【深度学习】——深度学习中基本的网络结构(2)
本节主要复习一下深度学习中这些常见的网络结构在tensorflow(1.x)中的使用,便于后续tensorflow的学习。
1. 全连接网络结构
全连接网络就是后层的每一个神经元均与前一层的神经元有关,按照上一节的推导,zl=w*al-1+b,然后再经过激活函数记得到了第l层的神经元al:
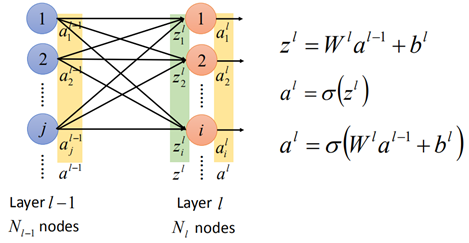
那么在tensorflow中的实现如下:
# w为权重,b为偏置,x为第l-1层的输出,这些均为tensor
# 假设x输入[100],al-1输出[10],事先定义w和b变量
w = tf.Variable(tf.randon_normal([100, 10]))
b = tf.Variable(tf.zeros([10]))
# z = w*x + b
z_l = tf.add(tf.matmal(x, w), b)
# al = sigmoid(z_l)
a_l = tf.nn.sigmoid(z_l)这样就完成了1个全连接层,其中w,b是参数需要事先进行定义。
2. 卷积神经网络
卷积神经网络在【机器学习】中有一定的介绍,在那边主要使用的keras进行简单的实现,这里结合更多的例子,用tensorflow来进行实现。
首先定义几个输入图片的尺寸:
# shape依次为:batch_size, height, width, channel
inputs = tf.Variable(tf.constant(1.0, shape=[1, 5, 5, 1]))
input2 = tf.Variable(tf.constant(1.0, shape=[1, 5, 5, 2]))
input3 = tf.Variable(tf.constant(1.0, shape=[1, 4, 4, 1]))然后是filter,有以下几种filter:
"""
filter的shape依次为:height, width, channel, output_channel
height, width表示filter的大小, channel表示通道数,这个通道数与input的channel是一致的,也就是inputs的第四维,
output_channel为输出的feature map个数,也就是filter的个数
"""
# 第一个filter 大小2*2,只有1个filter
filter1 = tf.Variable(tf.constant([-1.0, 0, 0, -1], shape=[2, 2, 1, 1]))
# 第二个filter 大小2*2,有2个filter
filter2 = tf.Variable(tf.constant([-1.0, 0, 0, -1, -1, 0, 0, -1], shape=[2, 2, 1, 2]))
# 第三个filter 大小2*2,有3个filter
filter3 = tf.Variable(tf.constant([-1.0, 0, 0, -1, -1, 0, 0, -1, -1, 0, 0, -1], shape=[2, 2, 1, 3]))
# 第四个filter 大小2*2,有2个filter,输入的channel为2
filter4 = tf.Variable(tf.constant([-1.0, 0, 0, -1.0,
-1.0, 0, 0, -1,
-1.0, 0, 0, -1,
-1.0, 0, 0, -1], shape=[2, 2, 2, 2]))
# 第五个filter,大小2*2,有1个filter,输入的channel为1
filter5 = tf.Variable(tf.constant([-1.0, 0, 0, -1, -1.0, 0, 0, -1], shape=[2, 2, 2, 1]))在tensorflow中卷积层的定义如下:
tf.nn.conv2d(input, filter, strides, padding, use_cuda_on_gpu)input和filter说过了,strides是在卷积时在每一维上的步长,也就是1个四维的向量,一般在batch_size和output_channel上都是1。
padding是否填充边缘的元素,只能取“SAME”和“VALID”,“SAME”表示边缘补0,而“VALID”表示不补0,只有当stride为1时,“SAME”才能生成与输入一致的尺寸。
关于padding不同取值,决定着输出图片尺寸的大小,当为“VALID”情况时:
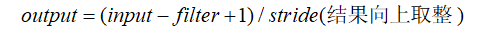
当padding为“SAME”时,输出大小与卷积核的大小没有关系,只与stride有关:
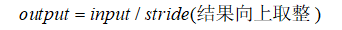
use_cuda_on_gpu表示是否在gpu上加速,默认为True。
那么接下来就根据上面的输入,根据不同的filter进行卷积:
# 输入5*5*1的图片,经过1个2*2的filter,步长为2, 那么输出为1个3*3的feature map
op1 = tf.nn.conv2d(inputs, filter1, strides=[1, 2, 2, 1], padding="SAME")
# output: shape=(1, 3, 3, 1)
# 输入5*5*1的图片,经过2个2*2的filter,步长为2,那么输出为2个3*3的feature map
op2 = tf.nn.conv2d(inputs, filter2, strides=[1, 2, 2, 1], padding="SAME")
# output: shape=(1, 3, 3, 2)
# 输入依旧5*5*1,经过3个2*2的filter,步长为2,输出则为3个3*3的feature map
op3 = tf.nn.conv2d(inputs, filter3, strides=[1, 2, 2, 1], padding="SAME")
# output: shape=(1, 3, 3, 3)
# 输入为5*5*1, 但经过filter的channel为2,与输入的维度不一致,会报错
op_s = tf.nn.conv2d(inputs, filter4, strides=[1, 2, 2, 1], padding="SAME")
# ValueError: Depth of input (1) is not a multiple of input depth of filter (2) for 'Conv2D_2' (op: 'Conv2D') with input shapes: [1,5,5,1], [2,2,2,2].
# 输入5*5*2的图片,有2个channel,经过2个2*2的filter,输出则为2个3*3的feature map
op4 = tf.nn.conv2d(input2, filter4, strides=[1, 2, 2, 1], padding="SAME")
# output: shape=(1, 3, 3, 2)
# 输入5*5*2, 经过1个2*2的有2个channel的filter,输出则为1个3*3的feature map
op5 = tf.nn.conv2d(input2, filter5, strides=[1, 2, 2, 1], padding="SAME")
# output: shape=(1, 3, 3, 1)
# 输入5*5*1,经过1个2*2的filter,padding=VALID,输出为(5-2+1)/2=2
v_op1 = tf.nn.conv2d(inputs, filter1, strides=[1, 2, 2, 1], padding="VALID")
# output: shape=(1, 2, 2, 1)
# 输入4*4*1,经过1个2*2的filter, padding=SAME,输出为4/2=2
op6 = tf.nn.conv2d(input3, filter1, strides=[1, 2, 2, 1], padding="SAME")
# output: shape=(1, 2, 2, 1)
# 输入4*4*1,经过1个2*2的filter, padding=VALID,输出为(4-2+1)/2=2
v_op6 = tf.nn.conv2d(input3, filter1, strides=[1, 2, 2, 1], padding="VALID")
# output: shape=(1, 2, 2, 1)卷积之后一般还有池化,下面是池化的方法:
tf.nn.max_pool(input, ksize, strides, padding, name)
tf.nn.avg_pool(input, ksize, strides, padding, name)
input是输入,ksize跟卷积中的filter一样,这里需要注意的是,第一维和第四维一般为1,因为一般不在batch和channel上做池化,输出channel一般与输出一致。其它与卷积中的参数一致。
下面举个例子,输入图片为:
img = tf.constant([[[0.0, 4.0], [0.0, 4.0], [0.0, 4.0], [0.0, 4.0]],
[[1.0, 5.0], [1.0, 5.0], [1.0, 5.0], [1.0, 5.0]],
[[2.0, 6.0], [2.0, 6.0], [2.0, 6.0], [2.0, 6.0]],
[[3.0, 7.0], [3.0, 7.0], [3.0, 7.0], [3.0, 7.0]]])
img = tf.reshape(img, [1, 4, 4, 2])# 输入均为4*4*2
# filter大小为2*2,步长为2,输出为(4-2+1)/2=2,输出channel依旧是2
pooling1 = tf.nn.max_pool(img, [1, 2, 2, 1], [1, 2, 2, 1], padding='VALID')
# output: shape=(1, 2, 2, 2)
# filter大小为2*2,步长为1,输出为(4-2+1)/1=3,输出channel依旧为2
pooling2 = tf.nn.max_pool(img, [1, 2, 2, 1], [1, 1, 1, 1], padding='VALID')
# output: shape=(1, 3, 3, 2)
# avg_pool跟max_pool类似,filter大小4*4,步长1,"SAME"与卷积核无关,输出为4/1=4
pooling3 = tf.nn.avg_pool(img, [1, 4, 4, 1], [1, 1, 1, 1], padding='SAME')
# output: shape=(1, 4, 4, 2)
# filter4*4,步长为4,"SAME"与卷积核无关,输出为4/4=1
pooling4 = tf.nn.avg_pool(img, [1, 4, 4, 1], [1, 4, 4, 1], padding='SAME')
# output: shape=(1, 1, 1, 2)此外还有反卷积操作和反池化操作,首先是反卷积,在【机器学习基础】中说过,其实反卷积就是一种卷积,不过是在边缘补0之后再进行卷积,在tensorflow中有函数来实现:
tf.nn.conv2d_transpose(input, filter, output_shape, strides, padding)input表示输入;
filter是指在原图在卷积时所使用的filter;
output_shape反卷积后的尺寸大小,也就是原图经过卷积前的尺寸;
strides表示原图经过卷积时的strides;
padding表示原图在卷积时使用的padding
下面是示例:
# 原图片,并经过卷积
img = tf.Variable(tf.constant(1.0, shape=[1, 4, 4, 1]))
filter = tf.Variable(tf.constant([1.0, 0, -1, -2], shape=[2, 2, 1, 1]))
conv = tf.nn.conv2d(img, filter, strides=[1, 2, 2, 1], padding='VALID')
cons = tf.nn.conv2d(img, filter, strides=[1, 2, 2, 1], padding='SAME')
# 反卷积过程,所有参数与卷积过程保持一致,输出则为img的尺寸
contv = tf.nn.conv2d_transpose(conv, filter, [1, 4, 4, 1], strides=[1, 2, 2, 1], padding="VALID")
conts = tf.nn.conv2d_transpose(cons, filter, [1, 4, 4, 1], strides=[1, 2, 2, 1], padding="SAME")然后接下来是反池化,在【机器学习】基础中,反池化的原理也已经过了,这里就不再赘述。
这里直说实现,对于反池化的操作,有一点比较麻烦的在池化过程中,我们要知道哪一个元素被选为最大,在反池化时,要将对应的元素还原,其他元素置为0。因此,池化时还需要记录被选中的那一个元素。
因此,这里需要对池化操作重新写,tensorflow中提供了记录最大值的方法tf.nn.max_pool_with_argmax方法,下面是修改后的池化操作,放在这里后面可以直接用:
# 返回值是池化后的网络以及对应的索引值
def max_pool_with_argmax(net, stride):
_, mask = tf.nn.max_pool_with_argmax(net, ksize=[1, stride, stride, 1], strides=[1, stride, stride, 1], padding='SAME')
mask = tf.stop_gradient(mask)
net = tf.nn.max_pool(net, ksize=[1, stride, stride, 1], strides=[1, stride, stride, 1], padding='SAME')
return net, mask有了返回的索引,就可以进行反池化操作了,反池化没有现成的函数,需要自己实现,下面是实现过程,记下便于后续使用:
def unpool(net, mask, stride):
ksize = [1, stride, stride, 1]
input_shape = net.get_shape().as_list()
# 计算new_shape
output_shape = (input_shape[0], input_shape[1] * ksize[1], input_shape[2]*ksize[2], input_shape[3])
one_like_mask = tf.ones_like(mask)
batch_range = tf.reshape(tf.range(output_shape[0], dtype=tf.int64), shape=[input_shape[0], 1, 1, 1])
b = one_like_mask * batch_range
y = mask // (output_shape[2] * output_shape[3])
x = mask % (output_shape[2] * output_shape[3]) // output_shape[3]
feature_range = tf.range(output_shape[3], dtype=tf.int64)
f = one_like_mask * feature_range
update_size = tf.size(net)
indices = tf.transpose(tf.reshape(tf.stack([b, y, x, f]), [4, update_size]))
values = tf.reshape(net, [update_size])
ret = tf.scatter_nd(indices, values, output_shape)
return ret下面举个例子来进行池化和反池化操作:
img = tf.constant([[[0.0, 4.0], [0.0, 4.0], [0.0, 4.0], [0.0, 4.0]],
[[1.0, 5.0], [1.0, 5.0], [1.0, 5.0], [1.0, 5.0]],
[[2.0, 6.0], [2.0, 6.0], [2.0, 6.0], [2.0, 6.0]],
[[3.0, 7.0], [3.0, 7.0], [3.0, 7.0], [3.0, 7.0]]])
img = tf.reshape(img, [1, 4, 4, 2])
# 池化操作,stride=2,一般在max_pool时设定步长与stride一致
pool, mask = max_pool_with_argmax(img, 2)
# 反池化
img2 = unpool(pool, mask, 2)
with tf.Session() as sess:
print('img', img)
result = sess.run(img2)
print('img2', result)
可以看到img2和img在尺寸上是一致的,但是数值不太一样,这在前面说过,对与不是最大值的部分填充0。
有了上面的基本结构,就可以构建一个简单的CNN深度网络了,下面是是一个基本的网络结构示例:
# 先定义初始化参数的函数,不必每次遇到参数定义就初始化一次,直接调用
def weight_variable(shape):
initial = tf.Variable(tf.truncated_normal(shape, std=0.1))
return initial
# 同样定义bias
def bias_variable(shape):
initial = tf.Variable(tf.constant(0.1, shape=shape))
return initial
# 定义卷积函数,每次直接调用即可
def conv2d(x, w):
return tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding="SAME")
# 输入占位符,图片大小24*24*3
x = tf.placeholder(tf.float32, [batch_size, 24, 24, 3])
# 输出占位符,10个类别
y = tf.placeholder(tf.float32, [batch_size, 10])
# 第一个卷积层的卷积核参数,有64个5*5*3的filter
w_conv1 = weight_variable([5, 5, 3, 64])
# 卷积后需要加上一个bias, 卷积后为64个feature map,所以bias维度为64
b_conv1 = bias_variable([64])
# 卷积操作,一般卷积层后会接RELU,输出的尺寸为24/1=24,channel为64
h_conv1 = tf.relu(conv2d(x, w_conv1) + b_conv1)
# 然后是池化操作,池化后尺寸为12*12*64
h_pool1, mask1 = max_pool_with_argmax(h_conv1, 2)
# 第二层卷积的卷积核参数,有64个5*5*64的
w_conv2 = weight_varibale([5, 5, 64, 64])
b_conv2 = bias_varibale([64])
# 第二次卷积操作,卷积后依旧12*12*64
h_conv2 = tf.relu(conv2d(h_pool1, w_conv2) + b_conv2)
# 第二次池化,池化后尺寸6*6*64
h_pool2, mask2 = max_pool_with_argmax(h_conv2, 2)
# 接下来反池化操作,对h_pool2进行反池化,得到第二次卷积后的结果
t_conv2 = unpool(h_pool2, mask2, 2)
# 然后是反卷积,反卷积后,与第一次池化结果对应
# 反卷积操作中要减掉bias
t_pool1 = tf.nn.conv2d_transpose(t_conv2 - b_conv2, w_conv2, h_pool1.shape, [1, 1, 1, 1])
# 再次反池化,返回到第一次卷积后的结果
t_conv1 = unpool(t_pool1, mask1, 2)
# 再次反卷积,反卷积后即回到初始的x
t_x = tf.nn.conv2d_transpose(t_conv1 - b_conv1, w_conv1, x.shape, [1, 1, 1, 1])
# 紧接着在第二次池化后,在进行一次卷积池化操作
w_conv3 = weight_varibale([5, 5, 64, 10])
b_conv3 = bias_variable([10])
# 第三次卷积后的输出为6*6,channel为10
h_conv3 = tf.nn.relu(conv2d(h_pool2, w) + b_conv3)
# 最后经过一个6*6的avg_pool,输出为1*1,channel为10
h_pool3 = tf.nn.avg_pool(h_conv3, [1, 6, 6, 1], strides=[1, 6, 6, 1], padding="SAME")
# 将h_pool3展开,输入到softmax
h_pool3_flat = tf.reshape(h_pool3, [-1, 10])
# 可以再接几层fc
fc1 = tf.layers.dense(h_pool3_flat, 64, activation=tf.nn.tanh)
fc2 = tf.layers.dense(fc1, 64, activation=tf.nn.tanh)
y_pred = tf.layers.dense(fc2, 10, activation=tf.nn.softmax)这样,一个三层的卷积神经网络就好了,在卷积后的三层其实可以再接几层fc层。
以上就是一个较为完整的网络的实现了。
这里需要注意:反卷积和反池化的作用主要是为了实现可视化、或者还原原图像分辨率的问题,并没有参与训练。
另外,关于卷积后需要加bias的问题,当卷积后接Bath Normalization(后面会说)时,是不需要加bias的。
3. RNN
RNN中有多种结构,除了基本的basic RNN,还有LSTM、GRU。在使用RNN时,需要预先定义好cell,然后再将cell连接起来,构成RNN网络。
tensorflow中包含了上面几种cell的定义:
3.1basic RNN
首先是basic RNN,该cell的定义如下:
tf.contrib.rnn.BasicRNNCell(num_units, input_size=None, activation=tanh)num_units表示隐藏节点的个数,也就是ht的维度,input_size废弃了不再使用。
定义一个basic RNN cell也比较简单,只需指定好n_hidden的大小即可:
basic_rnn_cell = tf.contrib.rnn.BasicRNNCell(n_hidden)
3.2 LSTM
然后是LSTM,也是类似,LSTM定义为:
tf.contrib.rnn.BasicLSTMCell(num_units, forget_bias=1.0, state_in_tuple, activation)num_units一样表示隐藏层节点的个数,forget_bias是添加到遗忘门的偏置,表示保留多少信息,默认为1。
state_in_tuple是否将记忆c和h以tuple的形式分开,当为True时输出tuple(c=array(), h=array()),当为False时两个连接起来[batch, 2n],该参数即将废弃。
定义一个basic LSTMcell:
basic_lstm = tf.contrib.rnn.BasicLSTMCell(n_hidden, forget_bias=1.0)
这样就定义好了一个基本的LSTM结构。
还有另一个LSTM的高级版本版本,除了上面的参数外,还有一些其他的参数:

3.3 GRU
GRU的定义也是一样的:
tf.contrib.rnn.GRUCell(num_units, input_size=None, activation=tanh) basic_gru = tf.contrib.rnn.GRUCell(n_hidden)
3.4 MultiRNN
上面就是几个基本cell的定义,当然,cell不单单是某一种,可以是多种组合起来的多层cell,其定义:
tf.contrib.rnn.MultiRNNCell(cells, state_in_tuple)cells就是一个cell的列表,该列表为一系列basic cell组成,cells=[cell1, cell2]就表示有两层数据经过cell1后还要经过cell2.
state_in_tuple于basic rnn中类似,将记忆cell与隐藏状态输出h组成一个tuple。
注意:在使用MultiCell时,cells不能直接用[cell]×n的写法,如果不使用作用域会报错,而是要用append的写法。
创建一个多层的cell:
cell1 = tf.contrib.rnn.BasicLSTMCell(n_hidden)
cell2 = tf.contrib.rnn.GRUCell(n_hidden)
#如果两个cell的n_hidden,则输出以最后一个节点为准
multi_rnn = tf.contrib.rnn.MultiRNNCell([cell1, cell2])3.5 RNN的连接
上面构建出基本的RNN cell时只是某一个时刻的状态,接下来还要把Cell连接起来,才能构成完整的RNN网络。
RNN的连接方式可以分为静态、动态,单向RNN和双向RNN,再结合上面的单层的cell和多层的cell,那么RNN各种条件自由组合,可以有8中不同的连接。
这里所谓的静态和动态,是指在创建RNN时,RNN预先创建好的结构,这时需要输入的长度要与该结构保持一致;
因此静态的因为预先创建好,会花费较多的时间和占用空间,但其优点是可以查看任一时刻的输出,便于调试;
而动态则是指比较灵活地根据输入去创建cell,通过循环来创建的。
因此动态的创建快,节省内存,便于不同长度的输入的批处理,但缺点是只能查看序列最终状态,不方便调试。
静态的创建方式:
tf.contrib.rnn.static_rnn(cells, input, initial_state=None, sequence_length=None, scope=None)
cells为前面说的cell;
input为输入;
initial_state初始化状态参数,一般初始化为0时,不需刻意指定,要是想要初始化指定的值用initial_state=LSTMStateTuple(c_state, h_state)
sequence_lenght一般不需要指定,会根据输入自动识别;
scope:命名空间。
动态的创建方式:
tf.contrib.rnn.dynamic_rnn(cells, input, initial_state=None, sequence_length=None, time_major, scope=None)
参数基本与静态的一致,这里多了一个time_major,默认为False时,input_shape=[batch_size, max_time, …..], 当为True时,input_shape=[max_time, batch_size, ….]
接下来就是各种RNN的实现方式:
3.5.1 单向的RNN:
① 单层静态单向RNN
# 输入x为n_step*n_input,即n_step个时间点,每个时间点的维度为n_input
x = tf.placeholder(tf.float32, [None, n_steps, n_input])
# 先创建一个lstm cell
lstm_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden)
# 静态单层RNN
# 需要先转换x的形状为预设形状
x1 = tf.unstack(x, n_steps, 1)
outputs, states = tf.contrib.rnn.static_rnn(lstm_cell, x1, dtype=tf.float32)
# outputs包括结果和cell的状态,只需关注结果,最后一维才是结果
pred = tf.contrib.layers.fully_connected(couputs[-1], 10, activation_fn=None)②多层静态单向RNN
x = tf.placeholder(tf.float32, [None, n_steps, n_input])
# 先创建多层的cells
cells = []
for i in range(3):
cells.append(tf.contrib.rnn.BasicLSTMCell(n_hidden))
multi_cell = tf.contrib.rnn.MultiRNN(cells)
x1 = tf.unstack(x, n_steps, 1)
# 多层静态单向RNN
outputs, states = tf.contrib.rnn.static_rnn(multi_cell, x1, dtype=tf.float32)
pred = tf.contrib.layers.fully_connected(outputs[-1], 10, activation_fn=None)③单层动态单向RNN
x = tf.placeholder(tf.float32, [None, n_steps, n_input])
# 先创建basic cell
lstm_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden)
# 动态单层单向RNN
outputs, state = tf.contrib.rnn.dynamic_rnn(lstm_cell, x, dtype=tf.float32)
outputs = tf.transpose(outputs, [1, 0, 2])
pred = tf.contrib.layers.fully_connected(outputs[-1], 10, activation_fn=None)④多层动态单向RNN
x = tf.placeholder(tf.float32, [None, n_steps, n_input])
# basic cell
lstm_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden*2)
gru_cell = tf.contrib.rnn.GRUCell(n_hidden)
# 构建多层cell
multi_cells = tf.contrib.rnn.MultiRNNCell([lstm_cell, gru_cell])
# 多层动态单向RNN
outputs, state = tf.contrib.rnn.dynamic_rnn(multi_cells, x, dtype=tf.float32)
outputs = tf.transpose(outputs, [1, 0, 2])
pred = tf.contrib.layers.fully_connected(outputs[-1], 10, activation_fn=None)从上面的代码可以看到,静态和动态的区别再输入和输出的格式转化,主要有两点:
1、静态的输入需要将输入转换成list的形式,而动态网络不需要转换。这是因为静态是预先设定好的,必须按照设定的输入;
2、动态的输出需要进行转置操作,而静态的则不需要。这是因为动态网络输出形式为[batch_size, max_time, …],
转置[1, 0, 2]是将第0维max_time放在后面,将batch_size放在第1维,这样转换后变为[max_time, batch_size,…..], 取最后一维时就是最后一个时间点的数据[batch_size, ……]
3.5.2 双向的RNN
双向的RNN在单层和多层之间的定义还是有所差别的,对于单层的CELL的静态RNN定义:
tf.contrib.rnn.static_bidirectional_rnn(cell_fw, cell_bw, inputs)
对于单层的动态RNN定义如下:
tf.nn.bidirectional_dynamic_rnn(cell_fw, cell_bw, inputs)
而对于多层的静态RNN定义:
tf.contrib.rnn.stack_bidirectional_rnn(cells_fw, cells_bw, inputs)
对于多层动态的RNN定义:
tf.contrib.rnn.stack_bidirectional_dynamic_rnn(cells_fw, cells_bw, inputs)
从上面的四个定义可以看出:
无论是单层还是多层,均需一个前向的cell和一个反向的cell,且前向的cell和反向的cell的结构必须保持一致;
对于单层的定义没有“stack”,多层的需要带“stack”,其中单层动态的来自于tf.nn模块;
而对于多层的cells可以接受列表的形式,也可以接受Multi形式的cell,后面举例说明。
① 单层静态双向RNN
x = tf.placeholder(tf.float32, [None, n_steps, n_input])
# 对于静态的而言,输入要调整为list
x1 = tf.unstack(x, n_stpes, 1)
# 先创建basic cell,前向和反向
cell_fw = tf.contrib.rnn.BasicLSTMCell(n_hidden)
cell_bw = tf.contrib.rnn.GRUCell(n_hidden)
# 单层静态双向RNN
outputs, _, _ = tf.contrib.rnn.static_bidirectional_rnn(cell_fw, cell_bw, x1)
pred = tf.contrib.layers.fully_connected(outputs[-1], 10, activation_fn=None)②单层动态双向RNN
x = tf.placeholder(tf.float32, [None, n_steps, n_input])
cell_fw = tf.contrib.rnn.BasicLSTMCell(n_hidden)
cell_bw = tf.contrib.rnn.GRUCell(n_hidden)
outputs, _, _ = tf.nn.bidirectional_dynamic_rnn(cell_fw, cell_bw, x, dtype=tf.float32)
# 动态rnn的输出需要进行转化为[max_time, batch_size, ....]
outputs = tf.transpose(outputs, [1, 0, 2])
pred = tf.contrin.layers.fully_connected(outputs[-1], 10, activation_fn=None)③多层静态双向RNN
x = tf.placeholder(tf.float32, [None, n_steps, n_input])
x1 = tf.unstack(x, n_steps, 1)
cell_fw = tf.contrib.rnn.BasicLSTMCell(n_hidden)
cell_bw = tf.contrib.rnn.GRUCell(n_hidden)
# 创建多层静态双向RNN,多层的只需将cell放入列表即可,但必须保证前向与后向结构一致
outputs, _, _ = tf.contrib.rnn.stack_bidirectional_rnn([cell_fw], [cell_bw], x1, dtype=tf.float32)
pred = tf.contrib.layers.fully_connected(outputs[-1], 10, activation_fn=None)
# 多层的也接受multi cell
stack_cells_fw = []
stack_cells_bw = []
for i in range(3):
stack_cells_fw.append(tf.contrib.rnn.BasicLSTMCell(n_hidden))
stack_cells_bw.append(tf.contrib.rnn.BasicLSTMCell(n_hidden))
multi_cells_fw = tf.contrib.rnn.MultiRNNCell(stack_cells_fw)
multi_cells_bw = tf.contrib.rnn.MultiRNNCell(stack_cells_bw)
outputs, _, _ = tf.contrib.rnn.stack_bidirectional_rnn([multi_cells_fw], [multi_cells_bw], x1, dtype=tf.float32)
......④多层动态双向RNN
x = tf.placeholder(tf.float32, [None, n_steps, n_input])
stack_cells_fw = []
stack_cells_bw = []
for i in range(3):
stack_cells_fw.append(tf.contrib.rnn.BasicLSTMCell(n_hidden))
stack_cells_bw.append(tf.contrib.rnn.BasicLSTMCell(n_hidden))
# 多层动态双向RNN
outputs, _, _ = tf.contrib.rnn.stack_bidirectional_dynamic_rnn(stack_cells_fw, stack_cells_bw, x, dtype=tf.float32)
outputs = tf.transpose(outputs, [1, 0, 2])
pred = tf.contrib.layers.fully_connected(outputs[-1], 10, activation_fn=None)
# 也接受Multi cell
multi_cells_fw = tf.contrib.rnn.MultiRNNCell(stack_cells_fw)
multi_cells_bw = tf.contrib.rnn.MultiRNNCell(stack_cells_bw)
outputs, _, _ = tf.contrib.rnn.stack_bidirectional_dynamic_rnn([multi_cells_fw], [multi_cells_bw], x, dtype=tf.float32)
......以上就是RNN的基本结构的实现过程,下面利用MNIST数据集,使用RNN训练一个模型:
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.examples.tutorials.mnist import input_data
# 读取数据
mnist = input_data.read_data_sets("/data/", ont_hot=True)
# 参数设置
learning_rate = 0.001
traning_iters = 100000
batch_size = 128
display_step = 10
# 网络的参数
# 图片尺寸28*28,当做序列长度为28,每一个时刻的维度为28
n_inputs = 28 # 每一个序列的维度
n_steps = 28 # 序列长度
n_hidden = 128 # 隐藏层的输出维度
n_classes = 10 # 0~9 10个类别
# 初始化图
tf.reset_default_graph()
# 输入、输出的占位符
x = tf.placeholder("float", [None, n_steps, n_input])
y = tf.placeholder("float", [None, n_classes])
# 这里采用多层双向动态RNN
# 定义前向、后向basic cells
stack_cells_fw = []
stack_cells_bw = []
for i in range(3):
stack_cells_fw.append(rnn.BasicLSTMCell(n_hidden))
stack_cells_bw.append(rnn.GURCell(n_hidden))
# 转为multi_cells
multi_cells_fw = rnn.MultiRNNCell(stack_cells_fw)
multi_cells_bw = rnn.MultiRNNCell(stack_cells_bw)
# 创建多层双向动态RNN
outputs, _, _ = rnn.stack_bidirectional_dynamic_rnn([multi_cells_fw], [multi_cells_bw], x, dtype=tf.float32)
outputs = tf.transpose(outputs, [1, 0, 2])
# 输出值后接一个全连接网络,输出为10维,classes
pred = tf.contrib.layers.fully_connected(outputs[-1], n_classes, activation_fn=None)
# 计算loss,采用cross_entropy
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
# 梯度下降
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
# 估计正确率
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(corrected_pred, tf.float32))
# 启动session开始训练
with tf.Session() as sess:
# 初始化
sess.run(tf.global_variables_initializer())
step = 1
while step * batch_size < training_iters:
# 批数据
batch_x, batch_y = mnist.train.next_batch(batch_size)
# 将batch_x 转成x的形状
batch_x = batch_x.reshape([batch_size, n_steps, n_input])
sess.run(optimizer, feed_dict={x:batch_x, y: batch_y})
# 打印训练过程
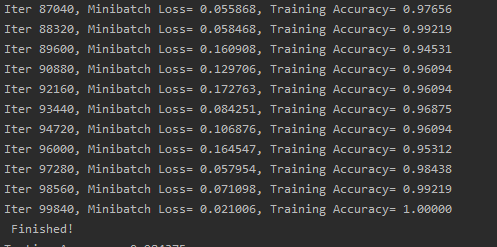
if step%display_step == 0:
# 计算这一轮的精度
acc = sess.run(accuracy, feed_dict={x: batch_x, y: batch_y})
# 计算损失
cost = sess.run(loss, feed_dict={x: batch_x, y: batch_y})
print('Iter' + str(step * batch_size) + ', Mini-batch loss= ', + '{:.6f}'.format(cost) + ', Training Accuracy=' + '{:.5f}'.format(acc))
step += 1
print('Finished')
# 计算在测试集上的准确率
test_len = 128
test_data = mnist.test.images[:test_len].reshape([-1, n_steps, n_input])
test_labels = mnist.test.labels[:test_len]
print('Testing Accuracy:', sess.run(acc, feed_dict={x: test_data, y: test_labels}))