ADT基础(三)—— HashMap
ADT基础(三)—— HashMap
1 哈希表
- 哈希表(hash table),也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表。
- 在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下(后面会探讨下哈希冲突的情况),仅需一次定位即可完成,时间复杂度为O(1)。
- 存储位置 = f(关键字) ,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。好的哈希函数会尽可能地保证计算简单和散列地址分布均匀。
- 插入操作,利用哈希函数计算存储位置存入。
- 查找同理,通过哈希函数计算实际存储地址,然后从数组对应地址取出即可。
2 哈希冲突
- 如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办
- 当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。
- 哈希冲突的解决方案有多种:
- 开放定址法(发生冲突,继续寻找下一块未被占用的存储地址)
- 再散列函数法
- 链地址法(HashMap采用),也就是数组+链表的方式。
3 HashMap的实现原理
-
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构 int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算 }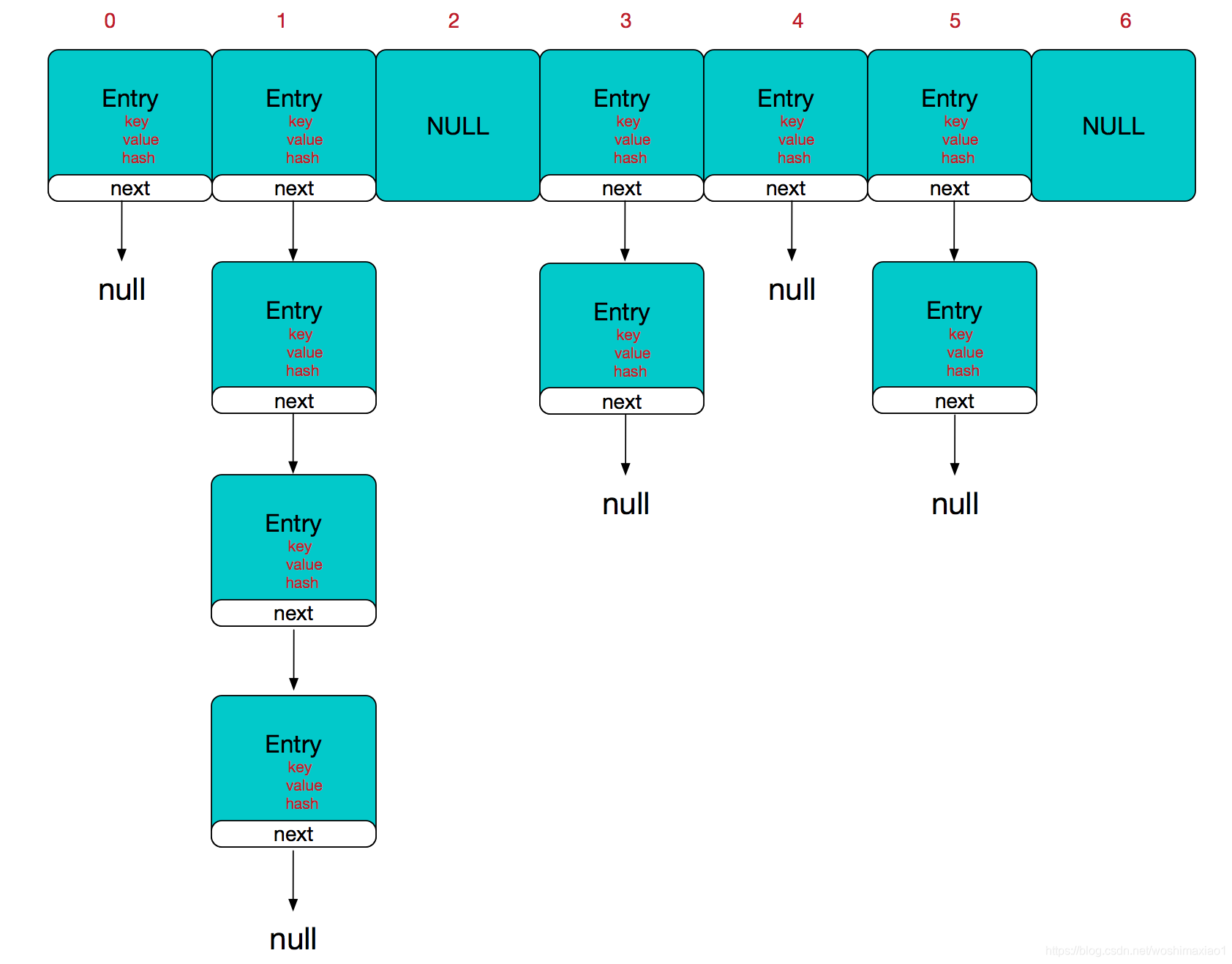
- 简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。
- 如果定位到的数组位置不含链表(当前entry的next指向null),那么查找,添加等操作很快,仅需一次寻址即可
- 如果定位到的数组包含链表。
- 对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;
- 对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
- 其他内容,如put,get原理下次补充,参考博文
- 简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。

4 HashMap使用
Map< String, String> map = new HashMap<>();
map.put("aa", "@sohu.com");
map.put("bb","@163.com"); //map.put(k,v);
value = map.get("bb"); //map.get(key);
//通过Map.keySet遍历
for (String key : map.keySet()) value = map.get(key);
//通过Map.entrySet遍历
for(Map.Entry<String, String> entry : map.entrySet()){
entry.getKey();
entry.getValue());
}
//通过Map.values()遍历所有的value
for(String v : map.values()) v;


