __res __asm__("ax"); __asm__("cldn" "1:tlodsbnt" "scasbnt" "jne 2fnt" "testb %%al,%%alnt" "jne 1bnt" "xorl %%eax,%%eaxnt" "jmp 3fn" "2:tmovl $1,%%eaxnt" "jl 3fnt" "negl %%eaxn" "3:" :"=a" (__res):"D" (cs),"S" (ct):"si","di"); return __res; }Linus Torvalds明確了 Clobbers 為 si 和 di ,或許那個時候的GCC沒有 Clobbers 不能和 InOutputOperands 重疊這個限制吧。
比較大的可能性是現在的人在研究的過程中為了方便編譯,將 Clobbers 直接做了刪除,例如下面幾篇文章都提到了這種方法:
同時,在這篇文章中指出 [10] ,Linux 0.1x 中這種因 Clobbers 無法通過現代編譯器文件還有:
- include/linux/sched.h: set_base,set_limit
- include/string.h :strcpy, strncpy,strcat,strncat,strcmp,strncmp,strchr, strrchr,strspn,strcspn,strpbrk,strstr,memcpy,memmove,memcmp,memchr,
- mm/memory.c:copy_page,get_free_page
- fs/buffer.c:COPY_BLK
- fs/namei.c:match
- fs/bitmap.c:clear_block,find_first_zero
- kernel/blk_drv/floppy.c:copy_buffer
- kernel/blk_drv/hd.c:port_read,port_write
- kernel/chr_drv/console.c:scrup,scrdown,csi_J,csi_K,con_write
參考
[1] HIT-OSLAB-MANUAL
[3] SCASB
[4] 6.47 How to Use Inline Assembly Language in C Code
[5] lodsb
[7] 5.34 An Inline Function is As Fast As a Macro
[8] Linus Torvalds
[10] 64位Debian Sid下編譯Linux 0.11內核

