全網最易懂的正則表達式教程(8 )- 貪婪模式和非貪婪模式
- 2020 年 7 月 10 日
- 筆記
- 正則表達式, 測試必知必會系列 - 正則表達式
正則詳細教程系列可以看此鏈接的文章哦
//www.cnblogs.com/poloyy/category/1796055.html
前言
- 學過正則表達式的童鞋肯定都知道貪婪模式和非貪婪模式,這是個重難點!
- 今天我們就來仔細講講它們的區別和具體實例
為什麼會有貪婪與非貪婪模式?
首先,貪婪模式和非貪婪模式跟前面講到的量詞密切相關,我們先再來看看有哪些量詞
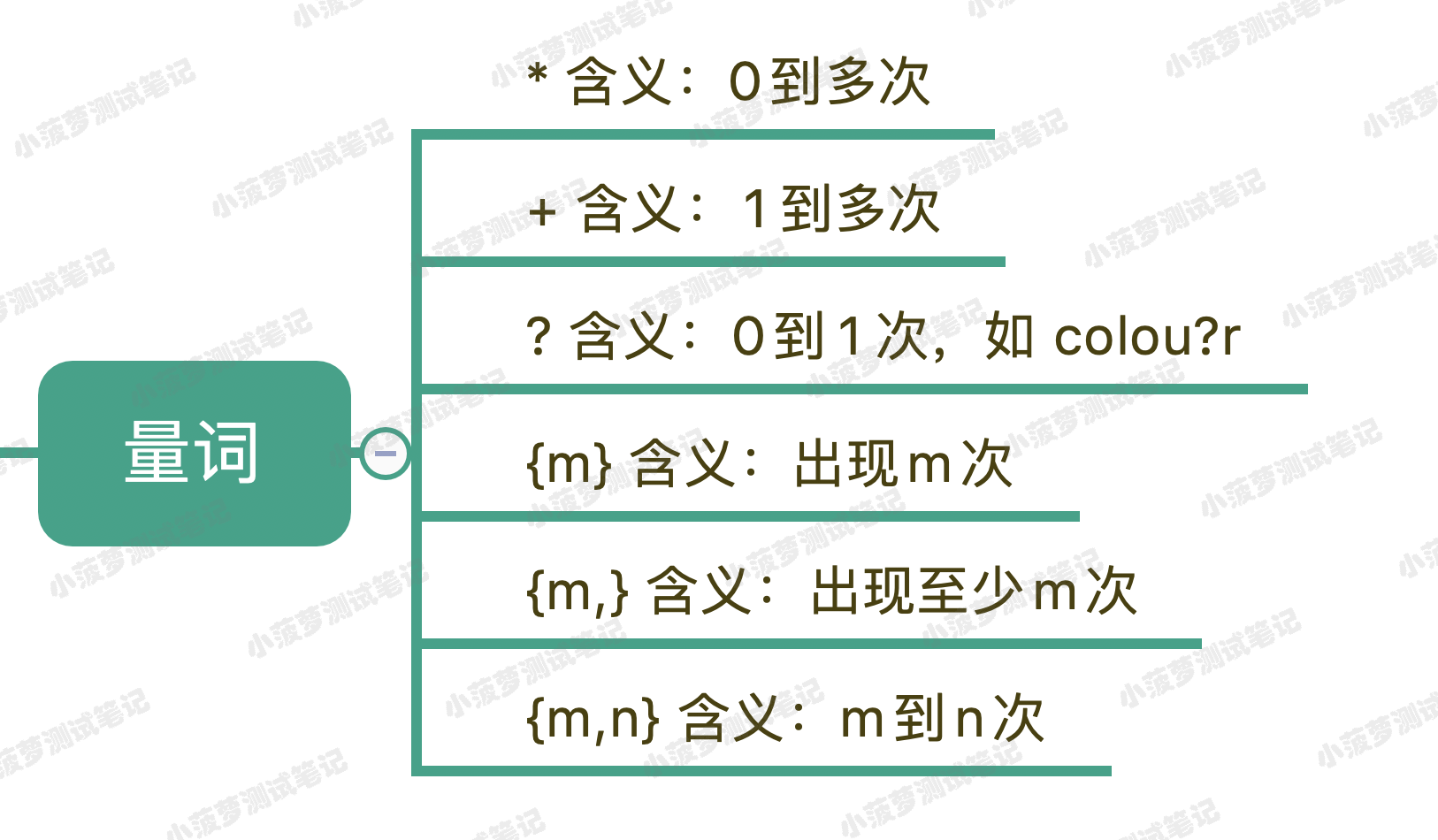
* + ? 通過 {m,n} 的等價寫法

通過 * 和 + 引入貪婪、非貪婪模式
+ 的栗子
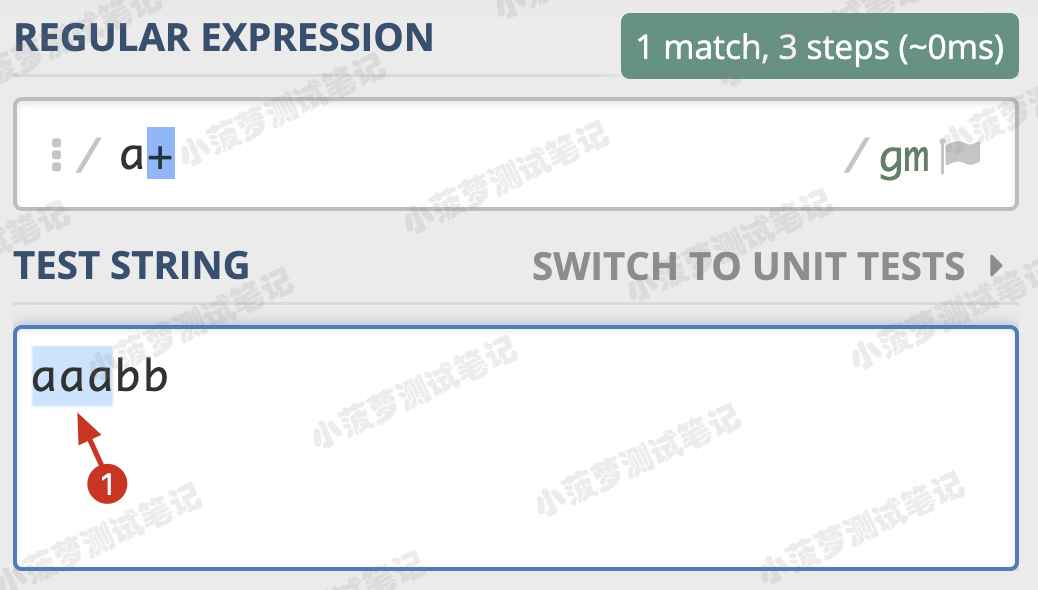
只匹配一個結果
* 的栗子
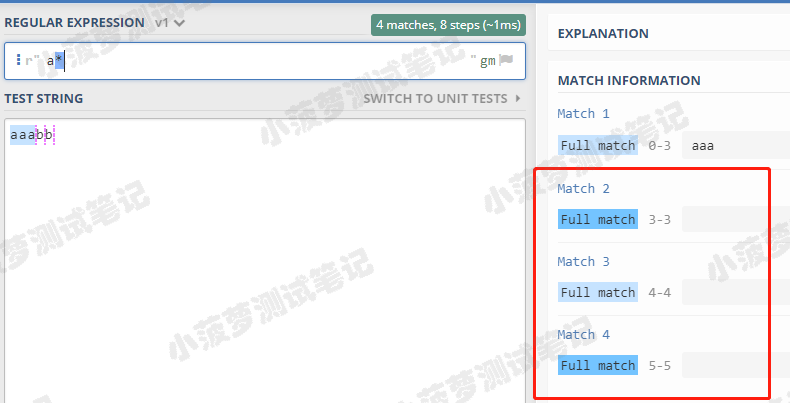
可以看到會匹配了三個空字元串,我們再通過 Python 程式碼看看輸出結果
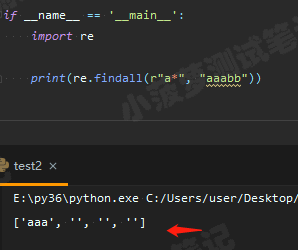
的確是會有三個空字元串
為什麼會匹配到三個空字元串
因為 * 代表 0 到多次,匹配 0 次就是空字元串
小夥伴們你是否有很多個 ?
aaa 之間的空字元串咋沒匹配上呢?
這就要說到我們的貪婪、非貪婪模式了
引入貪婪、非貪婪模式
- 這兩種模式都必須滿足匹配次數的要求才能匹配上
- 貪婪模式,簡單說就是儘可能進行最長匹配
- 非貪婪模式,則會儘可能進行最短匹配
- 正是這兩種模式產生了不同的匹配結果
貪婪模式(Greedy)
在正則中,表示次數的量詞默認是貪婪的,在貪婪模式下,會嘗試儘可能最大長度去匹配
字元串 aaabb 中使用正則 a* 的匹配過程

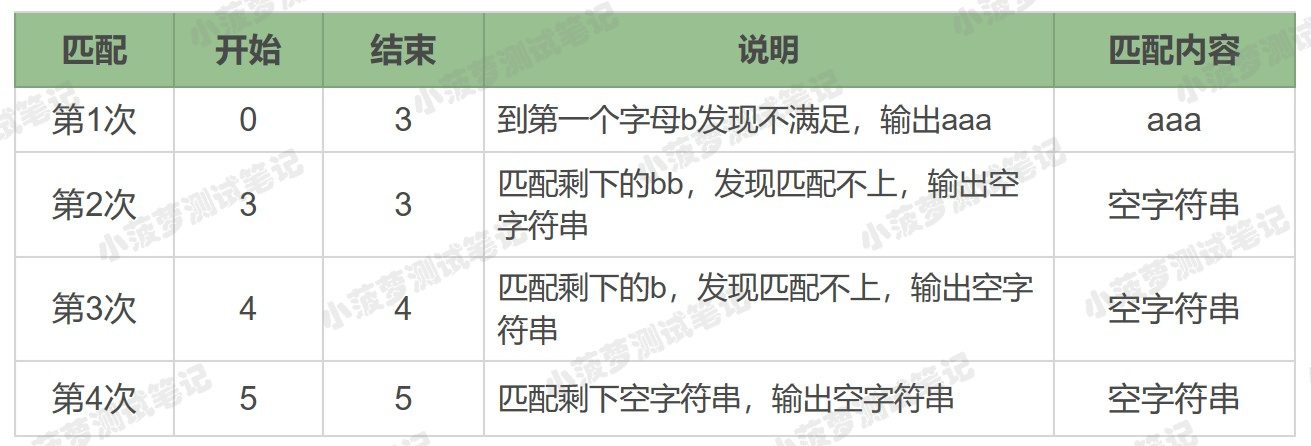
分析
a* 在匹配開頭的 a 時,會盡量匹配更多的 a,直到第一個 b 不滿足要求為止,匹配上三個 a,後面每次匹配時都得到空字元串
非貪婪匹配(Lazy)
如何從貪婪模式變成非貪婪模式呢
在量詞後面加上 ? ,正則就變成了 a*?
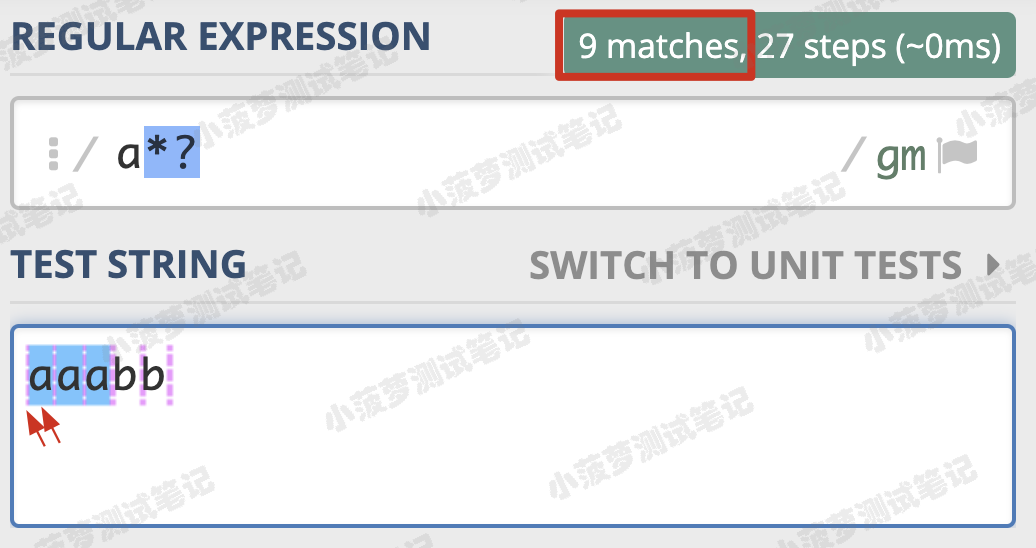
再來看一個栗子
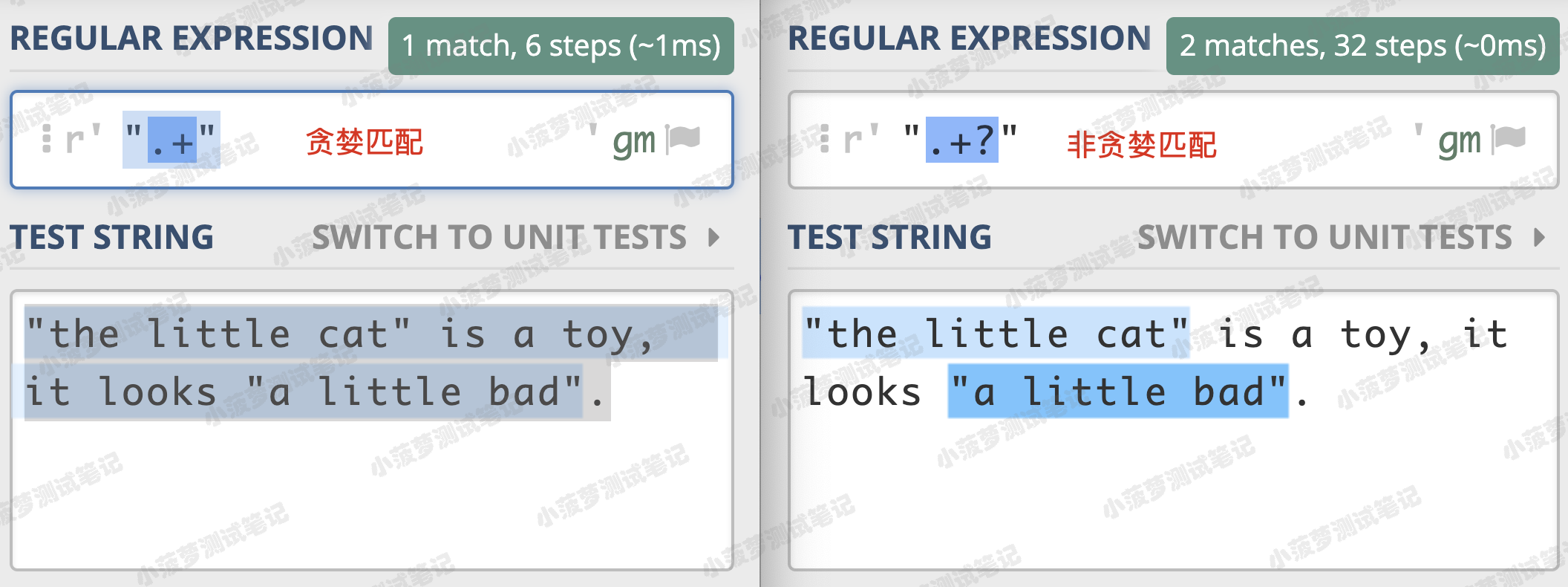
貪婪匹配:匹配上從第一個 “ 到最後一個 “ 之間的所有內容
非貪婪匹配:找到符合要求的結果
貪婪匹配和非貪婪匹配的區別

獨佔模式(Possessive)
前提
這一小節基本都搬了《正則表達式入門課》的內容
什麼是獨佔模式
- 貪婪模式和非貪婪模式,都需要發生回溯才能完成相應的功能
- 但是在一些場景下,我們不需要回溯,匹配不上返回失敗就好了
- 因此正則中還有另外一種模式,獨佔模式,它類似貪婪匹配,但匹配過程不會發生回溯,因此在一些場合下性能會更好
什麼是回溯
正則是貪婪模式
| 正則 | 文本 | 匹配結果 |
| xy{1,3}z | xyyz | xyyz |
匹配過程
- {1,3} 會儘可能長地去匹配,當匹配完 xyy 後,由於 y 要儘可能匹配最長,即三個
- 但字元串中後面是個 z 就會導致匹配不上,這時候正則就會向前回溯,吐出當前字元 z,接著用正則中的 z 去匹配

正則是非貪婪模式
| 正則 | 文本 | 匹配結果 |
| xy{1,3}?z | xyyz | xyyz |
匹配過程
- 由於 y{1,3}? 代表匹配 1 到 3 個 y,儘可能少地匹配
- 匹配上一個 y 之後,也就是在匹配上 text 中的 xy 後
- 正則會使用 z 和 text 中的 xy 後面的 y 比較,發現正則 z 和 y 不匹配
- 這時正則就會向前回溯,重新查看 y 匹配兩個的情況,匹配上正則中的 xyy
- 然後再用 z 去匹配 text 中的 z,匹配成功

看看獨佔模式
獨佔模式和貪婪模式很像,獨佔模式會儘可能多地去匹配,如果匹配失敗就結束,不會進行回溯,這樣的話就比較節省時間
具體寫法
在量詞後加上 +
| 正則 | 文本 | 匹配結果 |
| xy{1,3}+z | xyyz | xyyz |

注意事項
Python 和 Go 的標準庫目前都不支援獨佔模式
Python 支援獨佔模式
需要安裝 regex
pip install regex
Python 獨佔模式栗子
>>> import regex 4 >>> regex.findall(r'xy{1,3}z', 'xyyz') # 貪婪模式 ['xyyz'] >>> regex.findall(r'xy{1,3}+z', 'xyyz') # 獨佔模式 ['xyyz'] >>> regex.findall(r'xy{1,2}+yz', 'xyyz') # 獨佔模式 []
再來一個栗子

a{1,3}+ab 去匹配 aaab 字元串,a{1,3}+ 會把前面三個 a 都用掉,並且不會回溯,這樣字元串中內容只剩下 b 了,導致正則中加號後面的 a 匹配不到符合要求的內容, 匹配失敗
如果是貪婪模式 a{1,3} 或非貪婪模式 a{1,3}? 都可以匹配上
獨佔模式總結
- 獨佔模式性能比較好,可以節約匹配的時間和 CPU 資源
- 但有些情況下並不能滿足需求(上面的栗子)
- 要想使用這個模式還要看具體需求,另外還得看你當前使用的語言或庫的支援程度


