
爬虫的基本原理
- 2022 年 10 月 14 日
- 笔记
一、爬虫的基本原理 网络爬虫的价值其实就是数据的价值,在互联网社会中,数据是无价之宝,一切皆为数据,谁拥有了大量有用的数 …
Continue Reading一、爬虫的基本原理 网络爬虫的价值其实就是数据的价值,在互联网社会中,数据是无价之宝,一切皆为数据,谁拥有了大量有用的数 …
Continue Reading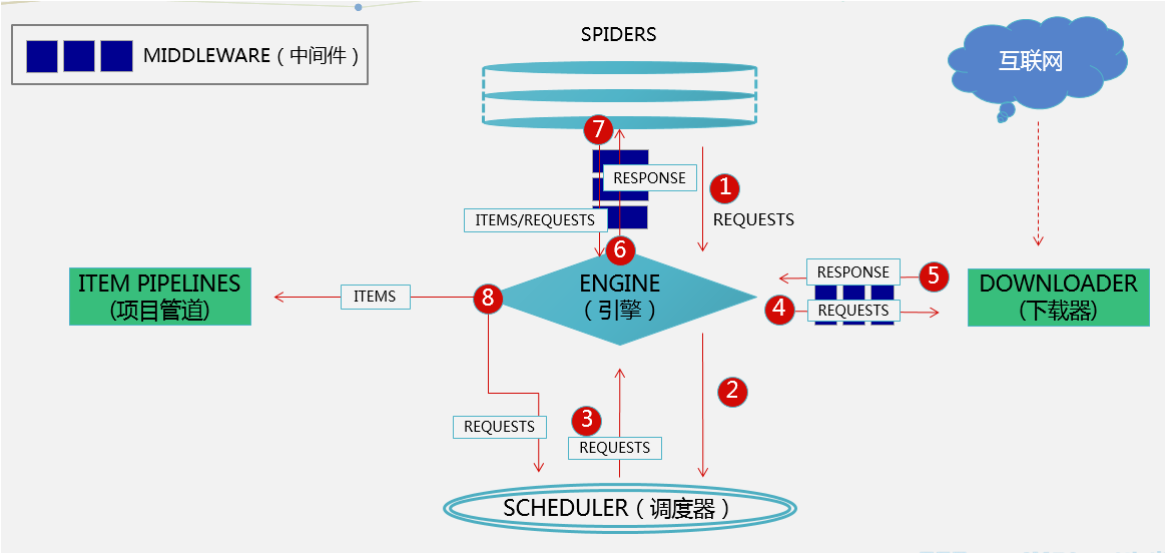
一、Scrapy 介绍 Scrapy是一个Python编写的开源和协作的框架。起初是用于网络页面抓取所设计的,使用它可以 …
Continue Reading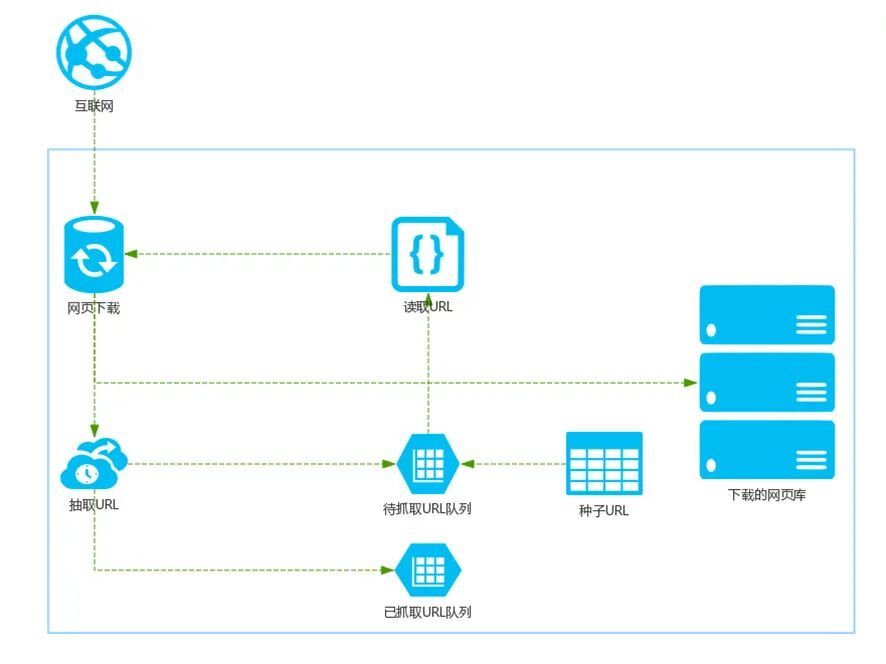
vivo 互联网安全团队- Xie Peng 互联网的大数据时代的来临,网络爬虫也成了互联网中一个重要行业,它是一种自动 …
Continue Reading
Python逆向爬虫之初体验 网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 说起网络爬虫,人们常常 …
Continue Reading
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编 …
Continue Reading
检查网页源代码 首先让我们来检查豆瓣top250的源代码,一切网页爬虫都需要从这里开始。F12打开开发者模式,在元素(e …
Continue Reading
导入包 # json包 import json #正则表达式包 import re import requests fr …
Continue Reading
什么是正则表达式? 正则表达式是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子。 一个正则 …
Continue Reading
摘要:本文讲述如何编写scrapy爬虫。 本文分享自华为云社区《学python,怎么能不学习scrapy呢,这篇博客带你 …
Continue Reading
目录 selenium介绍 基本使用 selenium用法 元素操作 等待元素被加载 元素各项属性 执行js代码 切换选 …
Continue Reading