基于 GraphQL 的 BFF 实践
- 2022 年 5 月 24 日
- 笔记
随着软件工程的发展,系统架构越来越复杂,分层越来越多,分工也越来越细化。我们知道,互联网是离用户最近的行业,前端页面可以说无时无刻不在变化。前端本质上还是用户交互和数据展示,页面的高频变化意味着对数据需求的高频变化。在绝大多数场景中,页面数据都来自于服务端,因此对页面变化的感知势必会传递到服务端,而服务端是要做业务能力沉淀的,需要逐步完善领域模型,沉淀商业逻辑,所以就产生了一个矛盾,一个领域能力沉淀和高频数据变化的矛盾。
为了解决这个矛盾,在业界不断的探索实践中,逐渐在架构层面演化出一个 BFF 层,Backend For Frontend,顾名思义,专门响应前端需求的服务端。
我们知道,不同的团队,因为其面临的业务场景不同,在面对相似问题的时候,通常解法也会不同。本文会结合笔者之前的 BFF 实践经验,介绍一种基于 GraphQL 的 BFF 实现。
BFF
Backend For Frontend 在 15/16 年的时候开始逐步受到关注,经过多年的实践和发展,业界已经有了非常多的解决方案,各种技术栈的实践都有。个人认为,要想准确的理解 BFF,需要抛开具体的技术细节和业务场景,从团队协作的角度来看。
BFF 的诞生是为了解决服务端领域能力沉淀和前端多样化的数据需求之间的矛盾的。因此,凡是有助于减少前端和服务端之间的冲突,降低开发成本的,都属于 BFF 讨论的范围。
我们从下面几个方面讨论一下 BFF 的适用场景。
-
数据聚合裁剪
通常,为了降低页面对服务端开发的影响,服务端会单独分离出一层 API 层,专门响应页面需求。但是由于缺乏一些明确的约束和指导,由于各种各样的原因,慢慢的 API 层中会出现一些业务逻辑,导致 API 层与业务层边界模糊,影响到对页面需求的响应。
-
SSR
现在提到 SSR,通常会理解成基于 NodeJS + React/Vue 的服务端渲染。其实,在早些时候,还有基于模板的实现,知名的模板引擎有 Apache Velocity(Java)、EJS(JS)等。
-
上传下载
上传下载是一个比较常见的业务场景,但是常常因为功能比较通用化,很难作为一个业务能力被沉淀到业务系统中。
-
接口转发
在一些场景中,不需要聚合其他接口就能满足页面需求,可以直接将页面请求转发给领域服务。但是往往又因为需要登录、鉴权等一系列的校验逻辑,导致无法直接通过 Nginx 做转发,需要一层服务来处理,比如上面说的 API 层。
在这些问题中,我们可以看到,有些问题服务端开发比较擅长,有些问题前端开发比较擅长。这也正好印证了 BFF 本身的定位。
在构建 BFF 服务的时候,我们需要回答好一个问题,那就是由谁来构建 BFF?
我们先来分析下前端和服务端构建 BFF 的优缺点。
| 谁来构建 | 优势 | 劣势 |
|---|---|---|
| 前端 | 能对页面的多样化需求做出快速反应,几乎没有沟通成本 | 需要具备后端开发能力,对人的要求更高;同时需要前端深入理解业务模型 |
| 服务端 | 对业务模型理解更加透彻;服务管理的工具更丰富 | 对页面的需求不敏感 |
从表格中我们可以看到,不管是前端还是服务端来构建 BFF,都有其优势和劣势。因此我们还是需要结合具体的场景和需求来判断和选择。
如果在系统中数据聚合裁剪需求比较复杂,而页面变化相对可控,那么可以选择由服务端来建设 BFF。如果业务中页面变化频率很高,比如营销页面,那么由前端来负责构建 BFF 相对来说总体更优。
总之,不管是前端做还是服务端做,主要还是要看哪种成本更低,对需求的及时交付帮助更大。
GraphQL
前面讨论了 BFF 适用的几种场景,其中数据聚合裁剪可以说是最常见、冲突最大的一个。GraphQL 及其生态给出了一套解决方案。

在官方定义中,GraphQL 有两层含义:
- 一种用于 API 的查询语言。
- 一种运行时,使用现有数据完成这些查询的运行时。
在上面这张图中,我们通过 DSL 来描述系统中的类型。每一个类型就是一个节点,多个节点以及节点之间的关系最终会生成一张图。我们所有的查询都是基于这张图来做的。可以形象的理解一下,我们每一次查询,都是从图中的某一个节点开始,拎出一棵树出来。
GraphQL 有如下几个特点:
- 按需返回数据,不多不少,且数据有极强的确定性
- 端上描述需要的数据字段、嵌套结构等,服务器按描述返回。同时字段类型、字段是否为空等都有明确的约定。
- 合并请求
- 可以将页面中的多个数据请求合并成一个 GraphQL 查询。在弱网环境下尤其有用。
- 完善的类型系统
- 通过 Schema 描述系统中所有的模型,包括字段类型、模型结构、模型之间的关系等。通过内省模式可以查询到系统中的所有 Schema 信息,效果同 API 文档。
- 围绕类型系统,可以开发出很多高效的工具,比如客户端代码生成工具 GraphQL Code Generator。
- API 的平滑升级,无版本
- 新增字段不影响已有查询
- 标记 Deprecated 字段在内省模式中会自动标出
- 字段细粒度控制
- 通过定义合适的 Resolver,可以对系统中任意模型、任意字段进行细粒度控制。比如类型转换、监控埋点等。
基于 GraphQL 的 BFF 实践
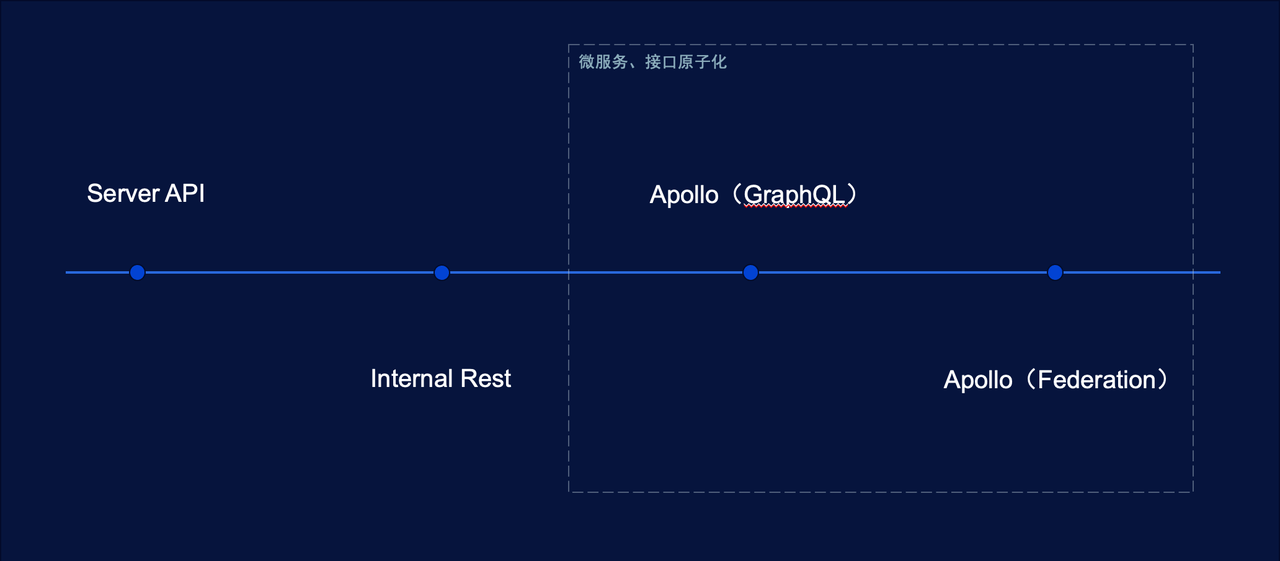
图中从左到右分别有四个演变阶段。在虚线框以前,主要是服务端在负责页面的数据聚合。其中 Server API 是业务逻辑直接对外提供 API。Internal Rest 是分化出来的 API 层,专职于页面数据聚合。随着微服务的推广,服务端逐渐按领域划分微服务,对外提供原子化的接口。业务按照领域划分出微服务以后,人员的组织架构也会相应的调整(康威定律),原有的 Internal Rest 层没有专职团队负责,代码逐渐腐化、难以维护,进而影响迭代交付速度。
这时候,我们就在思考通过一些技术手段来解决这个问题。下面是我们的具体实践经历,以及后来的方案演进。
NestJS + Apollo GraphQL
社区中有很多优秀的 NodeJS 框架,比如 koa、express、eggjs 等,我们之所以选择了 NestJS 主要是两点考虑。一是 NestJS 原生采用 TypeScript 开发,提供了完善的类型支持,对于服务端开发而言,其重要性是不言而喻的。二是 NestJS 提供了丰富的框架能力,比如说拦截器、过滤器、守卫等,相比中间件来说,功能更丰富,定位也更明确。
Apollo GraphQL 是社区里比较成功的 GraphQL 解决方案,有丰富的商业化案例。而且,NestJS 对 Apollo 有官方的集成支持。
下面我们通过一个样例来展示一下上面介绍的 GraphQL 相关的能力。
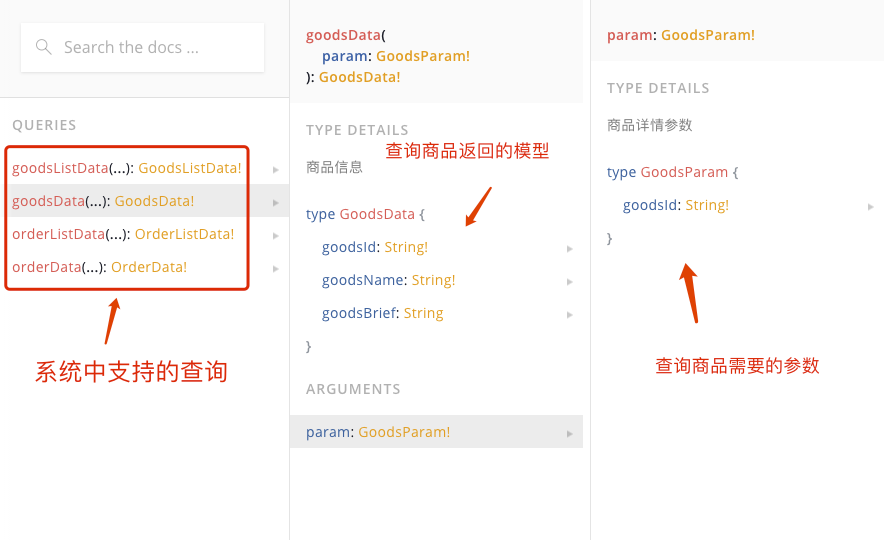
在样例中,我们定义了商品和订单两个模型,并定义了一些查询。下面是内省模式下看到的系统中的模型信息。
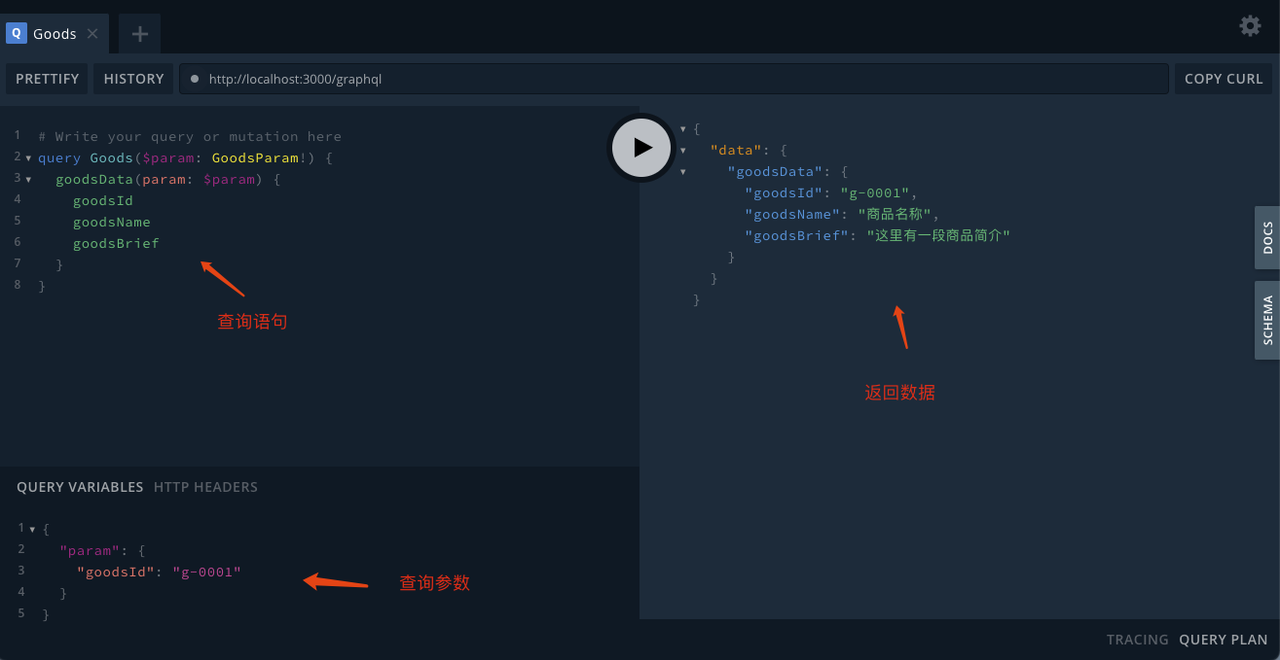
我们可以在 playground 中进行数据查询,如下是查询商品信息的样例。
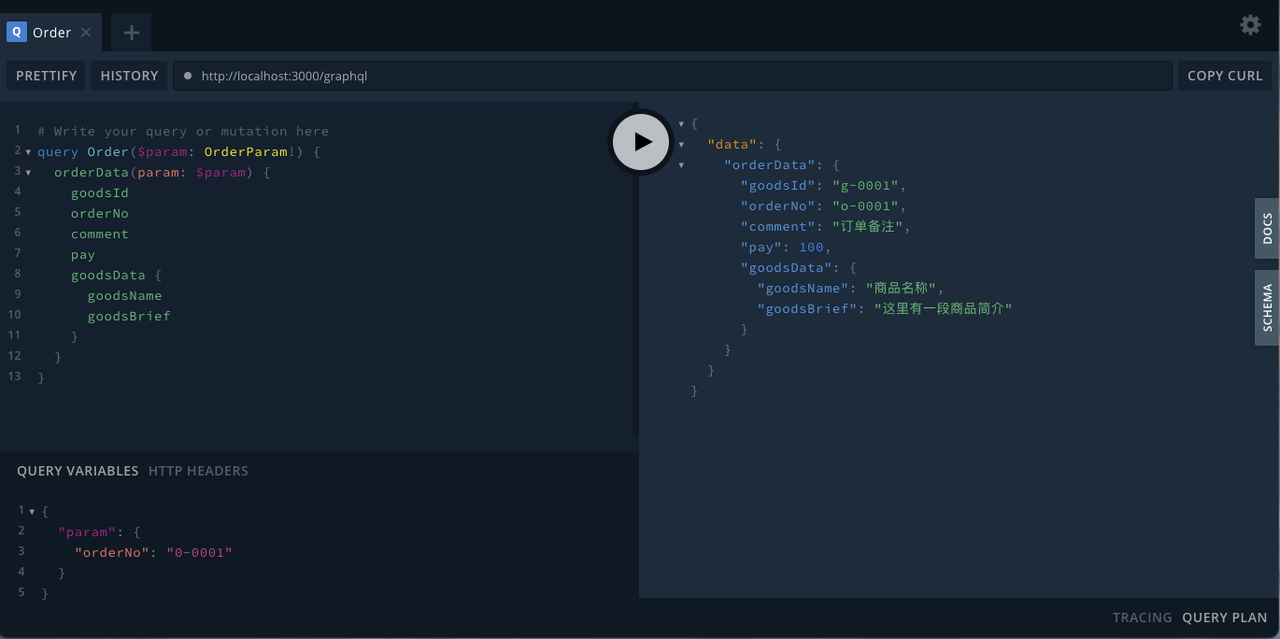
订单信息中通常还需要关联查询商品信息,下面是查询样例。
可以看到,GraphQL 很好的解决了数据聚合裁剪的问题。但是在业务量级提升、系统覆盖业务越来越多的时候,逐渐暴露出两个严重的问题。第一个是可靠性问题,单体服务容易出现单点故障。第二个是发布效率问题,不同业务由于使用了同一个 BFF 服务,常常出现发布冲突,需要排队等待。因此我们又进行了第二阶段的探索。
Apollo Federation
我们先用一张图简单描述一下 Federation 架构的组成。
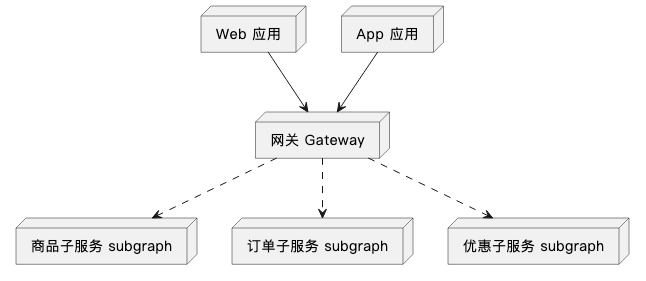
在 Federation 架构中,各个团队只负责自身业务范围内的子图构建,在网关层,Federation Gateway 会将这些子图拼装成一张完整的图。这样就可以在保证 GraphQL 能力的同时,各个团队能够互不干扰、高效开发。
我们再来看一看 Federation 的样例,最终对外提供的能力还是商品和订单的查询,效果与前面的 demo 一致,但是系统中原来的单体服务被拆分成了三个,一个网关,一个商品服务,一个订单服务,这三个服务的开发迭代互不影响。
这里有个问题我们需要关注一下,在 gateway 的定义代码中,我们可以看到子服务列表是写死的。
import { Module } from '@nestjs/common';
import { GraphQLGatewayModule } from '@nestjs/graphql';
const graphqlGatewayModule = GraphQLGatewayModule.forRootAsync({
useFactory: async () => ({
server: {
path: '/graphql',
},
gateway: {
serviceList: [
{
name: 'goods',
url: '//localhost:3001/goods/graphql',
},
{
name: 'order',
url: '//localhost:3002/order/graphql',
},
],
},
}),
});
如果新增一个服务,就需要修改网关代码并重新发布,十分不便。我们需要一个自动化的服务注册机制。
Schema 集成系统
Apollo Federation 本身提供了一个 Schema 集成系统,其架构如下:
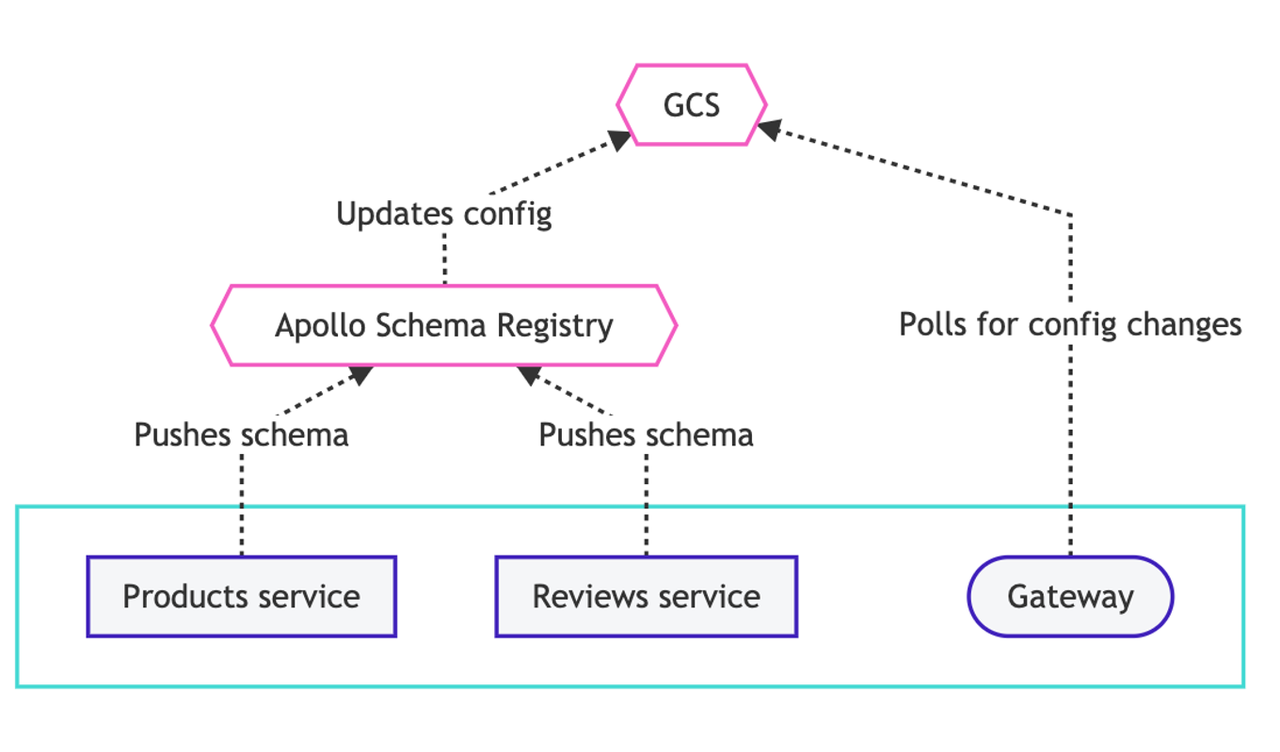
子服务将 schema 推送到 Apollo 官方的 registry 中,然后 registry 会将最新的信息推送给一个远端服务。网关再从这个远端服务通过轮询的方式拉取配置。
因此,我们仿照这个架构,设计开发了我们自己的 schema 集成系统。
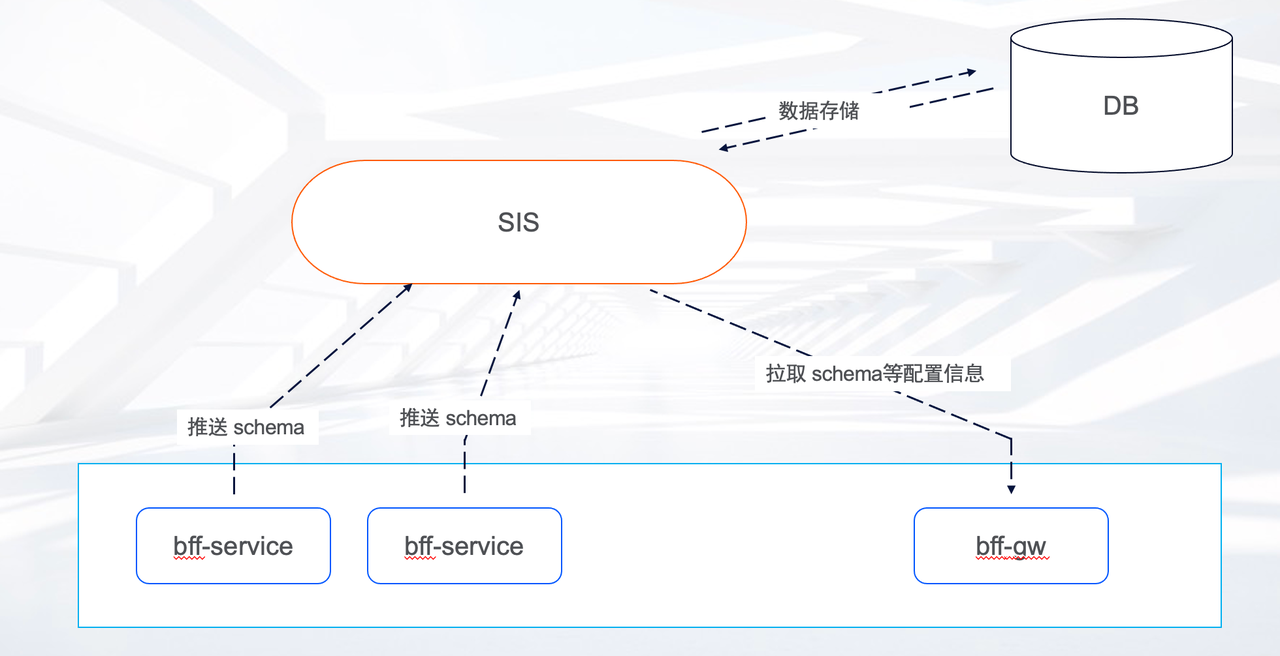
效果类似,子服务将各自的 schema 推送给 SIS(Schema Integration System),SIS 在完成必要的校验以后,生成最新的有效配置信息,网关再通过轮询的方式将配置信息拉取到本地,动态更新。
实现网关的动态更新,依赖了一个内部 API,还处于实验阶段,需要持续关注后面官方的迭代计划。
基础设施建设
经过不断的迭代,整个 BFF 层已经形成了一套解决方案,周边有着完善的基础设施建设。
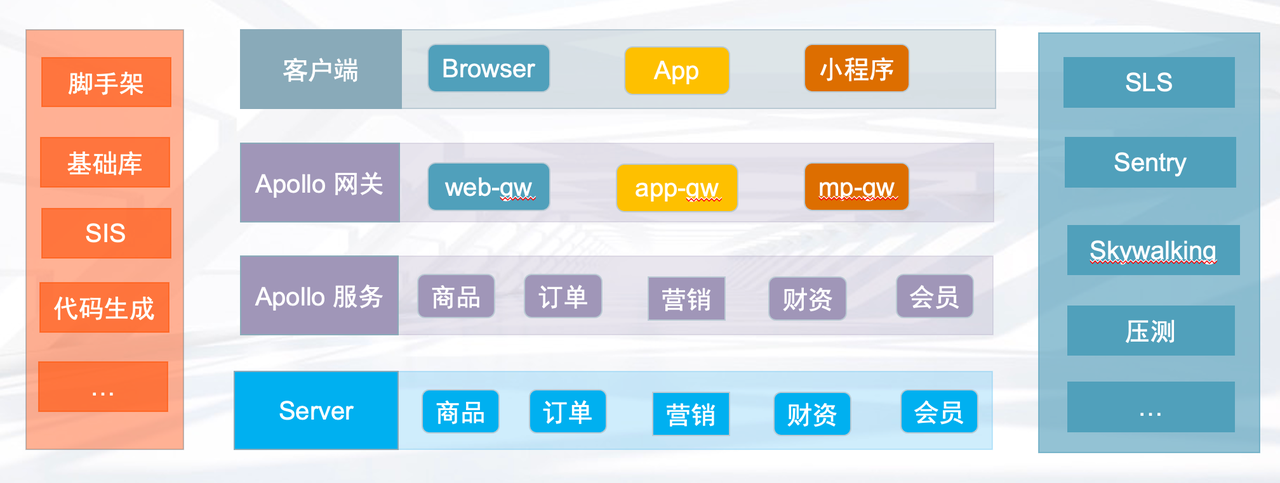
左边一栏属于开发阶段的基建,有项目脚手架、代码自动生成工具等提效工具。右边一栏属于运维阶段的基建,有阿里云 SLS 日志系统、Sentry 错误告警系统、Skywalking 链路监控系统等。
反思
前端来构建 BFF 层,通过引入 GraphQL 来解决数据聚合裁剪的问题,整个项目经过了多轮的迭代和演进,功能越来越完善,协作效率越来越高。
随着 BFF 层的展开,对前端的要求也越来越高,虽然是使用 JavaScript,但因为是完全的服务端开发,前端需要学习很多服务端开发的基础技能,同时思维方式也需要转变,从数据的消费方转变成数据的生产方,需要考虑向后兼容等一系列问题。
当然我们可以通过一系列的工程手段降低这些隐形成本,但是长远看,前端同学的服务端开发能力、运维能力还是必不可少的。
总结和展望
本文介绍了利用 GraphQL 来做数据聚合裁剪的 BFF 实践经验。从最初的单体服务到后面的服务拆分,经过了多轮的迭代演进,以及不断完善的周边基础设施,整个 BFF 最终形成了一个比较完善的解决方案。同时,BFF 也带来了如何快速构建服务端开发能力等新的问题和挑战。
正如文章开头所说,不同的业务场景,不同的开发团队都会导致 BFF 的技术选择和实践形式的不同。技术手段取决于业务场景和目标。适合自己的才是最好的。
 关注微信公众号,获取最新推送~
关注微信公众号,获取最新推送~
 加微信,深入交流~
加微信,深入交流~


