python之詞雲與『結巴』
- 2019 年 10 月 8 日
- 筆記
在python中,你的數據收集到了之後除了可以直接打開來看,做成表格看以外,還可以做詞雲。
第一次使用詞雲,需要先安裝wordcloud的庫
第一種:pip install wordcloud
第二種:pycharm-在setting中的project interpreter中右邊的+號點擊進去,然後輸入wordcloud就可以安裝了。

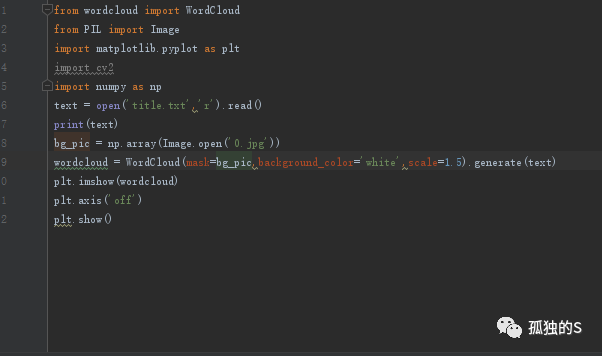
簡單的一個wordcloud例子
大概過程就是:
導入庫
打開文本文件,或者直接調用文本數據
然後設置底圖
然後調用wordcloud中的WordCloud函數傳入數據,設置數據。
顯示出來
效果圖:

詞雲中選用的數據是之前爬取知乎的python問題的題目。
底圖是這個路飛的形狀,然後數據也很好的契合到這個輪廓裡面,如果的底圖沒有分明的輪廓,像這種圖片有個白底的那樣子的話,那個數據可能就會全覆蓋了。
這裡要安裝的庫有numpy,PIL,以及wordcloud和matplotlib,
因為這個wordcloud的generate是不支援中文格式的,於是引用一下windows的字體一下。

結果就成這樣了。
引用的程式碼
wordcloud = WordCloud(
mask=bg_pic,background_color='white',scale=4,
font_path='C:WindowsFontssimhei.ttf').generate(text)
差不多就是最後一句了,這裡是黑體,如果你要想要其他屬性,可以進入這個目錄:C:WindowsFonts,(這裡是windows10,其他版本的目前沒去測試)右鍵你要的字體然後看屬性

然後就可以複製他的這個名字去調用了。
在這裡,他的底圖的調用有兩種不同的情況
第一種,用cv2來獲取圖片
bg_pic = cv2.imread('0.jpg')
第二種,用PIL的Image模組來獲取圖片
bg_pic = np.array(Image.open('0.jpg'))
兩種方法都是一樣的,一開始我誤解以為有不一樣的效果,其實都一樣。
jieba分詞:
jieba是一款python中文組件
下面是一個簡單例子:

安裝
在pycharm貌似安裝不了,但是可以直接用pip install jieba來安裝。
然後import jieba 就可以使用了。
分詞的方法就在上面的例子,很簡單,不過不能直接print jieba.cut(text),需要用。join()來獲取分完的結果。
jieba分詞有三個特點:
精確模式:將句子最精確的切開,適合文本分析
全模式: 把句子中所有的可以成詞的詞語都掃描出來,速度很快,但是不能解決歧義
搜索引擎模式:
在精確模式的基礎對長的詞再次切分。適用於搜索引擎的分詞。
這裡就是簡單介紹一下結巴分詞和wordcloud,如果你想更深的去了解的話可以去網上找專門的介紹文檔,或者教程。
