Django ORM性能優化之count和len方法的選擇(非常詳細推薦乾貨)
接下來我將從源碼層面分情況和應用分析我們在計算queryset數據集時是用orm的count函數計算長度還是用len函數計算數據集長度。
首先,我們知道ORM查詢queryset數據集是惰性查詢的,只有使用到數據集時,ORM才會真正去執行查詢語句,然後ORM會把查詢到的數據集快取到記憶體中,下次我們使用數據集時是從快取中取值的。這就是ORM的惰性查詢機制和快取機制,還不清楚可以找相應的部落格了解其概念,首先理解這兩點我們便能更好地理解接下來的場景及應用。
1.、場景一:queryset數據集已經使用然後快取的情況下,我們使用queryset對象.count()方法時其底層源碼是用的len()方法計算數量,所以在有快取時用len()和count()是一樣的;
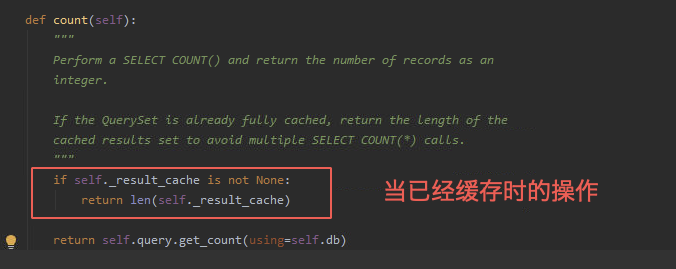
2、場景二:如果我們只想獲得queryset對象的長度而不使用queryset對象的其他操作的情況下,count函數底層用了資料庫的聚合函數查詢計算結果,
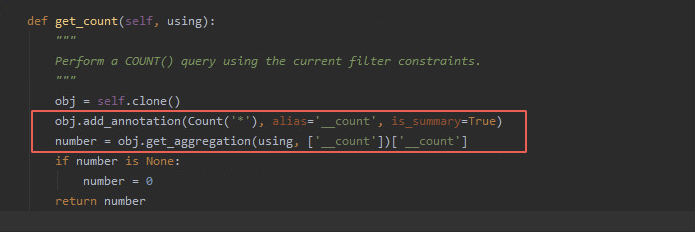
然後取其結果時間複雜度是O(1),而len方法底層實現是是需要獲取整個queryset數據集時間複雜度為O(n),並且空間複雜度也為O(n),

這種場景下使用count函數更好;
3、場景三:在初始我們寫了ORM查詢語句,然後接下來我們既要計算查詢後結果集的長度,又要對結果集做其他操作(如獲取每個queryset對象的屬性等),(這裡暫時不考慮分頁時limit減小查詢範圍的情況)。
接下來我們分析len方法和count方法他們分別會做什麼事情,首先如果是len操作的話會先觸發orm的查詢操作得到queryset結果集然後快取,然後後續對結果集的操作直接從快取中取對應的queryset對象,然後是count函數操作因為之前我們講過ORM的惰性查詢機制,在我們執行count函數的時其實這時查詢操作還未真正的運行,也就是此時還沒有queryset結果集的快取,所以此時我們執行count方法會執行一次聚合函數查詢,然後後續我們使用到queryset集合時就會觸發資料庫查詢得到queryset結果集然後快取。
所以在場景三的情況下,使用len()方法計算結果集的長度時會比count方法會更有優勢,因為此時少了一次對數據的聚合查詢操作。
4、場景四:如果是在先執行了資料庫查詢結果集並使用到了queryset結果有了快取的情況下,參考場景一此時用len方法或者count方法的效果是一樣的。
5、場景五:這也是最複雜也比較難判斷的情況,首先步驟一:我們寫了資料庫查詢操作(此時還未使用到這個查詢的結果集),然後步驟二這裡我們可能使用len方法或者count方法來計算結果集的長度,接下來步驟三我們使用分頁組件對結果集進行分頁處理,再步驟四使用我們分頁後的結果集。
這種場景的話對於步驟二我們是使用len方法還是count方法來計算結果集的長度時就需要我們考慮以下幾個因素了,
1)如果此時我們使用的是len方法的話我們會快取整個queryset結果集,並相當於遍歷了整個結果集時間複雜度為O(n),空間複雜度為O(n),步驟三的分頁操作對於我們後端的時間或者空間來說都沒什麼太大幫助了
2)如果此時我們使用的是count()方法來計算長度的話,我們會多一次資料庫查詢操作,但是步驟三的分頁操作相當於查詢結果集時sql語句然後limit 10(數字取決於我們分頁的size),這樣我們的時間複雜度和空間複雜度都可以降到O(1)
個人傾向的話可能在此種情況我會使用count方法,通過多一次資料庫查詢操作來降低時間和空間的複雜度還是挺划算的。

