跟我学SpringCloud | 第十五篇:微服务利剑之APM平台(一)Skywalking
- 2019 年 10 月 3 日
- 笔记
目录

SpringCloud系列教程 | 第十五篇:微服务利剑之APM平台(一)Skywalking
Springboot: 2.1.7.RELEASE
SpringCloud: Greenwich.SR2
1. Skywalking概述
Skywalking与2016年11月2日由国人吴晟在Github上传v1.0版本,用于提供分布式链路追踪功能,从5.x开始,成为一个功能较为完善的APM(Application Performance Management)系统,2019年4月17日从Apache孵化器毕业,正式成为Apache顶级项目。提供分布式追踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。官方对自己介绍是专为微服务,云原生和基于容器(Docker,Kubernetes,Mesos)架构而设计。
2. Skywalking主要功能
- 服务,服务实例,端点指标分析
- 根本原因分析
- 服务拓扑图分析
- 服务,服务实例和端点依赖性分析
- 慢服务检测
- 性能优化
- 分布式跟踪和上下文传播
- 数据库访问指标、检测慢速数据库访问语句(包括SQL)
- 告警
3. Skywalking主要特性
- 多种监控手段,语言探针和service mesh
- 多语言自动探针,Java,.NET Core和Node.JS
- 多种后端存储支持
- 轻量高效
- 模块化,UI、存储、集群管理多种机制可选
- 支持告警
- 优秀的可视化方案
4. Skywalking架构简介
先看一下官方提供的架构图,如图:
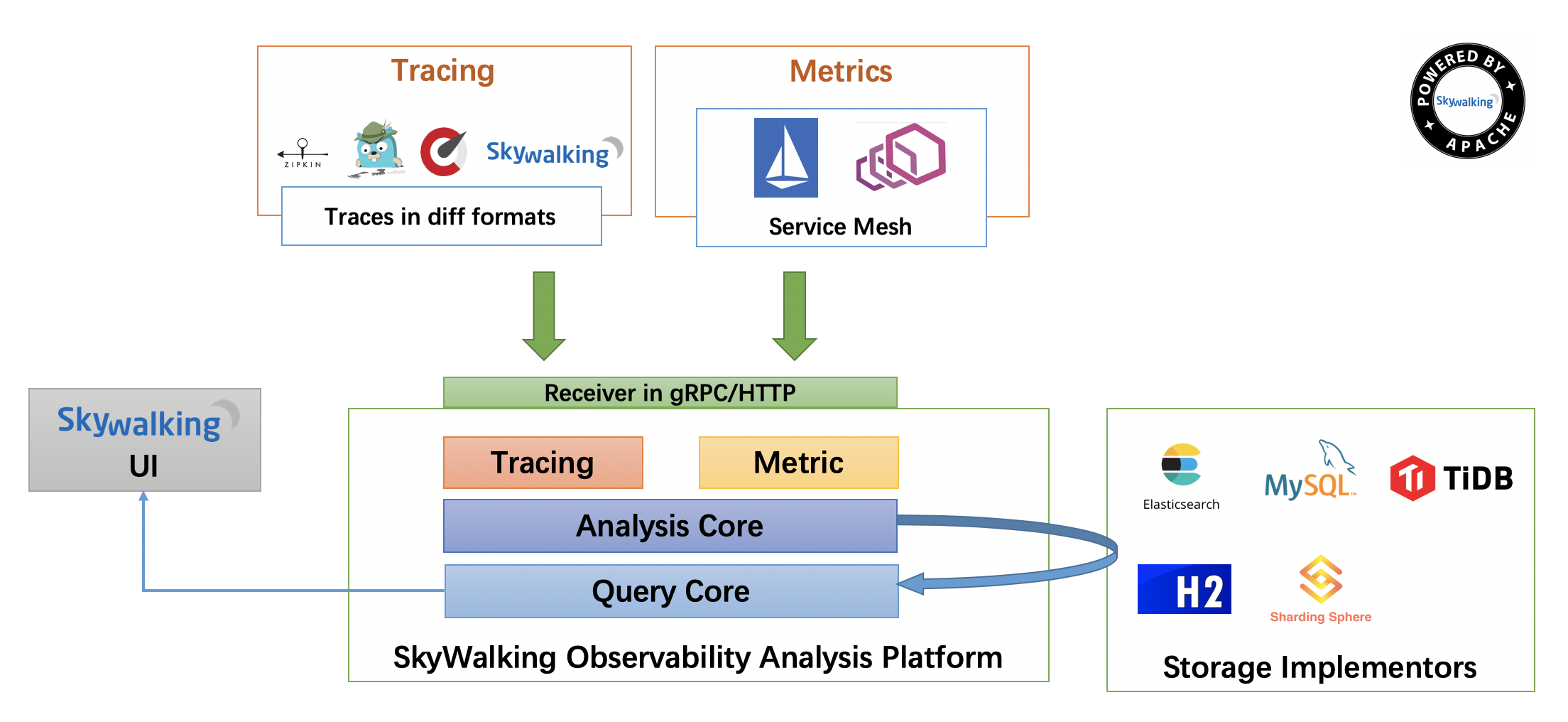
Skywalking总体由四个部分agent、collector、webapp-ui、storage组成。图10-11从上到下是应用层接入,可以使用无入侵性的agent探针接入,通过HTTP或者gRPC讲数据发送至Skywalking分析平台collector,collector对接受到的数据进行聚合分析,最后存储至storage中,这里支持多种存储方式,比较常用的有H2和ElasticSearch,最后可以由webapp-ui对所有的数据进行展示。
5. Spring Cloud与Skywalking实战
5.1 Skywalking部署构建
在介绍实战之前,我们先简单介绍一下Skywalking部署构建方案。
这里存储方式笔者选择使用ElasticSearch,具体版本是6.5.0,ElasticSearch的构建方式选择使用Docker,直接使用Linux搭建有点复杂,不适合初学者,使用Docker构建简单方便。
笔者构建的一些前置条件:
java:1.8
CentOS:7.6
如果当前CentOS上没有Docker环境,可以使用下面的语句快速构建:
yum install docker当构建成功后,可以使用下面的语句查看当前Docker的版本:
docker -v笔者这里的输出是:
Docker version 1.13.1, build 7f2769b/1.13.1安装好Docker以后,最好配置一下国内的镜像站,否则在网络不好的情况下可能出现Docker下载失败等情况,可以使用下面的语句来修改镜像地址:
vi /etc/docker/daemon.json笔者这里使用的是阿里云的镜像加速,如下:
{ "registry-mirrors": ["https://xxxxxx.mirror.aliyuncs.com"] }各位读者可以自己去阿里云上开通自己的镜像加速,具体不多做介绍。
使用Docker构建ElasticSearch6.5.0,首先,需要下载ElasticSearch6.5.0的镜像,输入以下命令:
docker pull elasticsearch:6.5.0等待程序下载完成,完成后就可以启动镜像了,命令如下:
docker run -d --restart=always --name es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:6.5.0ElasticSearch的默认启动内存是1g,如果当前服务器的内存不足1g,可以使用参数-e ES_JAVA_OPTS="-Xms256m -Xmx256m"限制ElasticSearch的启动内存大小,完整的语句如下:
docker run -d --restart=always -e ES_JAVA_OPTS="-Xms256m -Xmx256m" --name es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:6.5.0启动成功以后可以使用如下语句看一下是否启动成功:
docker ps结果如图:

ElasticSearch6.5.0单节点版已经构建完成,为了方便后续操作,需要修改一个ElasticSearch的命名,输入命令docker exec -it es /bin/bash进入容器文件目录,输入vi config/elasticsearch.yml进入ElasticSearch配置文件,修改cluster.name的值,笔者这里修改为CollectorDBCluster,修改完成后,保存当前修改,输入exit退出容器文件目录,输入docker restart es重启当前容器,在浏览器输入http://192.168.44.128:9200/,看到如下信息可以证明ElasticSearch6.5.0单节点版已经在正常的运行了。
{ "name" : "V-N2_ZQ", "cluster_name" : "CollectorDBCluster", "cluster_uuid" : "r9bFZ90WRyqSpMz80u61Yg", "version" : { "number" : "6.5.0", "build_flavor" : "default", "build_type" : "tar", "build_hash" : "816e6f6", "build_date" : "2018-11-09T18:58:36.352602Z", "build_snapshot" : false, "lucene_version" : "7.5.0", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" }Skywalking构建,进入Skywalking官网,进入下载页面(http://skywalking.apache.org/downloads/ ),如图:
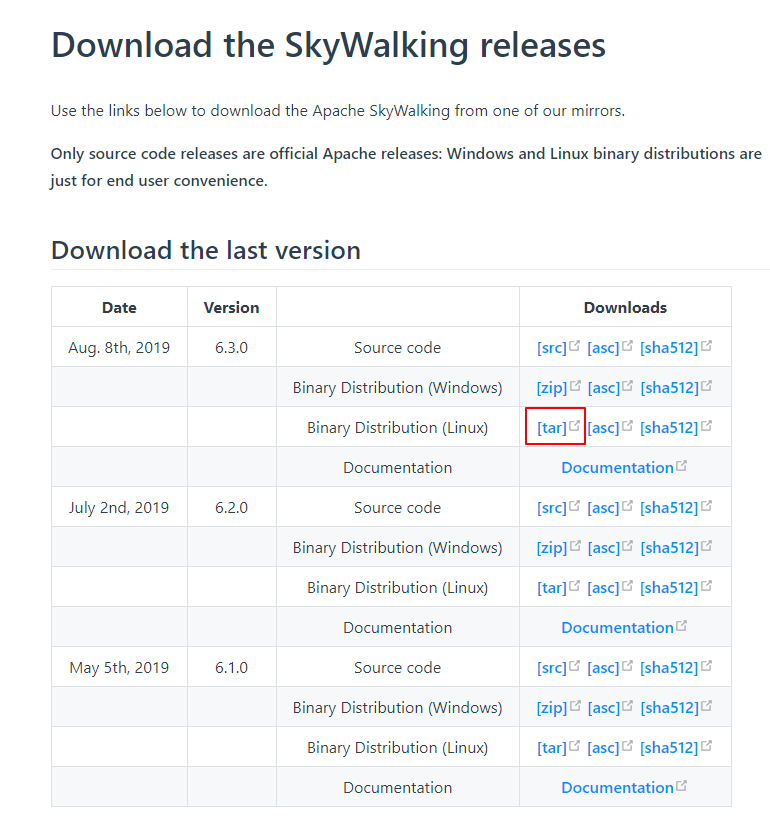
因为我们是要在CentOS上运行,所以这里选择Linux二进制版,就是已经编译好的版本,无需我们自己编译,下载至我们的CentOS后,解压可以看到目录结构,如图:

- agent:探针相关,后面会做更加详细的介绍。
- bin:这里放的是oapService和webappService的启动脚本,当然也有执行两个脚本的合并脚本
startup.sh。 - config:这里主要存放的是collector的配置信息,我们需要修改这里的application.yml中的有关ElasticSearch的配置,如下图:
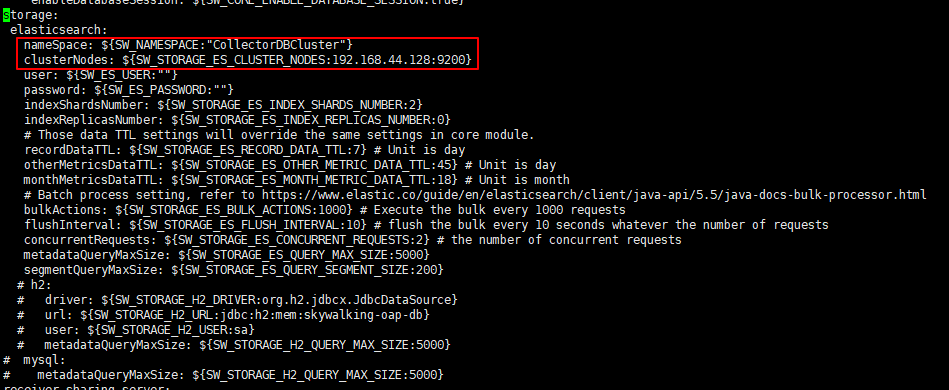
修改storage.elasticsearch.nameSpace为我们前面构建ElasticSearch设置的cluster.name,笔者这里的值为CollectorDBCluster,同时修改storage.elasticsearch.clusterNodes为我们当前构建的ElasticSearch的地址。
- logs:存放collector和webapp-ui生成的日志。
- webapp:这里存放的是Skywalking展示UI的jar和配置文件。
Skywalking中默认使用的端口有8080、11800、12800,请保证这些端口未被占用,如需修改,可以修改config目录中的application.yml和webapp目录中的webapp.yml。
接下来启动collector和webapp-ui,进入bin目录中,执行命令./startup.sh,如:

打开浏览器访问http://192.168.44.128:8080/,可以看到webapp-ui的仪表盘,如图:
Skywalking部署到这里就结束了,下面我们开始介绍Spring Cloud如何与Skywalking整合使用。
5.2 Spring Cloud整合Skywalking实战
先简单介绍一下案例内容,我们将创建4个工程,分别为Zuul-Service、Eureka-Service、Consumer-Service和Provider-Service,请求通过Zuul-Service访问至Consumer-Service再访问至Provider-Service完成一次链路调用。
整体架构图如图:
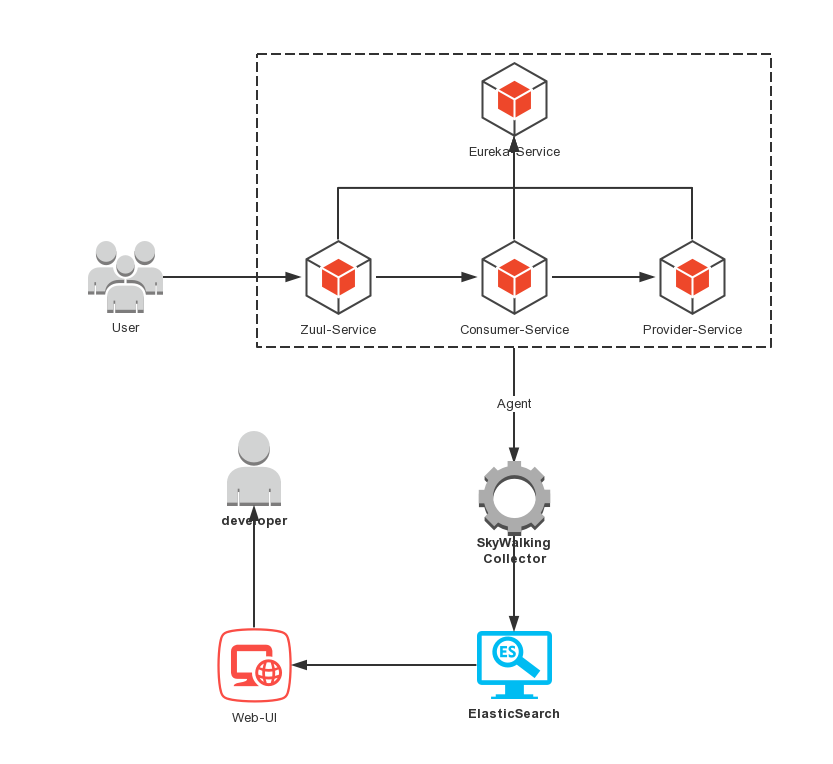
具体实现代码列出,各位读者可以参考GitHub仓库(https://github.com/meteor1993/SpringCloudLearning/tree/master/chapter15),下面我们介绍Spring Cloud是如何与Skywalking整合的。
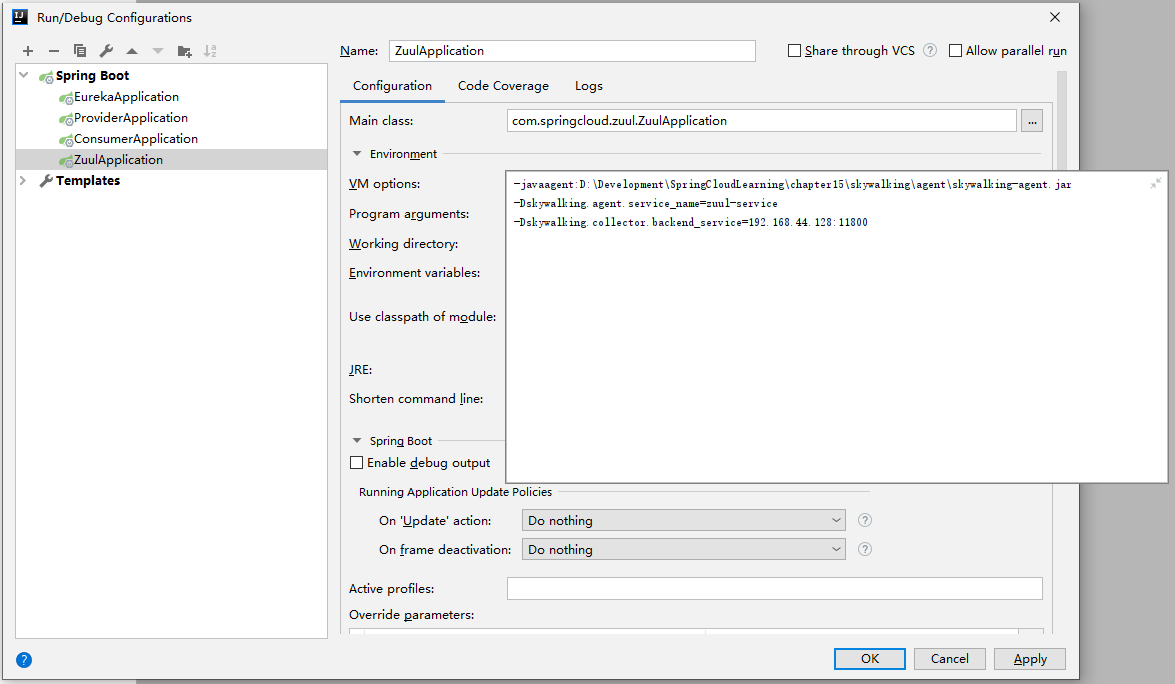
这里我们需要使用到Skywalking的探针agent,我们在工程chapter15的跟目录中新建一个文件夹,命名为skywalking,讲刚才解压的Skywalking中的agent整个文件夹copy到skywalking,这里我们启动时只需要配置javaagen命令加载agent探针即可,在idea中使用需要修改启动配置,点击右上角的Edit Configurations...,在打开的窗口中选择Environment->VM Options,配置如下脚本:
-javaagent:D:DevelopmentSpringCloudLearningchapter15skywalkingagentskywalking-agent.jar -Dskywalking.agent.service_name=zuul-service -Dskywalking.collector.backend_service=192.168.44.128:11800如图:
还可以使用java -jar的方式来加载agent探针,我们将整个maven项目打包,运行mvn install的命令,使用java -jar的方式来启动,启动命令中增加启动参数,如下:
-javaagent:D:DevelopmentSpringCloudLearningchapter15skywalkingagentskywalking-agent.jar -Dskywalking.agent.service_name=consumer-service -Dskywalking.collector.backend_service=192.168.44.128:11800 -jar zuul-0.0.1-SNAPSHOT.jar顺次启动四个工程后,使用浏览器访问:http://localhost:8080/client/hello?name=spring,多刷新几次后,我们再使用浏览器访问http://192.168.44.128:8080/,如:
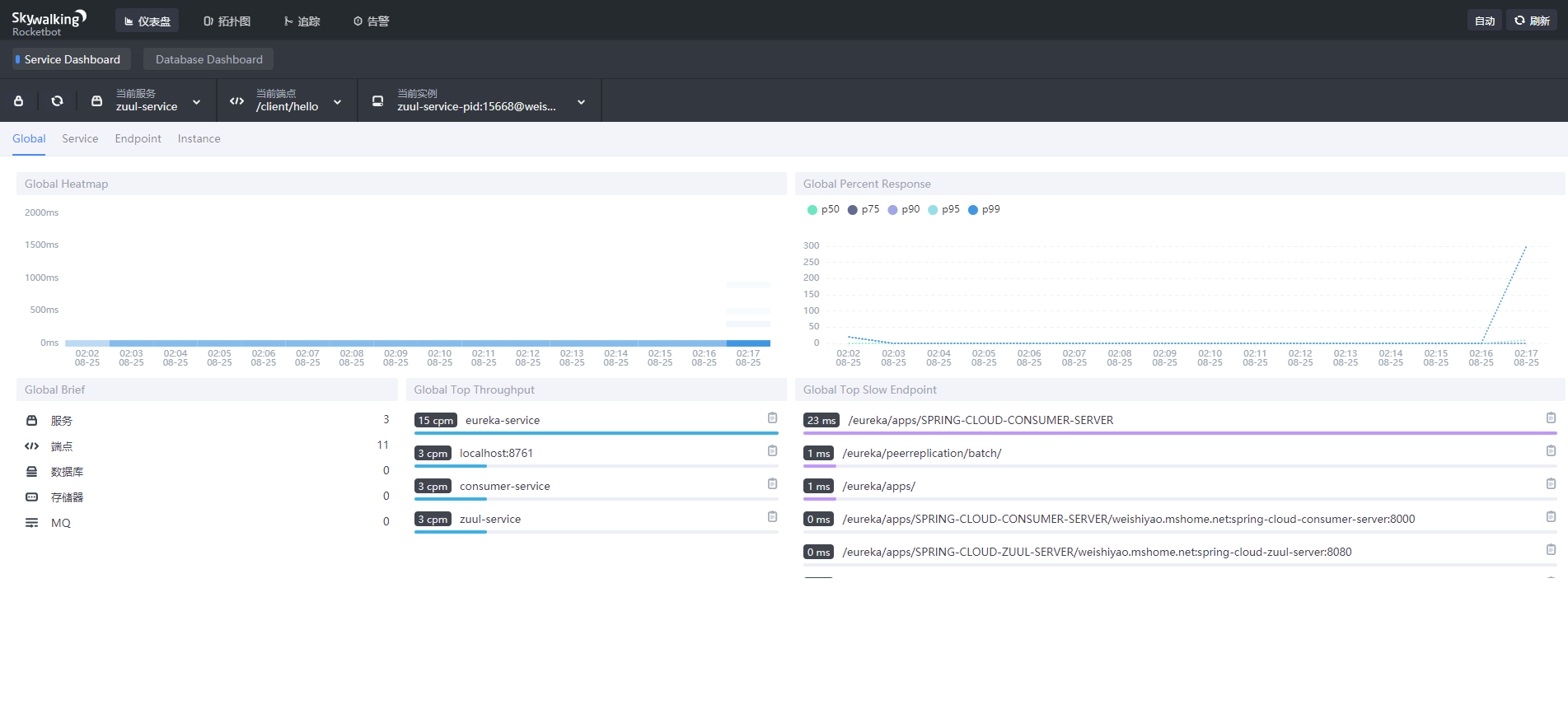
- all_heatmap:所有服务响应时间的热点图
- all_p99:所有服务响应时间的 p99 值
点击上边栏的拓扑图,可以看到当前我们工程的一个依赖拓扑关系,如:
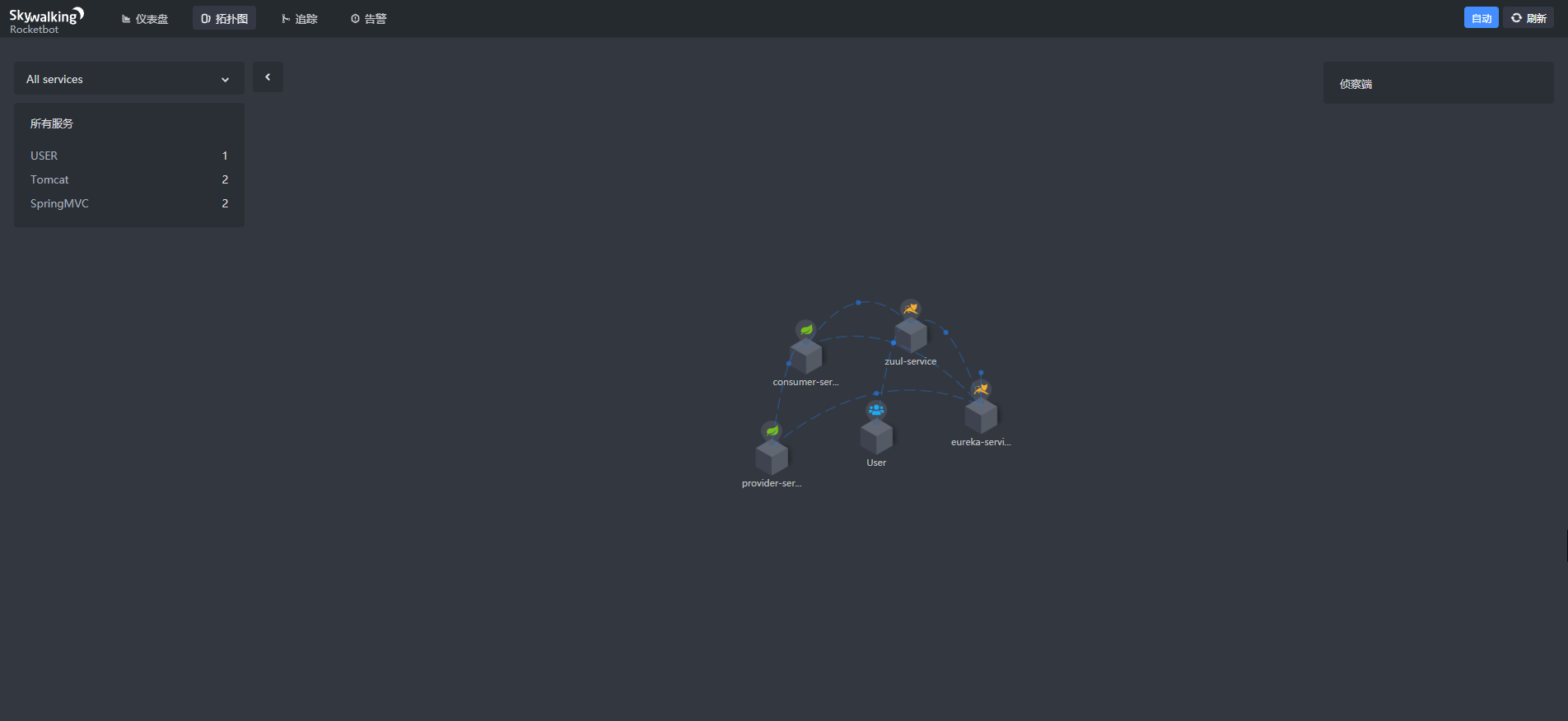
点击上边栏的追踪,可以看到左边是当前所有的访问请求,随便点击一个,可以在右边看到一个详细的链路追踪过程,如:

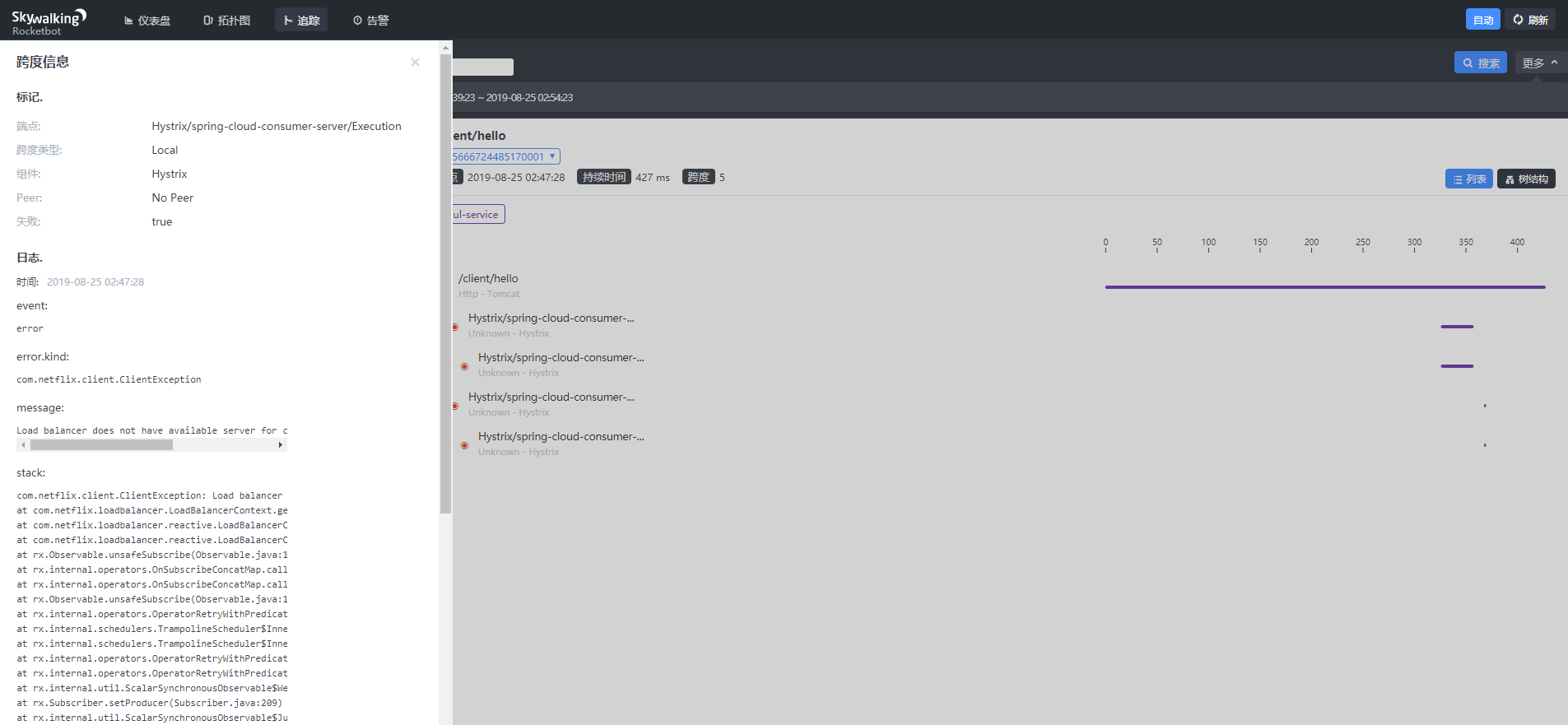
点击链路,可以看到一些标记信息,包含端点、跨度类型、成功还是失败,以及一些Exception信息,如图:
点击仪表盘页面的Service,可以看到一些服务相关的信息,如平均响应时间、平均吞吐量、平均时延统计,如图:

- service_instance_sla:服务实例的成功率
- service_instance_resp_time:服务实例的平均响应时间
- service_instance_cpm:服务实例每分钟调用次数
点击仪表盘页面的Endpoint,可以看到一些端点相关的信息,如图:
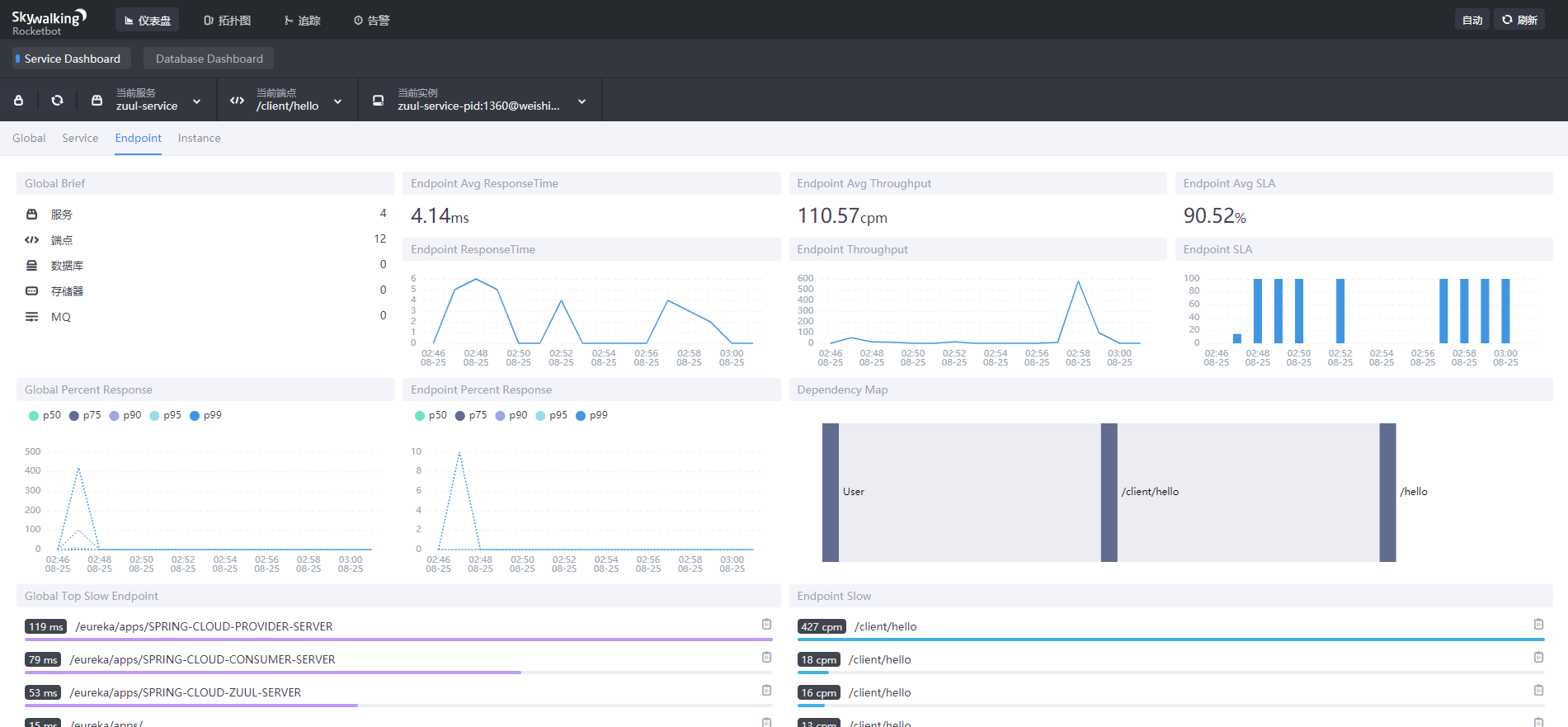
- endpoint_cpm:端点每分钟调用次数
- endpoint_avg:端点平均响应时间
- endpoint_sla:端点成功率
- endpoint_p99:端点响应时间的 p99 值
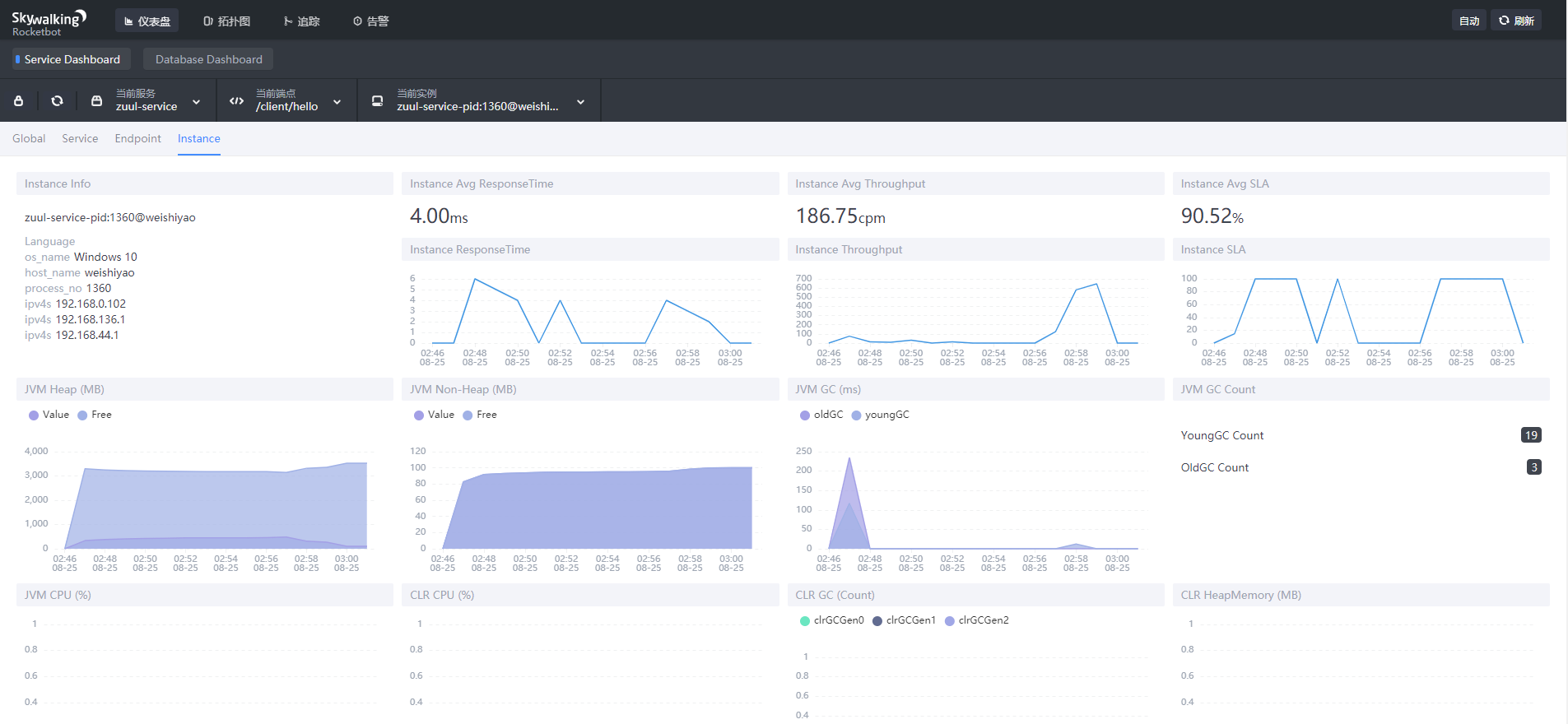
点击仪表盘页面的Instance,可以看到一些JVM相关的信息,如图:
至此,Spring Cloud与Skywalking的介绍就结束了,感兴趣的朋友可以前往Github的官方网站进行查询。
6. 小结
这里总结一下整个案例的启动顺序:
- 启动ElasticSearch
- 启动collector
- 启动web-ui(或者使用整合脚本启动)
- 启动Agent(Eureka、provider、consumer、zuul)
- 应用调用
- 访问web-ui查看统计信息
以上启动顺序供各位读者参考,请各位读者最好按照以上顺序启动,因为不同的组件之前其实是有相互依赖关系的,如果随意更改启动顺序可能会造成某些未知问题。
