【MobileNet V1】2017-CVPR-MobileNets Efficient Convolutional Neural Networks for Mobile Vision Applications-論文閱讀
- 2020 年 6 月 1 日
- 筆記
- 2020年, model compression, paper
MobileNet V1
- 2017-CVPR-MobileNets Efficient Convolutional Neural Networks for Mobile Vision Applications
- Andrew Howard、Hartwig Adam(Google)
- GitHub: 1.4k stars
- Citation:4203
Introduction
本文介紹了一種新的網路結構,MobileNet(V1),網路結構上與VGG類似,都屬於流線型架構,但使用了新的卷積層——深度可分離卷積(depthwise separable convonlution)替換了原始的全卷積層,使得網路參數和計算量都大大減小,在0.12倍的計算量和0.14倍的參數量的情況下,精度僅下降1%,引入兩個超參數(寬度乘數、解析度乘數),可以方便的構建更小的MobileNet,在模型大小和精度之間平衡。屬於網路壓縮中的輕量化網路設計的方法。
Motivation
隨著深度學習的流行,卷積網路的計算開銷越來越大,因此人們開始尋找減少網路參數/計算量的方法,設計更高效的模型。
Contribution
輕量化網路(較小的計算開銷和存儲開銷)主流的方法有兩種
- 減少模型參數,既可以減少模型計算開銷,也可減少模型存儲開銷
- 量化模型參數,可以減少存儲開銷
MobileNet使用深度可分離卷積來替代傳統的全卷積,有效的地降低了模型參數量和計算量。
Method
深度可分離卷積(depthwise separable convolution)
深度可分離卷積是MobileNet的核心。深度可分離卷積是因子卷積(將大卷積分解為小的卷積?)的一種,將標準的全卷積分解為通道深度卷積(depthwise convolution)+1×1逐點卷積(pointwise convolution);其中深度卷積是將同一個filter應用到所有的input channels上,點卷積是將1×1的卷積核,應用在深度卷積的output channels上。傳統的conv是將濾波乘法(feature map元素乘法)和通道合併(將多個channels map整合成一個channels)兩個步驟在一步完成;而深度可分離卷積是將兩個步驟分開,一層用於濾波乘法,一層用於通道合併。
標準卷積:
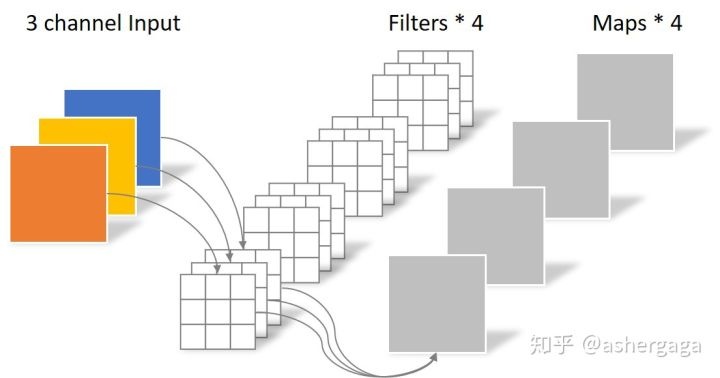
通道卷積:
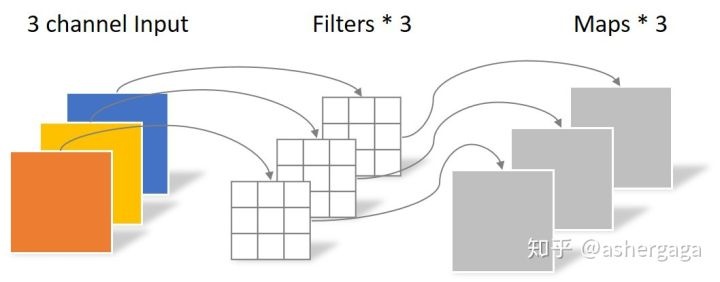
逐點卷積:
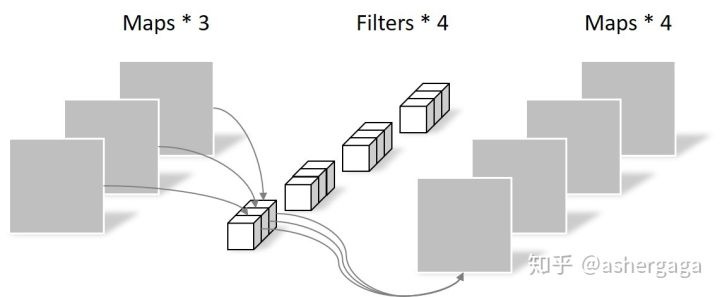
計算開銷對比:
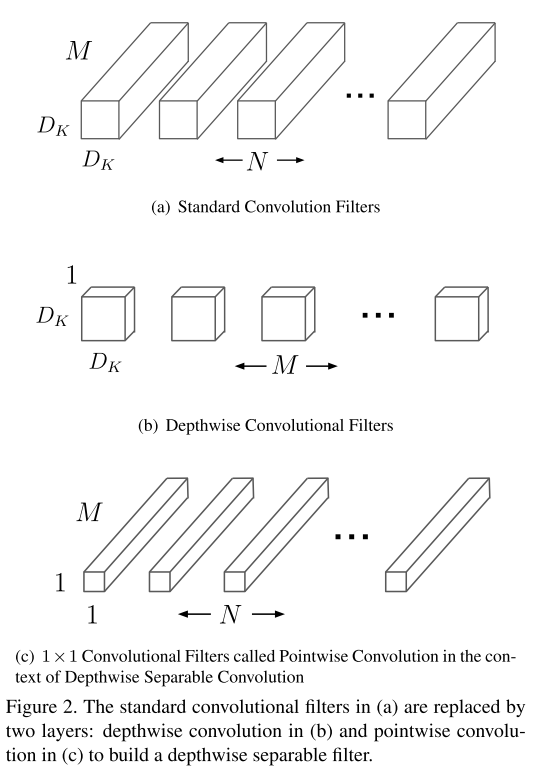
標準卷積的計算開銷: \(D_{K} \cdot D_{K} \cdot M \cdot N \cdot D_{F} \cdot D_{F}\)
深度可分離卷積的計算開銷: \(D_{K} \cdot D_{K} \cdot M \cdot D_{F} \cdot D_{F}+M \cdot N \cdot D_{F} \cdot D_{F}\)
&&計算開銷的計算:參數數量×一個feature map的大小
計算開銷對比: $\frac{D_{K} \cdot D_{K} \cdot M \cdot D_{F} \cdot D_{F}+M \cdot N \cdot D_{F} \cdot D_{F}}{D_{K} \cdot D_{K} \cdot M \cdot N \cdot D_{F} \cdot D_{F}} = \frac{1}{N}+\frac{1}{D_{K}^{2}} $
網路結構
MobileNet的除了第一個卷積層是標準卷積,其餘的卷積層都是深度可分離卷積。
表1為MobileNet的網路結構,將通道卷積層和點卷積層看做單獨的層,則MobileNet共有28層(1全卷積 + 2 × 13深度可分離卷積 + 1全連接 = 28)。
&&有參數的層才算入?
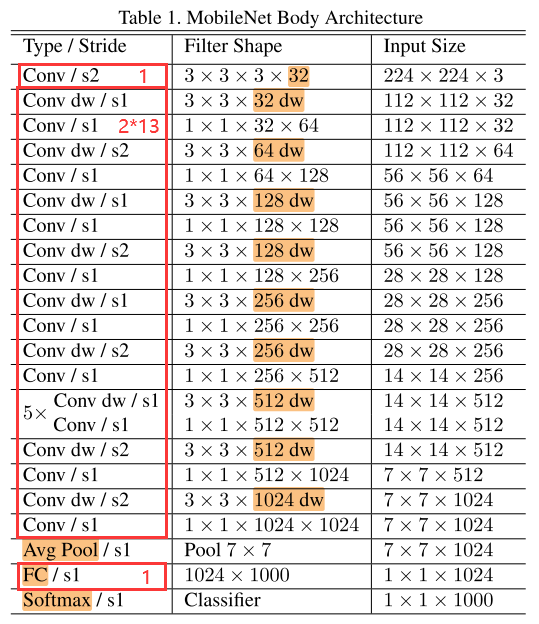
圖3對比了標準卷積層和可分離卷積層(通道卷積層+逐點卷積層),每個卷積層後都跟著BN層和ReLU層。

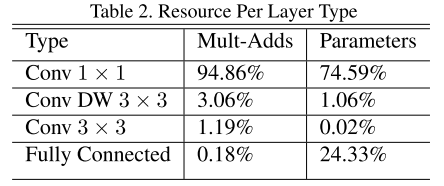
表2為MobileNet中不同類型的層的計算量和參數量對比:
寬度乘數 α(Width Multiplier)
為了構建更小的MobileNet,引入第一個超參數——Width Multiplier α,在α的作用下,網路的計算代價變為: \(D_{K} \cdot D_{K} \cdot \alpha M \cdot D_{F} \cdot D_{F}+\alpha M \cdot \alpha N \cdot D_{F} \cdot D_{F}\)
α的取值範圍(0,1],取1時就是baseline MobileNet
應用寬度乘數可以將計算開銷和存儲開銷變為為原來的 \(\alpha^2\) 倍
解析度乘數 ρ(Resolution Multiplier)
解析度乘數可以減小輸入圖片的解析度,一般通過設置輸入圖片的解析度來隱式地設置 \(\rho\)
同時應用寬度乘數和解析度乘數,計算代價變為:
\(D_{K} \cdot D_{K} \cdot \alpha M \cdot \rho D_{F} \cdot \rho D_{F}+\alpha M \cdot \alpha N \cdot \rho D_{F} \cdot \rho D_{F}\)
其中,ρ∈(0, 1],通常隱式設置網路的輸入解析度為224、192、160或128。
應用寬度乘數可以將計算開銷和存儲開銷變為為原來的 \(\rho^2\) 倍。
表3對比了全卷積、深度可分離卷積、應用了α和ρ的深度可分離卷積的模型的計算量和參數量:

Experiments
全卷積的MobileNet VS MobileNet:

在相近的計算量下,瘦長的MobileNet 和 胖矮的MobileNet 的精度對比,瘦長的MobileNet效果更好,說明層數更重要(所以是使用寬度層數α,改變模型寬度,而不是減少模型的層數):

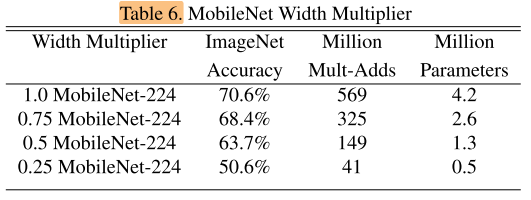
應用了寬度乘數α的MobileNet效果對比:
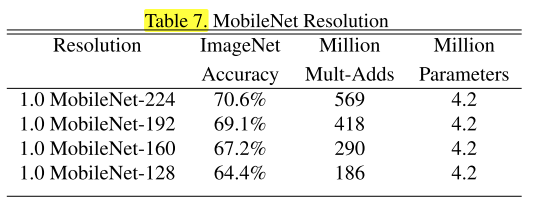
應用了解析度乘數ρ(輸入解析度不同)的MobileNet效果對比:
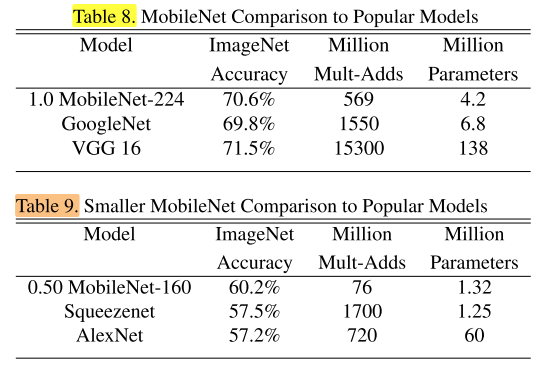
在ImageNet上與經典網路的對比:
在Stanford Dogs數據集上與經典網路的對比:

其他實驗:
細粒度識別實驗、大規模地理定位實驗、Face Attributes實驗、Object Detection實驗、Face Embeddings實驗
Conclusion
-
提出了新的輕量模型MobileNet,核心是使用深度可分離卷積代替標準全卷積,大大減少計算量和參數量
-
通過寬度乘數和解析度乘數2個超參數很好的在baseline MobileNet的基礎上構建更小的MobileNet模型
Summary
-
想法很簡單,效果很好!
-
實驗非常豐富!
Reference
【深度可分離卷積】//zhuanlan.zhihu.com/p/92134485
【薰風讀論文:MobileNet 詳解深度可分離卷積,它真的又好又快嗎?】//zhuanlan.zhihu.com/p/80177088

