mysql学习笔记-底层原理详解
- 2022 年 3 月 22 日
- 笔记
- java-数据库相关, MySQL
前言
我相信每一个程序员都避免不了和数据库打交道,其中Mysql以其轻量、开源成为当下最流行的关系型数据库。Mysql5.0以前以MyISAM作为默认存储引擎,在5.5版本以后,以InnoDB作为默认存储引擎,相比MyISAM,InnoDB完整的支持ACID事务特性,同时支持行级锁,支持事务这一特性也决定了InnoDB代替MyISAM成为主流存储引擎的一大决定性因素。
本文着重分析Mysql的创建流程以及InnoDB引擎特性,其他数据库存储引擎不在本次分享之列。
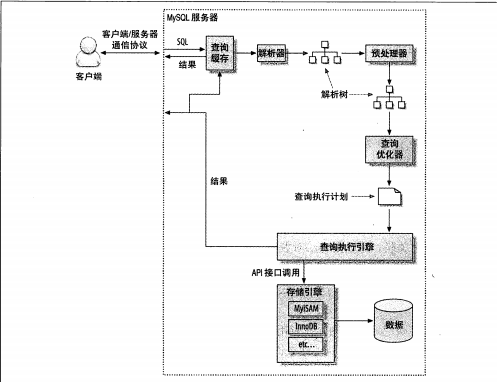
Mysql系统架构图

mysql整体包含四大部分:
连接层:包含各种组件和连接交互接口(Connectors:各种语言可以操控SQL的基础,支持各种语言)
核心层:也被称作SQL Laye,包括安全、权限、sql解析、缓存、执行优化。我们常用的视图、存储过程、触发器等功能的实现也集中在这一层
存储引擎层:也被Storage Engine Layer,由多种存储引擎共同组成,负责存储和获取数据。服务器是通过存储引擎API来与它们交互的。MySQL中的存储引擎可以实现插件式管理,它提供了一系列标准的管理和服务支持。
系统层:实际存储一些数据库文件以及日志文件等
连接层主要是一些操作sql的组件,例如Java中的JDBC(后面会有博客专门分享它)、系统层则是一些系统保存下的数据库物理文件,本文不做重点介绍,下面着重介绍下核心层和系统层
Sql执行流程图
连接层
如上图(Sql执行流程)所示,我们Sql执行首先是客户端向MySQL服务器发送一条查询请求,与connectors交互,连接池认证相关处理。
- 半双工通信:Mysql客户端/服务端通信协议是一种
半双工的通信信道,什么叫半双工呢?半双工指的是允许客户端和服务端双方相互通信,但是同一时刻只允许存在单向通信。对于查询sql来讲,大多数都是客户端发送的查询数据包较小且为单个数据包,服务端返回的数据包较大且较大时大多拆分为多个数据包,多个数据包都需要被客户端完整接收才算是查询结束,这也是为什么在实际开发中要求我们避免使用select *以及增加limlt查询条件的原因之一。 - Connectors(连接器)的职责就是维护上述过程中的连接通到,包括建立连接、权限表验证、维持连接和关闭连接。新建和关闭应该不用过多描述;权限表验证是从
user、host、db等表查出权限,放置在连接的上下文中(也就是说已经打开的链接不受权限变更影响)。维持连接则指的是Connectors需要保障完全接收服务器响应的数据包,不能出现丢包的情况。 - Connection Pool(连接池) :作为一个单进程多线程的应用,mysql连接也参照实现一种池化
对于mysql连接,任何时刻都有一个状态,该状态表示了mysql当前正在做什么。使用show full processlist命令查看当前状态。下面是这些状态的解释:
- sleep:线程正在等待客户端发送新的请求;
- query:线程正在执行查询或者正在将结果发送给客户端;
- locked:在mysql服务器层,该线程正在等待表锁。在存储引擎级别实现的锁,例如InnoDB的行锁,并不会体现在线程状态中。对于MyISAM来说这是一个比较典型的状态。
- analyzing and statistics:线程正在收集存储引擎的统计信息,并生成查询的执行计划;
- copying to tmp table:线程在执行查询,并且将其结果集复制到一个临时表中,这种状态一般要么是做group by操作,要么是文件排序操作,或者union操作。如果这个状态后面还有on disk标记,那表示mysql正在将一个内存临时表放到磁盘上。
- sorting Result:线程正在对结果集进行排序。
- sending data:线程可能在多个状态间传送数据,或者在生成结果集,或者在想客户端返回数据。
核心层
我们之前说过,核心层包括安全权限(Management Services & Utilities 、)、sql解析(Parser)、缓存(cache)、执行优化(Optimizer)四块,不过还应该再加上SQL Interface(Sql接口),这一块主要是承担和连接层的交互的作用。所以归纳而言
| 名称 | 说明 |
|---|---|
| Management Services & Utilities | MySQL 的系统管理和控制工具,包括备份恢复、MySQL 复制、集群等。 |
| SQL Interface(SQL 接口) | 用来接收用户的 SQL 命令,返回用户需要查询的结果。 |
| Parser(查询解析器) | 包含验证和解析两部分,以便可以转换为MySQL优化器可以识别的数据结构或返回 SQL 语句的错误。 |
| Optimizer(查询优化器) | 验证权限和优化查询。举个例子 SELECT id, name FROM student WHERE sex = "女";,SELECT 查询先根据 WHERE 语句进行选取,而不是将表全部查询出来以后再进行sex过滤。这就属于一种优化。SELECT 查询先根据 id 和 name 进行属性投影,而不是将属性全部取出以后再进行过滤,将这两个查询条件连接起来生成最终查询结果。所以说Mysql是使用“选取-投影-连接”策略进行查询。 |
| Caches & Buffers(查询缓存) | 查询的时候如果发现缓存中有(hash实现),就直接返回缓存中的结果。这个缓存机制是由一系列小缓存组成的,比如表缓存、记录缓存、key 缓存、权限缓存等。 |
Caches & Buffers(查询缓存)
对select查询结果做缓存,这个缓存可能包含多个小缓存,缓存的key值是通过查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息计算得来。所以两个查询在任何字符上的不同 (例如 : 空格、注释),都会导致缓存不会命中。
MySQL 8.0版本中查询缓存的功能已经被删除
Management Services & Utilities
主要为Mysql的管理服务和一些工具组件,主要作用是对数据的恢复、回滚,以及数据迁移、复制、元数据的管理。主要为以下功能
- 数据库备份和恢复
- 数据库安全管理,如用户及权限管理
- 数据库复制管理
- 数据库集群管理
- 数据库分区,分库,分表管理
- 数据库元数据管理
SQL Interface(SQL 接口)
主要是用来接收Sql信息和返回执行结果.大体可以分以下几类:
- Data Manipulation Language (DML).
- Data Definition Language (DDL).
- 存储过程
- 视图
- 触发器
Parser(查询解析器)
主要是对传递过来sql的分解,先对语法进行验证检查。语法检查通过后,解析器会查询缓存,如果缓存中有对应的语句,就直接返回结果不进行接下来的优化执行操作。
ps: 缓存中数据被修改,会被清出缓存。
Optimizer(查询优化器)
Optimizer阶段主要就是对sql的优化了,通过系统规则选定最优的执行方案。这个过程包括选择语法、常量转换与计算、无效代码排除、AND/OR等等,必要时还可能查询存储引擎,获得最优策略。
Pluggable Storage Engine(存储引擎层)
作为Mysql最具有特色的一块地方,Mysql将存储引擎作为一个抽象类,InnoDB、MyISAM、BDB、Memory等等都是其子类。5.5版本以后以InnoDB作为其默认实现。目前除mysql以外其他大多都是单一存储引擎。
ps:存储引擎是基于表的,而不是数据库
InnoDB(默认存储引擎)
- 完整的支持ACID事务
- 支持行级锁
- 支持外键
- 使用聚集索引,索引和数据绑在一起在一个逻辑空间上,b+树叶子节点对于主键索引存储的是数据,对于辅助索引(二级索引)对应的则是主键的值
- count扫全表
- 必须存在唯一索引(主键)
MyISAM
- 不支持事务,但是插入和更新更快
- 支持表级锁
- 不支持外键
- 使用非聚集索引,索引和数据分离的,b+树叶子结点均存储的是实体数据文件地址的指针
- count走变量不走全表
- 唯一索引非必要
对于存储引擎的分析在下一篇博客会着重介绍,这里先介绍整个Mysql的架构,通过架构可以反应出一个sql的执行流程
文件系统层
磁盘最小单位是512字节,操作系统是4KB,mysql里最小的是page(页面)有16K
因为基于存储引擎的不同,底层文件结构也会有些不同,比如InnoDB:frm是表定义文件,ibd是数据文件,而MyISAM:myd是数据文件,myi是索引文件。InnoDB还有redo Log、undo Log
结尾
本篇博客作为一个Mysql全局概览的介绍,由连接层自上而下的说明了整个Mysql的结构组成,但是Mysql核心还是在存储引擎上,所以后面会专门拿出一篇博文来介绍InnoDB默认引擎,巩固自己的知识点。
扫一扫,关注我的公众号



