缓存中间件-Redis(一)
1.Redis介绍
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的 key-value 存储系统,是跨平台的非关系型数据库,Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value)存储的非关系型数据库,常被用于分布式缓存,作为进程外的缓存,它具有以下特点:
1.方便扩展
2.大数据量高性能
3.八大数据结构
4.分布式存储
2.什么时候使用Redis
1.在分析什么场景使用Redis时,我们首先看下面的系统设计图,我们用户发起请求到达Nginx,然后由Nginx来负载均衡到不同的服务实例,服务实例去访问数据库,正常来看没什么问题,但是如果集群的单个实例是一个独立的系统,如果我们在单个系统中使用了缓存就会出现问题,具体是什么问题呢?
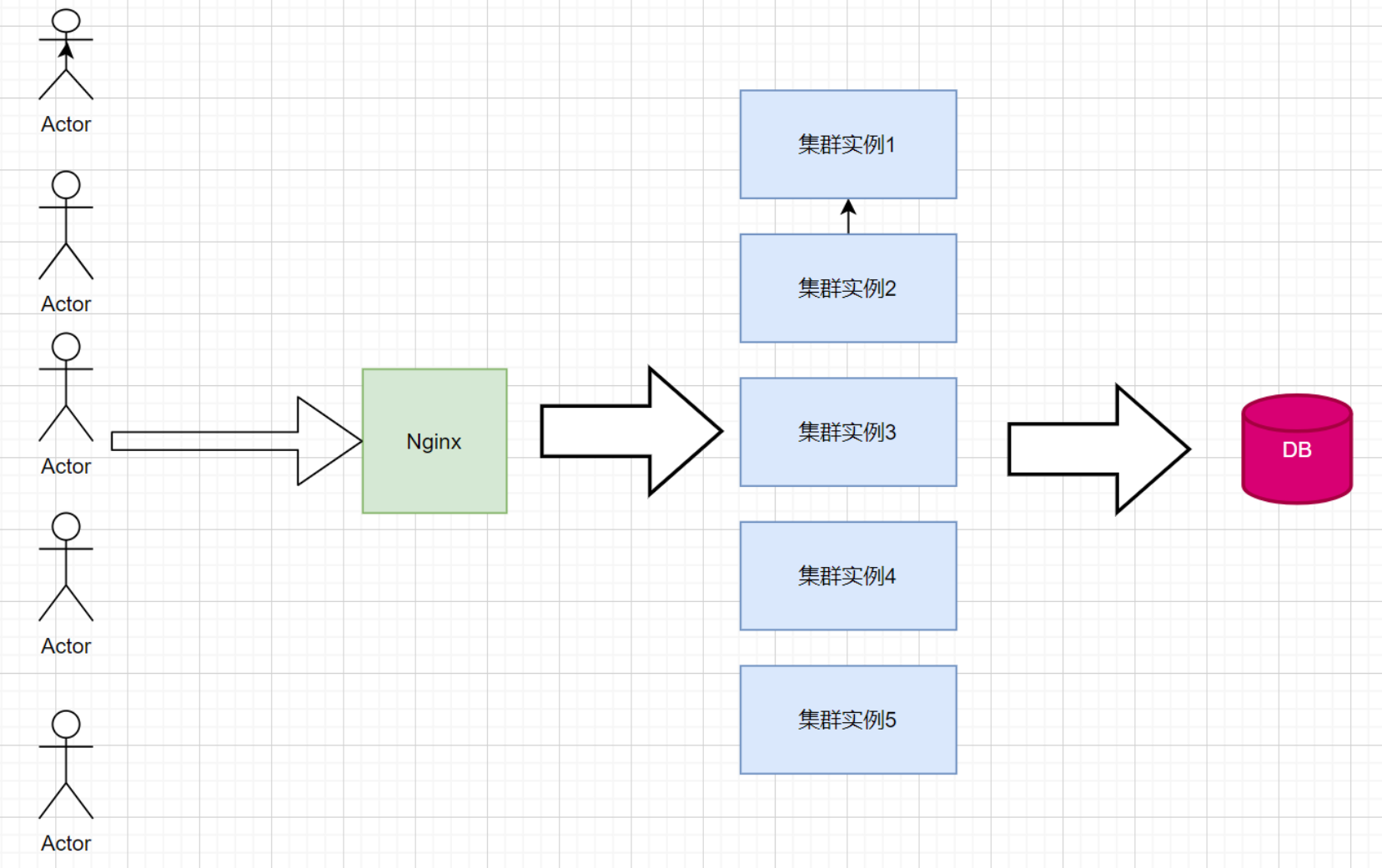
2.当用户请求被负载均衡到不同的服务器时,第一个请求被服务实例1接收,它的执行流程是查询数据库返回然后缓存,第二个用户请求同样的内容,但是被负载均衡分配到服务实例2,对于服务实例2来说这是一个全新的请求,那么又会访问数据库,对于我们来说这是很浪费的,当然在正常请求比较少造成的影响不大,但是如果请求并发较高,缓存的命中几率被放大,导致请求直接访问数据库造成阻塞,影响系统可用性。
同理我们可以这样理解,我们为了服务器更好的承载,加入了更多的服务实例,那么组成集群的单个实例越多,与缓存命中率是成反比的,当然我们可以在负载均衡时使用一些措施,使用iphash,来将某一客户端的访问与固定单个实例绑定,但是比较局限,不够灵活,那么应该怎么去更好的解决这个问题呢?
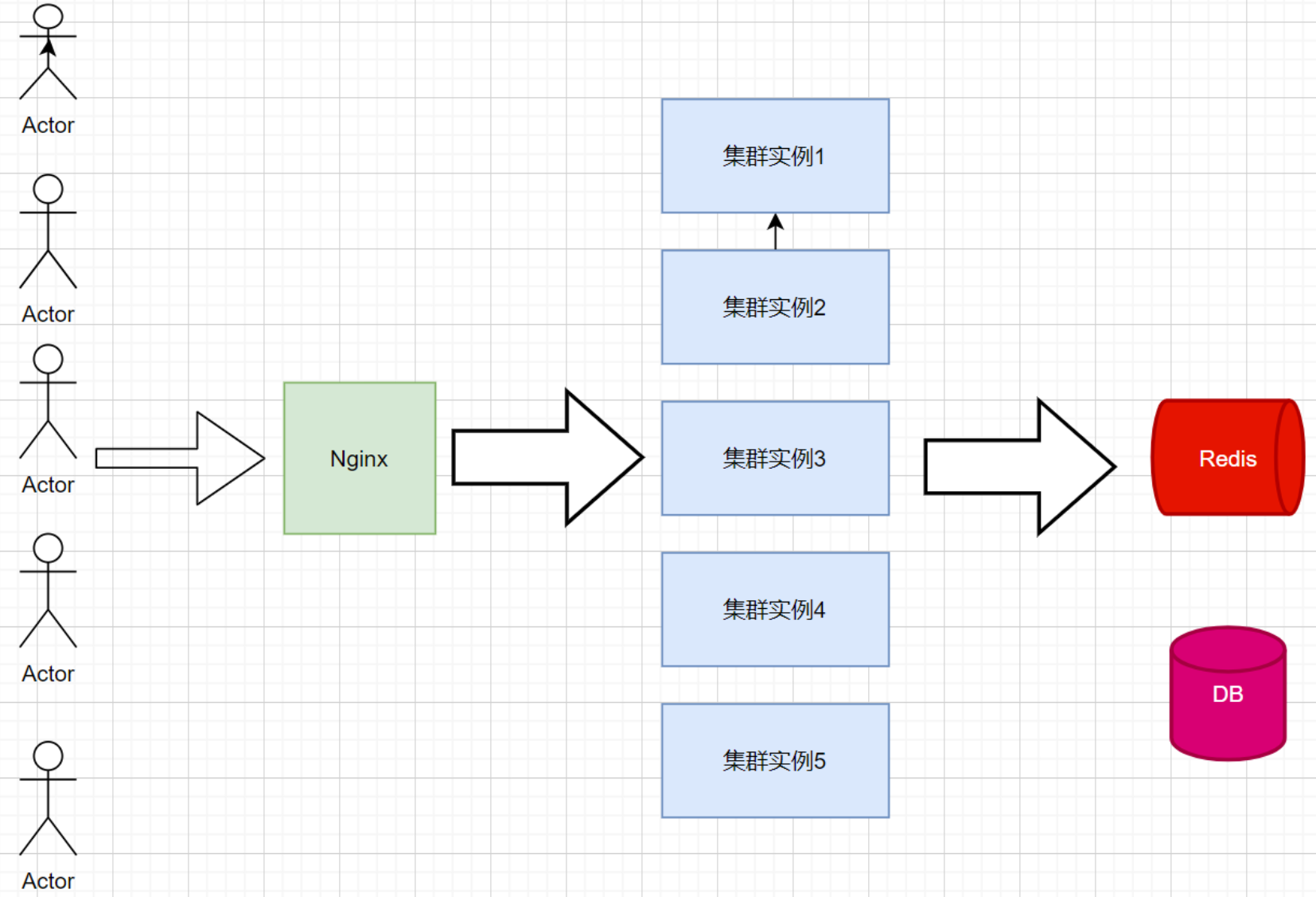
此时我们尝试在上述的架构图中加入Redis,利用Redis的读写高性能的特点,来做统一的缓存,用于降低数据库的压力以及保证系统高可用,因为从读写速度而言CPU > 内存 > 磁盘
3.Redis通信原理
1.单线程和多线程对比
1.单线程原子性操,一个线程做一个任务,不需要锁也不需要线程的上下文的切换。
2.多线程要实现原子性,涉及到各种锁,上下文的切换性能的消耗。
3.单线程多进程 ,可以根据我们的服务,开启多个实例。
2.IO多路复用
多路复用的概念就是多个IO复用一个线程处理,简单的意思是在一个操作里同时监听多个输入输出源,它和我们的异步区别就是,前者是轮训等待任务执行完成拿到结果,而后者则是在任务执行的过程中,自己去执行其他的任务,在不同的操作系统对多路复用有不同的实现,例如Windows内核中实现根据Select 而LInux内核中的实现是Epoll接下来我们简单介绍下他们2种的区别。
Select
用户请求到达内核,内核将请求封装成一个句柄描述,放入本地消息队列,然后循环队列中的所有句柄,判断是否处理完成,如果完成待所有的循环走完后,就将请求转发到用户进程,但是会随着连接数增大,性能下降,处理数据太大的话,性能很差。
Epoll
用户请求到达内核,内核将请求封装成一个句柄描述和时间回调,放入本地消息队列,待处理完毕就会触发事件,不用去循环队列中的所有消息,内核再将请求转发到用户进程,随着连接数增大,性能基本没影响,适合并发强度大的场景.
4.基本数据结构
在实际过程中,我们利用Stackexchange.Redis来进行操作.Net与Redis的互操作,当然也可以使用Servicestack.Redis他也同样可以实现交互。
1.web中安装和配置环境
1.创建Net6
WebApi项目,并且NuGet下载StackExchange.Redis最新版安装到项目中。
2.扩展Redis客户端初始化连接,并且在Startup中添加到
IOC容器
//扩展连接客户端
public static class RedisServiceCollectionExtensions
{
public static IServiceCollection AddRedisCache(this IServiceCollection services, string connectionString)
{
ConfigurationOptions configuration = ConfigurationOptions.Parse(connectionString);
ConnectionMultiplexer connectionMultiplexer = ConnectionMultiplexer.Connect(connectionString);
services.AddSingleton(connectionMultiplexer);
return services;
}
}
//注入容器
services.AddRedisCache("127.0.0.1:6379,password=xxx,connectTimeout=2000");
3.在Api中创建RedisController控制器,并注入ConnectionMultiplexer
public class RedisController : ControllerBase
{
private readonly ConnectionMultiplexer _connectionMultiplexer;
private readonly IDatabase db;
public RedisController(ConnectionMultiplexer connectionMultiplexer)
{
_connectionMultiplexer = connectionMultiplexer;
db = _connectionMultiplexer.GetDatabase(0);
}
}
2.string类型
1.
string类型数据时Redis中最基础的类型,其他类型在此基础上构建.
2.
string类型不仅仅会开辟占有的空间,还会预留一部分空间,最大能存储 512MB,可以是简单的Key,value,也可以是复杂的xml/json的字符串、二进制图像或者音频的字符串、以及可以是数字的字符串。
TestData testData = new TestData();
//首先序列化
string json = JsonConvert.SerializeObject(entity);
//设置30秒后失效
db.StringSet("TestData", demojson,TimeSpan.FromSeconds(30));
3.Set 集合
1.redis集合(set)类型和list列表类型类似,都可以用来存储多个字符串元素的集合
2.和list不同的是set集合当中
不允许重复的元素。而且set集合当中元素是没有顺序的,不存在元素下标,intzset 最大存储2的64次方,或者内容超过512个字节就使用HashTable
3.Redis中的
Set数据结构它由数组和 HashTable组成,每一个数组值都经过hash计算,支持集合内的增删改查,并且支持多个集合间的交集、并集、差集操作
RedisValue[] values = db.SetMembers("testdatas");
List<TestData> data = new List<TestData>();
if (values.Length == 0)
{
// 2、从数据库中查询
data = testData.Add();
// 3、存储到redis中
List<RedisValue> redisValues = new List<RedisValue>();
foreach (var item in data)
{
string json = JsonConvert.SerializeObject(item);//序列化
redisValues.Add(json);
}
db.SetAdd("testdatas", redisValues.ToArray());
return data;
}
// 4、序列化,反序列化
foreach (var redisValue in values)
{
TestData t = JsonConvert.DeserializeObject<TestData>(redisValue);//反序列化
data.Add(t);
}
4.hash
1.Redis hash数据结构 是一个键值对(key-value)集合,它是一个 string 类型的 field 和 value 的映射表。
2.hash数据结构相当于在value中又套了一层key-value型数据。
//根据HashKey获取字段为AccessTime 的值
string time =db.HashGet("HashKey", "AccessTime");
if (string.IsNullOrEmpty(time))
{
test = data.FirstOrDefault(s => s.Id == 1);
//设置HashKey为AccessTime字段的值
db.HashSet("HashKey", "AccessTime", test.AccessTime);
}
// 次数加1
db.HashIncrement("HashKey", "AccessTime");
5.ZSet (有序集合)
1.它的实现是由Zskiplist+HashTable
2.redis有序集合也是集合类型的一部分,它保留了集合中元素不能重复的特性,但是不同的是,有序集合给每个元素多设置了一个分数,利用该分数作为排序的依据。
6.List
1.list类型是用来存储多个有序的字符串的,列表当中的每一个字符看做一个元素.
2.一个列表当中可以存储有一个或者多个元素,redis的list支持存储2^32次方-1个元素。
3.redis可以从列表的两端进行插入(pubsh)和弹出(pop)元素,支持读取指定范围的元素集,
或者读取指定下标的元素等操作。redis列表是一种比较灵活的链表数据结构,它可以充当队列或者栈的角色
4.reids的链表结构,可以轻松实现阻塞队列,可以使用左进右出的命令组成来完成队列的设计。比如:数据的生产者可以通过Lpush命令从左边插入数据,多个数据消费者,可以使用BRpop命令阻塞的“抢”列表尾部的数据。
7.事务操作
1.Redis中
不支持事务回滚
2.在sqlserver中如果开启事务,修改数据,如果新的会话去同时操作会等待释放锁,而Redis中,在开启事务前首先监听了Key的版本号,如果在事务期间,新的会话可以修改目标Key,但是会影响当前事务提交不成功。
ITransaction transaction = db.CreateTransaction();
//执行操作
transaction.HashSetAsync("HashKey", "AccessTime", test.AccessTime);
bool commit = transaction.Execute();
if (commit)
{
Console.WriteLine("提交成功");
}
else
{
Console.WriteLine("提交失败");
}
5.Redis持久化
1.RDB 快照
RDB是Redis用来进行持久化的一种方式,是把当前内存中的数据集快照写入磁盘,恢复时是将快照文件直接读到内存里,持久化的RDB文件可以拷贝到不通过的服务,将数据
加载。
-
1.
bgsave:父进程启动一个子进程,由子进程将内存保存在硬盘文件,期间不会影响其他的指令操作. -
2.
save:将内存数据镜像保存为RDB文件,由于redis是单线程模型期间会阻塞redis服务进程,redis服务不再处理任何指令,直到RDB文件创建完成. -
无论是
bgsave还是save,其过程如下:
1.生成临时rdb文件,并写入数据.
2.完成数据写入,用临时文代替代正式rdb文件.
3.删除原来的db文件
save 900 1 #15分钟内有一条数据被修改则保存
save 300 10 #300秒有10条修改则保存
save 60 10000 #60秒内有10000条数据修改则保存
# 是否压缩rdb文件
rdbcompression yes
# rdb文件的名称
dbfilename redis-6379.rdb
# rdb文件保存目录
dir ~/redis
自动触发备份原理
1.Redis有一个周期性操作函数,默认每隔100ms执行一次,它的其中一项工作就是检查自动触发Bgsave命令的条件是否成立.
2.计数器记录了在上一次成功的持久化后,redis进行了多少次写操作,其值在每次写操作之后都加1,在成功完成持久化后清零.
RDB的优点
- 与AOF方式相比,通过rdb文件恢复数据比较快。
- rdb文件非常紧凑,适合于数据备份。
- 通过RDB进行数据备,由于使用子进程生成,所以对Redis服务器性能影响较小。
2.AOF 文件追加
Redis服务每次结束一个事件循环之前,都会调用flushAppendOnly函数,其中调用write函数将aof_buf写入文件,aof文件可以被修改。
1.开启AOF配置
# 开启aof机制
appendonly yes
# aof文件名
appendfilename "appendonly.aof"
# 写入策略,always表示每个写操作都保存到aof文件中,也可以是everysec或no
appendfsync always
# 默认不重写aof文件
no-appendfsync-on-rewrite no
# 保存目录
dir ~/redis
1.在配置文件开启将
appendonly设为yes
2.设置文件路径
dir,可以使用默认在当前目录下
3.设置追加方式一共有三种,一般选用第二种方式
- 1.appendfsync always 只要有读写,
性能最低但是安全性最高- 2.appendfsync everysec 1s钟的周期
- 3.appendfsync no 等业务不繁忙的时候,这种操作最不可靠
性能最高但是安全性最低。
2.AOF文件解读
1.打开追加的持久化文件

- 第一个指令
*2代表有2个参数,$6第一个参数6个字节为select,$1代表第二个参数0个字节 - 第二个指令
*3代表有3个参数,$3第一个参数3个字节为set,$4第2个参数4个字节为name,$3第3个参数3个字节为lll
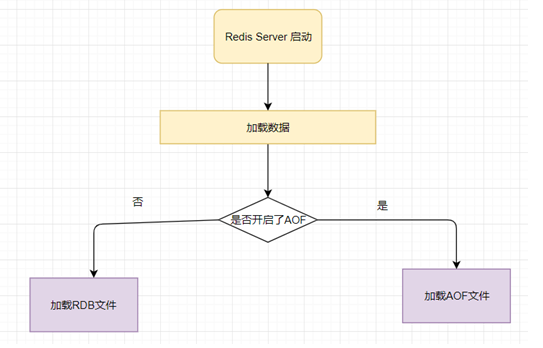
3.Redis持久化加载
上面我们介绍了Redis支持2种持久化的方式,那我们需要判断在加载时选择哪种方式,因为不可能同时选择2种,其实在Redis加载时会判断是否开启了AOF,如果开启了AOF就会加载AOF文件,如果没有开启,那么就会选择加载RDB文件。