Kafka 入門(二)–數據日誌、副本機制和消費策略
一、Kafka 數據日誌
1.主題 Topic
Topic 是邏輯概念。
主題類似於分類,也可以理解為一個消息的集合。每一條發送到 Kafka 的消息都會帶上一個主題資訊,表明屬於哪個主題。
Kafka 的主題是支援多用戶訂閱的,即一個主題可以有零個、一個或者多個消費者來訂閱該主題的消息。
2.分區 Partition
1)分區原因
- 方便集群擴展,因為一個 Topic 由多個 Partition 組成,而 Partition 又可以通過調整以適應不同的機器,因而整個集群就可以適應任意大小的數據;
- 方便提高並發,因為可以以 Partition 為單位進行讀寫。
2)分區概念
Partition 是物理概念,一個 Partition 就對應於一個文件夾。
在 Kafka 中每個主題都可以劃分成多個分區,每個主題至少有一個分區,同一個主題的分區之間所包含的消息是不一樣的。每個分區只會存在於一個 Broker 上。
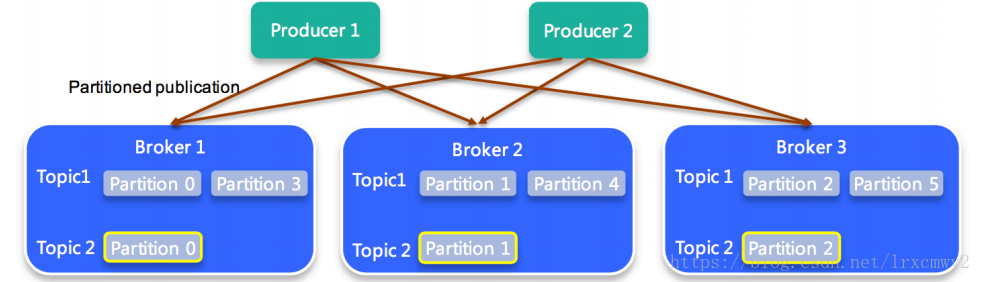
每個消息在被添加到分區中的時候,都會帶一個 offset(偏移量),它是消息在分區中的編號。通過設置 offset,Kafka 可以保證分區內的消息是有序的,但跨分區的消息是無序的。
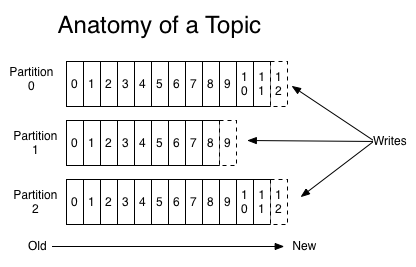
3)分區策略
- 在指明 Partition 的情況下,直接將指明的值作為 Partition 的值;
- 在未指明 Partition 但有 key 的情況下,將 key 的哈希值和該 Topic 中 Partition 的數量進行求余操作,其結果作為 Partition 的值;
- 在未指明 Partition 的值也沒有 key 的情況下,第一次調用時生成一個隨機整數,之後在這個整數上自增,將其值和該 Topic 中 Partition 的數量進行求余操作,其結果作為 Partition 的值,即 round-robin 演算法。round-robin:輪詢調度演算法,原理是每一次把來自用戶的請求輪流分配給內部中的伺服器,從1開始,直到 N(內部伺服器個數),然後重新開始循環。
3.數據日誌
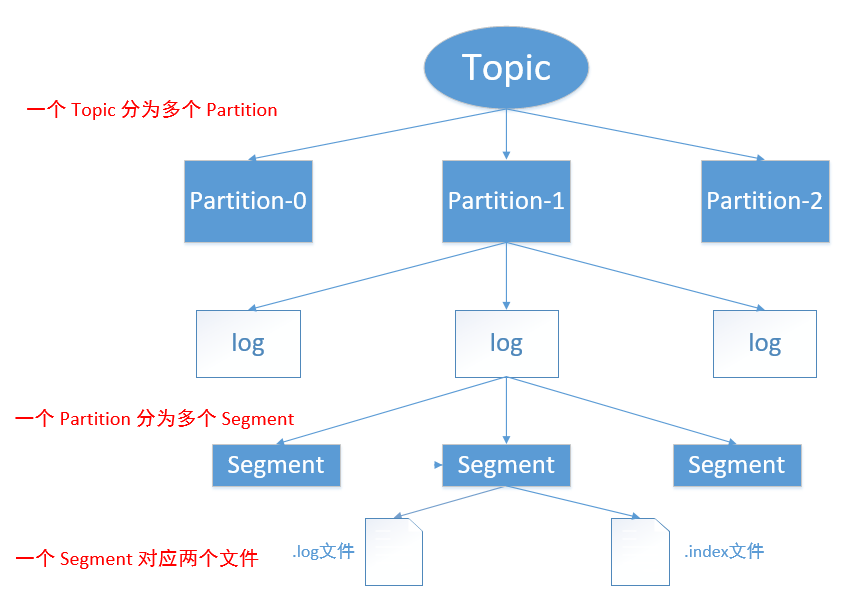
對於每一個主題,Kafka 保持一個分區日誌文件 log,而生產者生產的消息會不斷添加到 log 文件末尾,為了防止 log 文件過大導致效率降低,Kafka 採用了分片和索引的機制,每個 Partition 分為多個 Segment,每個 Segment 又由兩個文件組成 「.index」索引文件和「.log」數據文件。這些文件位於一個文件夾下,文件夾的命名規則為:Topic 名稱+ Partition 序號,而 index 和 log 文件的命名是根據當前 Segment 的第一條消息的 offset 偏移量來命名的。
在 index 文件中,是使用 key-value 結構來存儲的,key 是 Message 在 log 文件中的編號,value 就是消息值。但是 Index 文件中並沒有給每條消息都建立索引,而是採用了稀疏存儲的方式,每隔一定位元組的數據建立一條索引。這樣避免了索引文件佔用過多的空間,從而可以將索引文件保留在記憶體中 。

二、Kafka 副本機制
1.副本 Replica
Replica 是 Partition 的副本。每個 Partition 可以有多個副本,這多個副本之中,只有一個是 leader,其他都是 follower,所有的讀寫請求都通過 leader 來完成,follower 只負責備份數據。follow 會均勻分配到多個 Broker 上,當 leader 所在的機器掛掉之後,會從 follower 中重新選出一個副本作為 leader 繼續提供服務。
那麼為什麼有這麼多的副本卻只使用 leader 來提供服務呢?如果都用上不是可以提高性能嗎?這其實就是一致性和可用性之間的取捨了,如果多個副本同時進行讀寫操作,很容易出現問題。例如在讀取消息時,一個消費者沒有讀取到,而另一個消費者卻讀取到了,因為這個消費者讀取的是 leader 副本,顯然這樣是不行的。所以為了保證一致性,只使用一個 leader 副本來提供服務。
2.Commit 策略
Commit:指 leader 通知 Producer ,數據已經成功收到。Kafka 盡量保證 Commit 後即使 leader 掛掉,其他 flower 都有該條數據。
我們已經知道一個 Partition 可以有多個副本,當有數據寫入 leader 時,這些 follower 是怎麼複製數據的?下面是兩種策略:
- 同步複製:只有所有的 follower 把數據都複製之後才 Commit,這種策略的一致性好,但可用性不高,當 follower 數量較多時,複製過程就會很耗時。
- 非同步複製:只要 leader 拿到數據就立即 Commit,然後 follower 再複製,這種策略的可用性高,但一致性較差,例如在 Commit 之後 leader 掛掉,其他 follow 中就都沒有該數據了。
那麼 Kafka 使用的是什麼策略呢?Kafka 使用了一種 ISR (in-sync Replica)機制:
- leader 會維護一個與其基本保持同步的 Replica 列表,稱為 ISR(in-sync Replica);
- 每個 Partition 都會有一個 ISR ,而且是由 leader 動態維護;
- 如果 ISR 中有一個 flower 比一個 leader 落後太多,或者超過一定時間沒有請求複製數據,則將其移除;
- 當 ISR 中所有 Replica 都向 leader 發送 ACK 時,leader 才會 Commit。
3.ACK 機制
ACK:為了保證 Producer 發送的消息能夠到達指定的 Topic,每個 Partition 收到消息之後要向 Producer 發送 ACK(acknowledgement)確認收到,如果 Producer 收到了 ACK,就會進行下一輪的發送,否則重新發送消息。
對於某些不太重要的數據,對數據的完整性沒有嚴格的要求,可以容忍少量數據的丟失,Kafka 就沒有必要等 ISR 中的所有 follower 都複製完,所以 Kafka 提供了三種可靠性級別,供用戶進行選擇和配置:
- 0:Producer 不用等待接收 ACK,只要數據接收到就返回,此時提供了最低的延遲,但若出現故障,會丟失數據;
- 1:Producer 等待 ACK,leader 接收成功後發送 ACK,丟失數據會重發,但若 follower 同步前 leader 掛掉了,會丟失數據;
- -1:Producer 等待 ACK,leader 接收到數據,follower 同步完數據後發送 ACK,但若 follower 同步完,而 ACK 還沒發送 leader 就掛掉了,會出現數據重複。
三、Kafka 消費策略
1.消費者組 Consumer Group
Consumer Group,消費者組,一個消費者組包含多個消費者,這些消費者共用一個 ID,即 Group ID,組內的消費者協調消費所訂閱的主題的所有分區,當然了,每個分區只能由一個消費者進行消費。
2.偏移量 offset
offset ,偏移量,記錄的是消費位置資訊,即在消費者消費數據的過程中,已經消費了多少數據。
要獲取 offset 的資訊,需要知道消費者組的 ID 、主題和分區 ID。在老版本的 Kafka 中(0.9以前),offset 資訊是保存在 ZooKeeper 中的,目錄結構如下:
/consumers/<groupId>/offsets/<topic>/<partitionId>
但在新版本中(0.9及其之後的版本),Kafka 增加了一個主題:__consumers_offsets,將 offset 資訊寫入這個 Topic。不過這個 Topic 默認是不使用的,若要使用需要修改相應的設置,需要在 consumer.properties 中設置:
exclude.internal.topics=false
查詢 __consumer_offsets Topic 中的所有內容,如果是0.11.0.0之前的版本,使用如下命令:
bin/kafka-console-consumer.sh –topic __consumer_offsets –zookeeper localhost:2181 –formatter “kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter” –consumer.config config/consumer.properties –from-beginning
如果是0.11.0.0及其之後的版本,使用如下命令:
bin/kafka-console-consumer.sh –topic __consumer_offsets –zookeeper localhost:2181 –formatter “kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter” –consumer.config config/consumer.properties –from-beginning
3.消費策略
1)RangeAssignor
Kafka 默認的消費策略。
RangeAssignor 策略的原理是按照消費者總數和分區總數進行整除運算來獲得一個跨度,然後將分區按照跨度進行平均分配,以保證分區儘可能均勻地分配給所有的消費者。對於每一個 Topic,RangeAssignor 策略會將消費組內所有訂閱這個 Topic 的消費者按照名稱的字典序排序,然後為每個消費者劃分固定的分區範圍,如果不夠平均分配,那麼字典序靠前的消費者會被多分配一個分區。
假設消費組內有2個消費者 C1 和 C2,都訂閱了主題 Topic1 和 Topic2,並且每個主題都有3個分區,那麼所訂閱的所有分區可以標識為:T10、T11、T12、T20、T21、T22。最終的分配結果為:
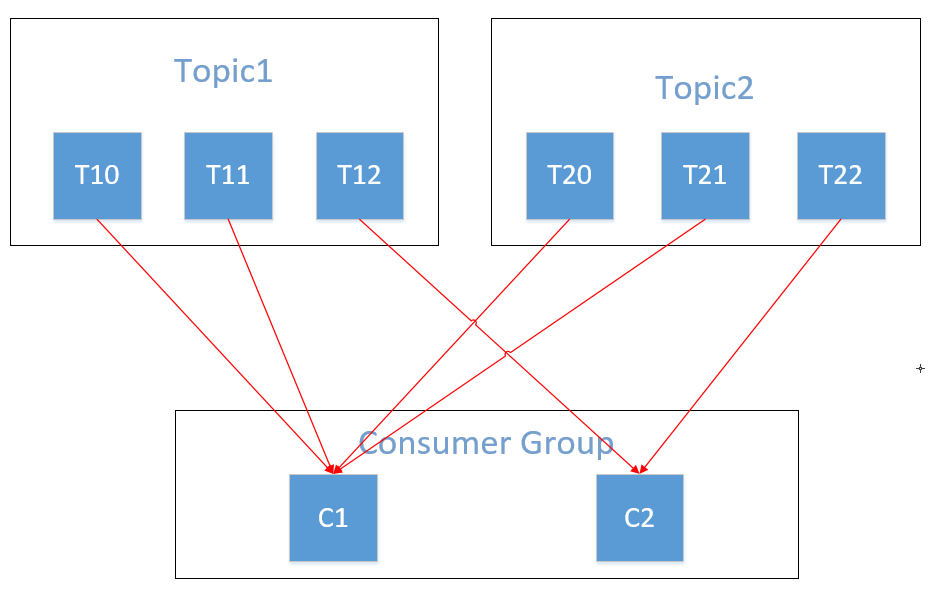
可以看到這樣分配已經不均了,如果將類似的情況擴大,可能出現超出部分消費者消費能力的情況。
2)RoundRobinAssignor
RoundRobinAssignor 策略的原理是將消費組內所有消費者以及消費者所訂閱的所有 Topic 的 Partition 按照字典序排序,然後通過輪詢方式逐個將分區以此分配給每個消費者。
假設有3個主題 Topic1、Topic2、Topic3,分別有1、2、3個分區,那麼所訂閱的所有分區可以標識為:T10、T20、T21、T30、T31、T32。消費組內有3個消費者 C1、C2、C3,其中 C1 訂閱了 Topic1,C2 訂閱了 Topic1 和 Topic2,C3 訂閱了 Topic1、Topic2 和 Topic3。最終的分配結果為:
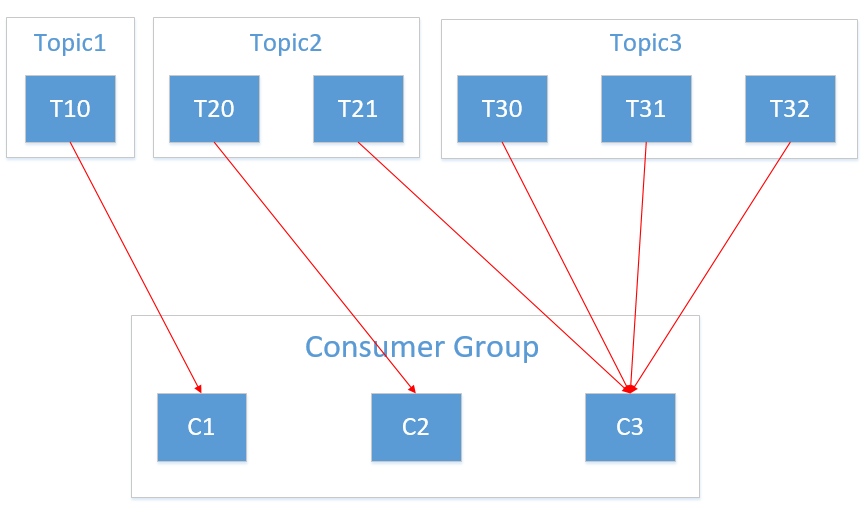
可以看到該策略也不是十分完美,這樣分配其實並不是最優解,因為完全可以將分區 T10 和 T11 分配給消費者 C1。


