Pytorch_第七篇_深度學習 (DeepLearning) 基礎 [3]—梯度下降
深度學習 (DeepLearning) 基礎 [3]—梯度下降法
Introduce
在上一篇「深度學習 (DeepLearning) 基礎 [2]—神經網路常用的損失函數」中我們介紹了神經網路常用的損失函數。本文將繼續學習深度學習的基礎知識,主要涉及基於梯度下降的一類優化演算法。首先介紹梯度下降法的主要思想,其次介紹批量梯度下降、隨機梯度下降以及小批量梯度下降(mini-batch)的主要區別。
以下均為個人學習筆記,若有錯誤望指出。
梯度下降法
主要思想:沿著梯度反方向更新相關參數,使得代價函數逐步逼近最小值。
思路歷程:
假設給我們一個損失函數,我們怎麼利用梯度下降法找到函數的最小值呢(換一種說法,即如何找到使得函數最小的參數x)?首先,我們應該先清楚函數的最小值一般位於哪裡。按我的理解應該是在導數為0的極值點,然而極值點又不一定都是最小值點,可能是局部極小值點。那麼,既然知道了最小值點在某個極值點(梯度為0),那麼我們使得損失函數怎麼逼近這個極值點呢?
現在我們反過來思考上述梯度下降法的主要思想。首先,要理解這個主要思想,我們需要理解梯度方向是什麼。梯度方向指的是曲面當前點方嚮導數最大值的方向(指向函數值增大的方向)。假設我們現在處在函數上x=xt這個點(梯度不為0,不是極值點),因此現在我們需要確定增加x還是減少x能幫忙我們逼近函數的最小值。前面說過梯度方向指向函數值增大的方向,因此我們只要往梯度的反方向更新x,就能找到極小值點。(可能還是有點迷,下面結合例子具體看梯度下降的執行過程來理解其主要思想)
(note: 由於凸函沒有局部極小值,因此梯度下降法可以有效找到全局最小值,對於非凸函數,梯度下降法可能陷入局部極小值。)
舉個梨子:
假設有一個損失函數如下(當x=0的時候取得最小值,我們稱x=0為最優解):
\]
我們需要利用梯度下降法更新參數x的值使得損失函數y達到最小值。首先我們隨機初始化參數x,假設我們初始化參數x的值為xt,如下圖所示:
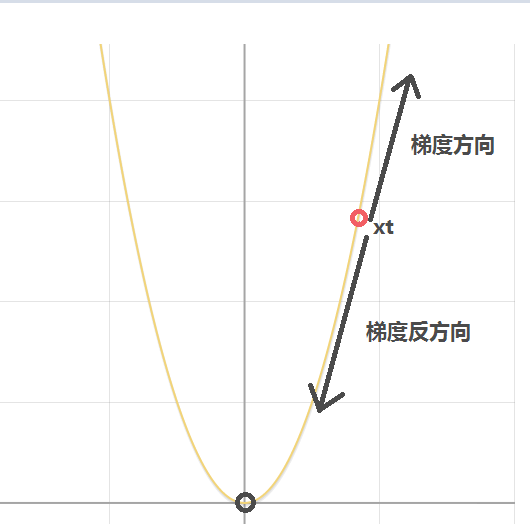
現在問題轉化為我們怎麼更新參數x的值(當前為xt)使得其越來越靠近使得函數達到最小值的最優參數x。直觀上看我們需要減小x的值,才能使得其越來越靠近最優參數。
現在我們求取y對參數x的導(當有多個參數時,為偏導),如下:
\]
由於xt>0,因此當我們代入xt到y’,我們可以發現在點xt處導數(梯度)為正值,所指方向為圖中所示的梯度方向。很明顯,我們不能隨著梯度指示的方向更新參數x,而應該往梯度方向的負方向更新。如上圖所示,很明顯,應該減小x的值才能慢慢靠近最優解。因此,不難給出參數x的更新公式(即梯度下降的參數一般更新公式)如下(α為學習率):
\]
我們來驗證上述更新公式。
- 當x=xt(xt>0)(位於y軸右邊),則在x處的導數也大於0,由更新公式,下一時刻的x會減少(如上圖所示x=xt減少會越來越靠近最優解x=0)。
- 當x=-xt(xt>0)(位於y軸左邊),則在x處的導數也小於0,代入更新公式,我們發現下一時刻x會增加(如上圖所示x=-xt增加會越來越靠近最優解x=0)。因此推導出的梯度下降參數更新公式符合我們的目標。
- 因此不斷對參數x對上述更新,最終x的值會慢慢靠近最優解x=0.
上述便是梯度下降法的原理了,只不過舉的例子比較簡單,多參數(如神經網路中的參數w和b)的可以類似推理。
一個注意點:假設我們現在處在x=xt這個點,若學習率α設置過大,雖然收斂速度可能會加快(每次跨步大),但是xt也可能會過度更新,即(一次性減得太多)可能會越過最優解(跑到最優解的左邊),再一次更新的話也可能會再次越過最優解(一次性加得太多,跑到最優解的右邊),emmm,就這樣反覆橫跳,始終達不到最優解。另外,學習率設置太小的話,x雖然更可能達到最優解,但是演算法收斂太慢(x的每一個跨步太短)。對於學習率的選擇,可以按0.001、0.01、0.1、1.0這樣子來篩選。
現在依次介紹三種類型的梯度下降法,批量梯度下降、隨機梯度下降以及小批量梯度下降。 以下介紹均以Logistic回歸模型的損失函數(凸函數)為例,如下:
\]
\]
\]
其中input = (x1,x2)為輸入的訓練樣本。我們的目標是在訓練樣本集(假設有N個訓練樣本)上尋找最優參數w1、w2以及b使得損失函數在訓練樣本上達到最小的損失。(神經網路的訓練過程過程就是輸入訓練樣本,計算損失,損失函數反向對待更新參數求梯度,其次按照梯度下降法的參數更新公式朝著梯度反方向更新所有參數,如此往複,直到找到使得損失最小的最優參數或者達到最大迭代次數)(注意到損失函數上還有一個常量n我們沒有解釋,其實我覺得以下三個基於梯度下降的優化演算法主要區別就是在n的取值上)
批量梯度下降(n=N的情況)
對於上述問題,批量梯度下降的做法是什麼樣的呢?其每次將整個訓練樣本集都輸入神經網路模型,然後對每個訓練樣本都求得一個損失,對N個損失加權求和取平均,然後對待更新參數求導數,其次按照梯度下降法的參數更新公式朝著梯度反方向更新所有參數。通俗來講就是每次更新參數都用到了所有訓練樣本(等價於上述損失公式中的n=N)。每一輪參數更新中,每個訓練樣本對參數更新都有貢獻(每一個樣本都給了參數更新一定的指導資訊),因此理論上每一輪參數更新提供的資訊是很豐富的,參數更新的幅度也是比較大的,使得參數更新能在少數幾輪迭代中就達到收斂(對於凸優化問題能達到全局最優)。然而,對於大數據時代,訓練樣本可能有很多很多,每輪都是用那麼多的樣本進行參數更新的指導的話,更新一次(一次epoch)會非常非常久,這是這種方法的主要缺點。
隨機梯度下降(n=1的情況)
對於上述優化問題,隨機梯度下降(SGD)與批量梯度下降法的主要區別就是, SGD每一輪參數更新都只用一個訓練樣本來指導參數更新(n=1)。也就是說每次只計算出了某訓練樣本的損失,並進行反向傳播指導參數更新。其優點是每一輪迭代的時間開銷非常低(因為只用到了一個訓練樣本)。然而一個訓練樣本提供的資訊可能比較局限,即其可能使得某次參數更新方向並不是朝著全局最優的方向(如雜訊樣本提供的資訊可能就是錯誤的,導致其往偏離全局最優的方向更新),但是整體上是朝著全局最優的方向的。雖然隨機梯度下降可能最終只能達到全局最優附近的某個值,但是相對於批量梯度下降來說最好的地方就是速度很快,因此基於精度和效率權衡,更常用的還是SGD。
小批量(mini-batch)梯度下降(n=num_batch)
小批量梯度下降是上述兩種方法的一個折中,即既考慮精度也考慮了收斂速度。那麼折中方法是怎麼做的呢?首先小批量梯度需要設置一個批量的大小(假設是num_batch),然後每次選取一個批量的訓練樣本,計算得到num_batch個損失,求和取平均後反向傳播來指導參數更新(n=num_batch)。通俗來說就是每一輪的參數更新我們既不是用上整個訓練樣本集(時間開銷大),也不是只用一個訓練樣本(可能提供錯誤資訊),我們是使用一個小批量的樣本(1<n<N)來指導參數更新。雖然可能效果沒有批量梯度下降法好,速度沒有隨機梯度下降法快,但是這種方法在精度和收斂速度上是一個很好的折中。因此,在深度學習中,用得比較多的一般還是小批量(mini-batch)梯度下降。


