Web Scraper——輕量數據爬取利器
- 2020 年 5 月 23 日
- 筆記
- web scraper, 簡易數據分析

日常學習工作中,我們多多少少都會遇到一些數據爬取的需求,比如說寫論文時要收集相關課題下的論文列表,運營活動時收集用戶評價,競品分析時收集友商數據。
當我們著手準備收集數據時,面對低效的複製黏貼工作,一般都會萌生一個想法:我要是會爬蟲就好了,分分鐘就把數據爬取下來了。可是當我們搜索相關教程時,往往會被高昂的學習成本所勸退。拿現在最通用的 python 爬蟲來說,對於小白來說往往要跨過下面幾座大山:

- 學習一門程式語言:python
- 學習網頁的基礎構成——HTML 標籤和 CSS 選擇器,有時候還要了解一些 JavaScript
- 學習網路通訊的基礎協議——HTTP 協議
- 學習 python 中常見的爬蟲框架和解析庫
- ……
上面的知識點,沒有幾個月是掌握不完的。而且對於非強需求的人來說,這麼多的知識點,你還會時時刻刻和遺忘做鬥爭。
那麼有沒有不學 python 也能爬取數據的利器呢?結合文章標題,我想你已經知道我要安利什麼了。今天我要推薦的就是Web Scraper,一個輕量的數據爬蟲利器。

Web Scraper 的優點就是對新手友好,在最初抓取數據時,把底層的編程知識和網頁知識都屏蔽了,可以非常快的入門,只需要滑鼠點選幾下,幾分鐘就可以搭建一個自定義的爬蟲。
我在過去的半年裡,寫了很多篇關於 Web Scraper 的教程,本文類似於一篇導航文章,把爬蟲的注意要點和我的教程連接起來。最快一個小時,最多一個下午,就可以掌握 Web Scraper 的使用,輕鬆應對日常生活中的數據爬取需求。
插件安裝
Web Scraper 作為一個 Chrome 插件,網路條件良好的用戶可以直接上chrome 網上應用店安裝,不太好的用戶可以下載插件安裝包手動安裝,具體的安裝流程可以看我的教程:Web Scraper 的下載與安裝。
常見網頁的類型
結合我的數據爬取經驗和讀者回饋,我一般把網頁分為三大類型:單頁、分頁列表和篩選表單。
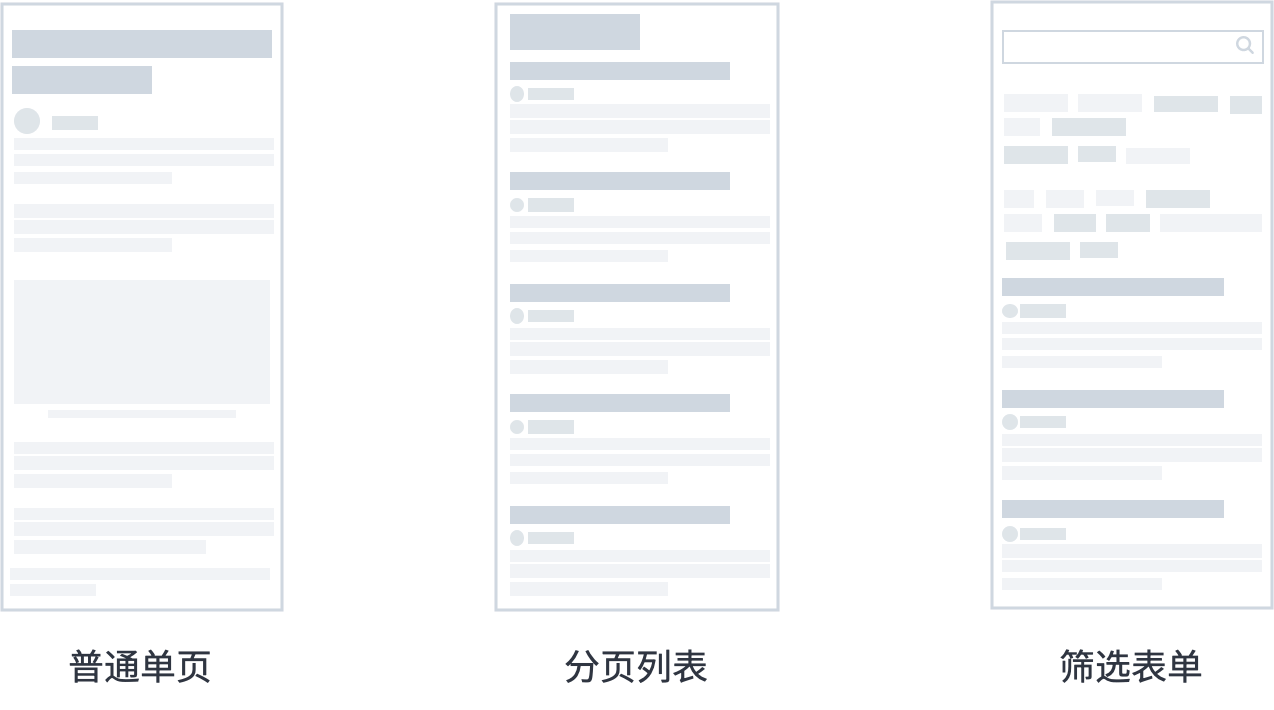
1.單頁
單頁是最常見的網頁類型。
我們日常閱讀的文章,推文的詳情頁都可以歸於這種類型。作為網頁里最簡單最常見的類型,Web Scraper 教程里第一篇爬蟲實戰就拿豆瓣電影作為案例,入門 Web Scraper 的基礎使用。
2.分頁列表
分頁列表也是非常常見的網頁類型。
互聯網的資源可以說是無限的,當我們訪問一個網站時,不可能一次性把所有的資源都載入到瀏覽器里。現在的主流做法是先載入一部分數據,隨著用戶的交互操作(滾動、篩選、分頁)才會載入下一部分數據。
教程里我費了較大的筆墨去講解 Web Scraper 如何爬取不同分頁類型網站的數據,因為內容較多,我放在本文的下一節詳細介紹。
3.篩選表單
表單類型的網頁在 PC 網站上比較常見。
這種網頁的最大特點就是有很多篩選項,不同的選擇會載入不同的數據,組合多變,交互較為複雜。比如說淘寶的購物篩選頁。
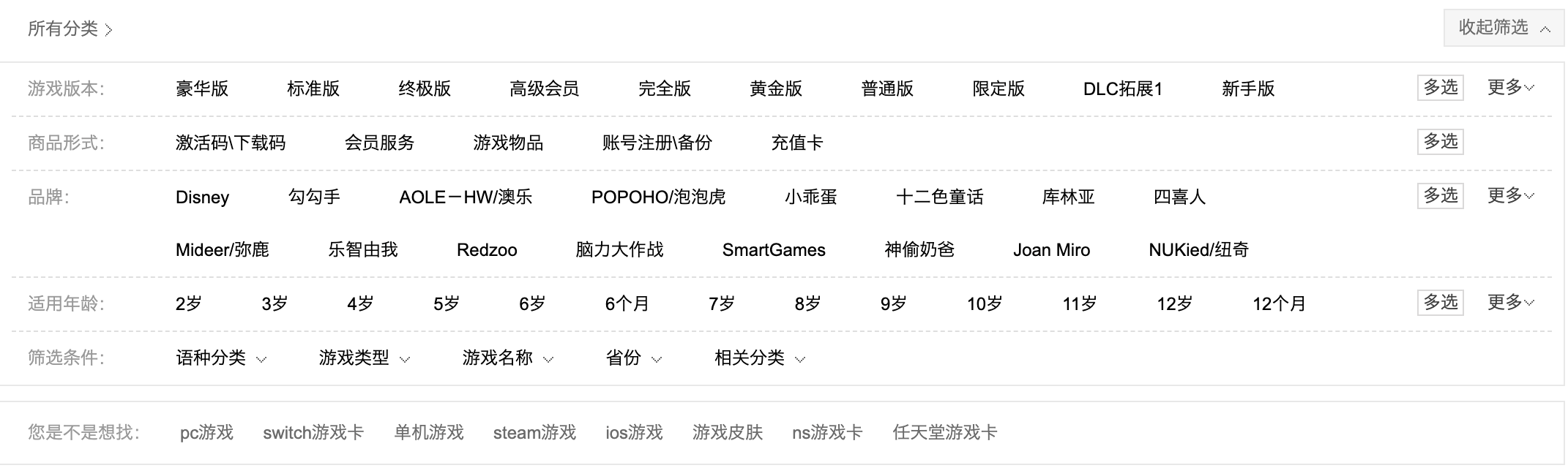
比較遺憾的是,Web Scraper 對複雜篩選頁的支援不是很好,如果篩選條件可以反映在 URL 鏈接上就可以爬取相關數據,如果不能就無法爬取篩選後的數據。
常見的分頁類型
分頁列表是很常見的網頁類型。根據載入新數據時的交互,我把分頁列表分為 3 大類型:滾動載入、分頁器載入和點擊下一頁載入。

1.滾動載入

我們在刷朋友圈刷微博的時候,總會強調一個『刷』字,因為看動態的時候,當把內容拉到螢幕末尾的時候,APP 就會自動載入下一頁的數據,從體驗上來看,數據會源源不斷的載入出來,永遠沒有盡頭。
Web Scraper 有一個選擇器類型叫 Element scroll down,意如其名,就是滾動到底部載入的意思。利用這個選擇器,就可以抓取滾動載入類型的網頁,具體的操作可以見教程:Web Scraper 抓取「滾動載入」類型網頁。
2.分頁器載入

分頁器載入數據的網頁在 PC 網頁上非常常見,點擊相關頁碼就能跳轉到對應網頁。
Web Scraper 也可以爬取這種類型的網頁。相關的教程可見: Web Scraper 控制鏈接分頁、Web Scraper 抓取分頁器類型網頁 和 Web Scraper 利用 Link 選擇器翻頁。
3.點擊下一頁載入
點擊下一頁按鈕載入數據其實可以算分頁器載入的一種,相當於把分頁器中的「下一頁」按鈕單獨拿出來自成一派。
這種網頁需要我們手動點擊載入按鈕來載入新的數據。Web Scraper 可以 Element click 選擇器抓取這種分頁網頁,相關教程可見:Web Scraper 點擊「下一頁」按鈕翻頁。
進階使用
學習了上面列出的幾篇教程,Web Scraper 這個插件 60% 的功能基本上就掌握了。下面是一些進階內容,掌握了可以更高效的抓取數據。
1.列表頁 + 詳情頁

互聯網資訊最常見的架構就是「列表頁 + 詳情頁」的組合結構了。
列表頁是內容的標題和摘要,詳情頁是詳細說明。有時候我們需要同時抓取列表頁和詳情頁的數據,Web Scraper 也支援這種常見的需求。我們可以利用 Web Scraper 的 Link 選擇器來抓取這種組合網頁,具體操作可以看教程:Web Scraper 抓取二級網面。
2.HTML 標籤與 CSS 選擇器

我在前面說了 Web Scraper 屏蔽了一些網頁知識,比如說 HTML 和 CSS 的一些內容,只需要簡單的滑鼠點選就可以搭建一個自定義爬蟲。但是如果我們花半個小時了解一些基礎的 HTML 和 CSS 知識,其實可以更好的使用 Web Scraper。所以我專門寫了一篇介紹 CSS 選擇器的文章,十分鐘讀下來可以上手自定義 CSS 選擇器。
3.正則表達式的使用

Web Scraper 其實是一款專註於文本爬取的爬蟲工具。如果你日常工作中經常和文本打交道,或者使用過一些效率工具,那你一定聽說過正則表達式。沒錯,Web Scraper 也支援基礎的正則表達式,用來篩選和過濾爬取的文本,我也寫了一篇文章介紹正則表達式,如果爬取過程中使用它,可以節省不少數據清洗的時間。
4.Sitemap 的導入和導出
SItemap 是個什麼東西?其實它就是我們操作 Web Scraper 後生成的配置文件,相當於 python 爬蟲的源程式碼。我們可以通過分享 Sitemap 來分享我們製作的爬蟲,相關操作我也寫了教程:Web Scraper 導入導出爬蟲配置。
5.換一個存儲資料庫

Web Scraper 導出數據時有一個缺點,默認使用瀏覽器的 localStorage 存儲數據,導致存儲的數據是亂序的。這種情況可以通過 Excel 等軟體進行排序,也可以通過換一個數據存儲庫的方式來解決。
Web Scraper 支援 CouchDB 資料庫,配置成功後導出的數據就是正序了。相關的配置過程可以看我寫的教程:Web Scraper 使用 CouchDB。
Web Scraper 的優點
- 輕量:非常的輕量。上手只需要一個 Chrome 瀏覽器和一個 Web Scraper 插件。對於一些限制安裝第三方軟體的公司電腦,可以很輕易的突破這層限制
- 提效:Web Scraper 支援絕大多數的網頁的爬取,可以無侵入的加入你的日常工作流中
- 快:抓取速度取決於你的網速與瀏覽器載入速度,其他的數據採集軟體可能有限速現象(充錢就能不限速)
Web Scraper 的缺點
- 只支援文本數據抓取:圖片短影片等多媒體數據無法批量抓取
- 不支援範圍抓取:例如一個網頁有 1000 條數據,默認是全量抓取的,無法配置抓取範圍。想停止抓取,只能斷網模擬數據載入完畢的情況
- 不支援複雜網頁抓取:對於那些加了複雜交互、酷炫的特效和反人類的反爬蟲網頁,Web Scraper 無能為力(其實這種網頁寫 python 爬蟲也挺頭疼)
- 導出數據亂序:想讓數據正序就得用 Excel 或者用 CouchDB,相對複雜了一些
總結
掌握了 Web Scraper 的使用,基本上可以應付學習工作中 90% 的數據爬取需求。相對於 python 爬蟲,雖然靈活度上受到了限制,但是低廉的學習成本可以大大節省學習時間,快速解決手頭的工作,提高整體的工作效率。綜合來看,Web Scraper 還是非常值得去學習的。
聯繫我
因為文章發在各大平台上,帳號較多不能及時回複評論和私信,有問題可關注公眾號 ——「鹵代烴實驗室」,(或 wx 搜索 egglabs)關註上車防失聯。


