一个关于内联优化和调用约定的Bug
- 2019 年 10 月 23 日
- 笔记
很久没有更新博客了(博客园怎么还不更新后台),前几天在写一个Linux 0.11的实验 [1] 时遇到了一个奇葩的Bug,就在这简单记录一下调试过程吧。
现象
这个实验要求在Linux 0.11中实现简单的信号量 [2],但在改动内核代码后运行测试程序总是报错,例如:
/* pc_test.c */ #define __LIBRARY__ #include <stdio.h> #include <stdlib.h> #include <semaphore.h> #include <unistd.h> _syscall2(long, sem_open, const char *, name, unsigned int, value); _syscall1(int, sem_unlink, const char *, name); int main(void) { sem_t *mutex; if ((mutex = (sem_t *) sem_open("mutex", 1)) == (sem_t *)-1) { perror("opening mutex semaphore creating"); return EXIT_FAILURE; } sem_unlink("mutex"); return EXIT_SUCCESS; } 提示为段错误:

定位
在内核实现信号量的核心代码 sem.c 中插桩调试,最终把发生段错误的位置定在寻找已存在信号量的 find_sem 函数中:
/* 以下注释部分是semaphore.h中我定义的链表结构体 #define MAXSEMNAME 128 struct sem_t { char m_name[MAXSEMNAME+1]; unsigned long m_value; struct sem_t * m_prev; struct sem_t * m_next; struct task_struct * m_wait; }; typedef struct sem_t sem_t; #define SEM_FAILED ((sem_t *)-1) */ // Data structure optimization is possible here sem_t _semHead={.m_name = "_semHead", .m_value = 0, .m_prev = NULL, .m_next = NULL, .m_wait = NULL}; sem_t *find_sem(const char* name) { sem_t *tmpSemP = &_semHead; while (tmpSemP->m_next != NULL) { if (strcmp((tmpSemP->m_name), name) == 0) { return tmpSemP; } tmpSemP = tmpSemP->m_next; } return tmpSemP; }由于该函数中存在 P->member 这样的解引用操作,很大概率就是P的值出了问题,所以就在P对应的操作附近加上 printk ,判断是否进一步定位Bug:
sem_t *find_sem(const char* name) { printk("Now we are in find_semn"); // DEBUG sem_t *tmpSemP = &_semHead; while (tmpSemP->m_next != NULL) { printk("find_sem: tmpSemp before strcmp: %pn", tmpSemP); if (strcmp((tmpSemP->m_name), name) == 0) { printk("find_sem: tmpSemp after strcmp: %pn", tmpSemP); // DEBUG printk("find_sem: return...nn"); // DEBUG return tmpSemP; } printk("find_sem: tmpSemp after strcmp: %pnn", tmpSemP); // DEBUG tmpSemP = tmpSemP->m_next; } printk("find_sem: return...nn"); // DEBUG return tmpSemP; }重新编译内核,再次运行上面的 pc_test.c ,奇怪的事情发生了:
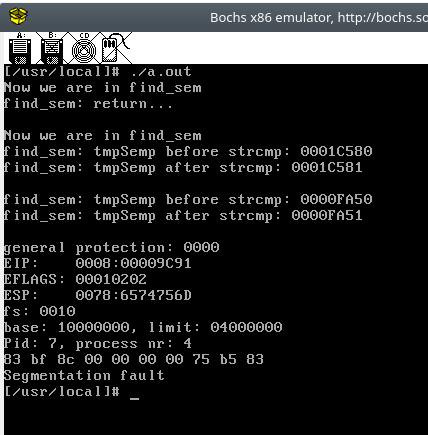
可以看到,第一次进入 find_sem 并没有发生段错误,这是因为第一次调用 sem_open 的时候内核中还没有信号量,所以 tmpSemP->m_next != NULL 不成立,但是第二次和第三次进入 find_sem ,temSemP 的值却在 strcmp(tmpSemP->m_name, name) 前后发生了改变。我们知道,C中的函数参数是“按值传递”的,如果编译器真的把strcmp 按照C函数的规则编译,那么传递 m_name 的值, tmpSemP 的值是不可能改变的。所以现在的结论是, string.h 中定义的 strcmp 很可能出了问题。
复现
为了更好的分析和调试,我将 string.h , semaphore.h 和 sem.c 中的 find_sem 关键代码拿出来,精简后在用户态进行Bug复现:
/* test.c */ #include <stdio.h> // string.h inline int strcmp(const char * cs,const char * ct) { register int __res ; __asm__("cldn" "1:tlodsbnt" "scasbnt" "jne 2fnt" "testb %%al,%%alnt" "jne 1bnt" "xorl %%eax,%%eaxnt" "jmp 3fn" "2:tmovl $1,%%eaxnt" "jl 3fnt" "negl %%eaxn" "3:" :"=a" (__res):"D" (cs),"S" (ct)); return __res; } //semaphore.h typedef struct sem_t { char m_name[128]; struct sem_t *m_next; } sem_t; //sem.c int main(void) { sem_t _semRear={.m_name = "_semRear", .m_next = (sem_t *)0}; sem_t _semHead={.m_name = "_semHead", .m_next = &_semRear}; sem_t *tmpSemP = &_semHead; char name[] = "test"; while (tmpSemP->m_next != (sem_t *)0) { printf("1. tempSemP: %pn", tmpSemP); if(!strcmp((tmpSemP->m_name), name)) return 0; printf("2. tempSemP: %pn", tmpSemP); tmpSemP = tmpSemP->m_next; } return 0; }Bug复现:
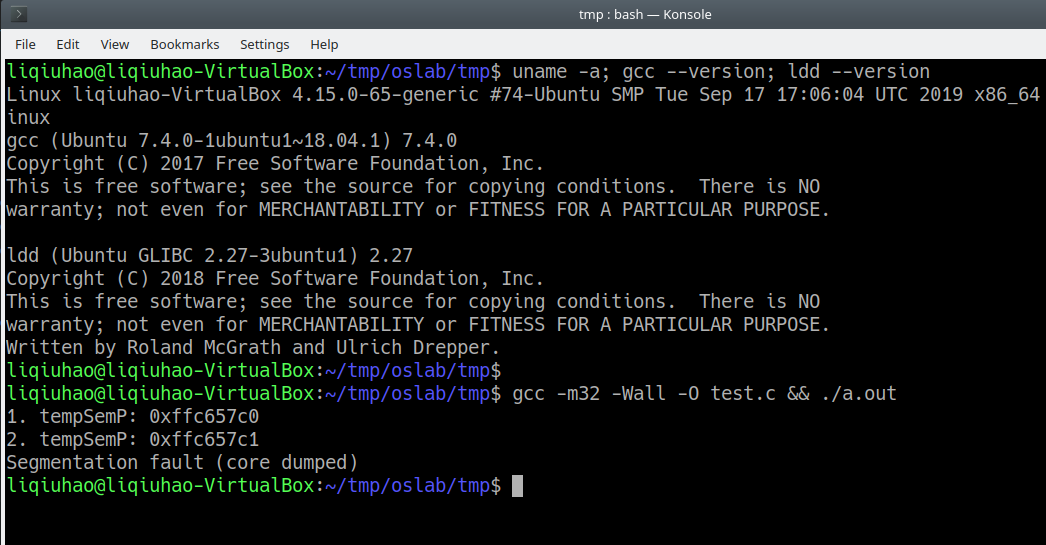
分析
我们首先分析一下 strcmp 的实现:
extern inline int strcmp(const char * cs,const char * ct) { register int __res ; // 寄存器变量 __asm__("cldn" // 清理方向位 "1:tlodsbnt" // 将ds:[esi]存入al,esi++ "scasbnt" // 比较al与es:[edi],edi++ "jne 2fnt" // 若不等,向下跳转到2标志 "testb %%al,%%alnt" // 测试al寄存器 "jne 1bnt" // 若al不为0,则向上跳转到1标志 "xorl %%eax,%%eaxnt" // 若al为零,则清空eax(返回值) "jmp 3fn" // 向下跳转到3标志返回 "2:tmovl $1,%%eaxnt" // eax置为1 "jl 3fnt" // 若上面的比较al更小,则这里返回正值(1) "negl %%eaxnt" // 否则eax = -1 返回负值 "3:" :"=a" (__res):"D" (cs),"S" (ct)); // 规定edi寄存器接收cs参数的值,esi接收ct参数的值,最终将eax的值输出到__res寄存器变量中 return __res; // 返回__res }如上,为了性能优化, strcmp 使用了内联优化(函数和汇编),是代码还是编译器的锅呢?拖入IDA,静态分析一下:

编译器忠实的保留了内联汇编的语句。通过 __printf_chk 的参数,我们知道进入控制流进入 strcmp 之前和之后编译器都把 tempSemP 放在寄存器 edi 中,并且由于信号量结构体的第一个成员就是 m_name :
//semaphore.h typedef struct sem_t { char m_name[128]; struct sem_t *m_next; } sem_t;而 m_name 又是一个数组名,所以 tmpSemP->m_name 和 tmpSemP 就值而言是相同的。由于内联汇编规定使用 edi 作为第一个参数的输入寄存器,所以编译器为了优化,首先就将 tempSemP 放在寄存器 edi ,这样后面进入 strcmp 的时候就不需要再次改变 edi 了 。
但是,内联汇编的代码中明明有 scasb [3] ,其会在比较操作后更改 edi 的值,难道编译器不知道吗?通过查阅GCC文档关于内联汇编的说明 [4]:
asm asm-qualifiers ( AssemblerTemplate : OutputOperands [ : InputOperands [ : Clobbers ] ])6.47.2.6 Clobbers and Scratch Registers
While the compiler is aware of changes to entries listed in the output operands, the inline
asmcode may modify more than just the outputs. For example, calculations may require additional registers, or the processor may overwrite a register as a side effect of a particular assembler instruction. In order to inform the compiler of these changes, list them in the clobber list. Clobber list items are either register names or the special clobbers (listed below). Each clobber list item is a string constant enclosed in double quotes and separated by commas.Clobber descriptions may not in any way overlap with an input or output operand….
文档说明了对于汇编语句中被修改但是不在 InputOperands中的寄存器,应该在 Clobbers 中写出,不然编译器不知道哪些寄存器(Bug这里是 edi )被修改,也就可能在优化的过程中出错了。
回到 strcmp 的代码,最后一行是:"=a" (__res):"D" (cs),"S" (ct)); ,而scasb 与 lodsb [5] 修改的又是 edi , esi 。根据上面文档的说明, clobbers 不能与输入输出位置的操作数重复,所以如果这里在 clobbers 的位置放上 edi , esi 就会报错:

(这个程序员)为了编译通过,在 clobbers 的位置便没有放上 edi , esi ,大部分情况下都没有问题,但是如果编译器在优化的过程中依赖于 strcmp 不改变 edi , esi ,就可能出现Bug。
试验
现在我们从理论上发现了Bug的成因,下面我们做个试验验证一下。由于该Bug是因为tmpSemP->m_name 和 tmpSemP 就值而言是相同,才导致 tmpSemP 变量中间存储和 tmpSemP->m_name 传参使用了相同的寄存器 edi ,我们可以改变结构体成员的排列,避免这种特定的优化方式,应该就会在测试程序中避免bug,例如:
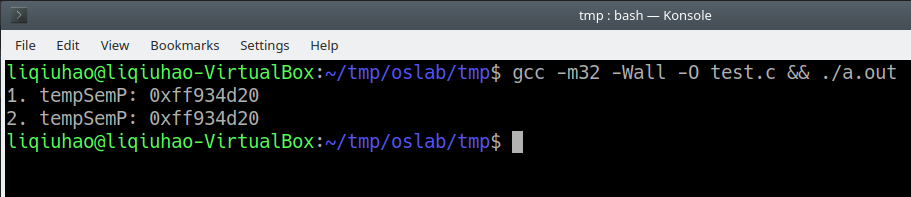
typedef struct sem_t { struct sem_t * m_next; char m_name[128]; } sem_t;再次运行,报错消失:
再次在IDA中观察:

可见,这里在调用第一个 __printf_chk 的时候 tempSemP 是放在 ecx 而非 edi 中,而第二个 __printf_chk 是使用之前放在 edx 中的 tempSemP 而非 edi ,确实避免了这种优化。
但是,一个新的问题出现了,根据x86调用约定(Calling Convention), ecx 和 edx 是 Caller-saved (volatile) registers [6] ,即调用者不能依赖被调用函数保证它们的值不变,那 GCC 为什么就使用这两个寄存器作为 strcmp 调用前后 tempSemP 的值呢?
其实,在 GCC 文档中对于 inline function 提到了这么一句 [7]:
This combination of
inlineandexternhas almost the effect of a macro. The way to use it is to put a function definition in a header file with these keywords, and put another copy of the definition (lackinginlineandextern) in a library file. The definition in the header file will cause most calls to the function to be inlined. If any uses of the function remain, they will refer to the single copy in the library.
也就是说,在使用 inline 和 extern 修饰的函数时,GCC将其几乎(almost)和宏一样处理,可能也就不在更具调用约定优化了。
解决
解决思路有两种。
一是告知编译器哪些寄存器不能依赖(volatile),或者直接使用非汇编的写法,让编译器去安排。例如我们可以创建一个 string_fix.h ,在C上实现实现一个 strCmp :
#ifndef _STRING_FIX_H_ #define _STRING_FIX_H_ /* * This header file is for fixing bugs caused by inline assembly * in string.h. */ int strCmp(const char* s1, const char* s2) { while(*s1 && (*s1 == *s2)) { s1++; s2++; } return *(const unsigned char*)s1 - *(const unsigned char*)s2; } #endif 二是手动在原来的内联汇编中保存被修改的寄存器,例如:
extern inline int strcmp(const char * cs,const char * ct) { register int __res ; __asm__("push %%edintpush %%esint" "cldnt" "1:tlodsbnt" "scasbnt" "jne 2fnt" "testb %%al,%%alnt" "jne 1bnt" "xorl %%eax,%%eaxnt" "jmp 3fn" "2:tmovl $1,%%eaxnt" "jl 3fnt" "negl %%eaxnt" "3:nt" "pop %%esintpop %%edin" :"=a" (__res):"D" (cs),"S" (ct)); return __res; }测试及后续不再展示。
后记
这真的是Linus Torvalds [8] 写的代码吗?我试着在网上找到了一份看似权威的代码 [9],结果其中的 strcmp 如下:
extern inline int strcmp(const char * cs,const char * ct) { register int __res __asm__("ax"); __asm__("cldn" "1:tlodsbnt" "scasbnt" "jne 2fnt" "testb %%al,%%alnt" "jne 1bnt" "xorl %%eax,%%eaxnt" "jmp 3fn" "2:tmovl $1,%%eaxnt" "jl 3fnt" "negl %%eaxn" "3:" :"=a" (__res):"D" (cs),"S" (ct):"si","di"); return __res; }Linus Torvalds明确了 Clobbers 为 si 和 di ,或许那个时候的GCC没有 Clobbers 不能和 InOutputOperands 重叠这个限制吧。
比较大的可能性是现在的人在研究的过程中为了方便编译,将 Clobbers 直接做了删除,例如下面几篇文章都提到了这种方法:
同时,在这篇文章中指出 [10] ,Linux 0.1x 中这种因 Clobbers 无法通过现代编译器文件还有:
- include/linux/sched.h: set_base,set_limit
- include/string.h :strcpy, strncpy,strcat,strncat,strcmp,strncmp,strchr, strrchr,strspn,strcspn,strpbrk,strstr,memcpy,memmove,memcmp,memchr,
- mm/memory.c:copy_page,get_free_page
- fs/buffer.c:COPY_BLK
- fs/namei.c:match
- fs/bitmap.c:clear_block,find_first_zero
- kernel/blk_drv/floppy.c:copy_buffer
- kernel/blk_drv/hd.c:port_read,port_write
- kernel/chr_drv/console.c:scrup,scrdown,csi_J,csi_K,con_write
参考
[1] HIT-OSLAB-MANUAL
[3] SCASB
[4] 6.47 How to Use Inline Assembly Language in C Code
[5] lodsb
[7] 5.34 An Inline Function is As Fast As a Macro
[8] Linus Torvalds
[10] 64位Debian Sid下编译Linux 0.11内核

